 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReWorld: Multi-Dimensional Reward Modeling for Embodied World Models
Jan 18, 2026Recently, video-based world models that learn to simulate the dynamics have gained increasing attention in robot learning. However, current approaches primarily emphasize visual generative quality while overlooking physical fidelity, dynamic consistency, and task logic, especially for contact-rich manipulation tasks, which limits their applicability to downstream tasks. To this end, we introduce ReWorld, a framework aimed to employ reinforcement learning to align the video-based embodied world models with physical realism, task completion capability, embodiment plausibility and visual quality. Specifically, we first construct a large-scale (~235K) video preference dataset and employ it to train a hierarchical reward model designed to capture multi-dimensional reward consistent with human preferences. We further propose a practical alignment algorithm that post-trains flow-based world models using this reward through a computationally efficient PPO-style algorithm. Comprehensive experiments and theoretical analysis demonstrate that ReWorld significantly improves the physical fidelity, logical coherence, embodiment and visual quality of generated rollouts, outperforming previous methods.
DexVLG: Dexterous Vision-Language-Grasp Model at Scale
Jul 03, 2025As large models gain traction, vision-language-action (VLA) systems are enabling robots to tackle increasingly complex tasks. However, limited by the difficulty of data collection, progress has mainly focused on controlling simple gripper end-effectors. There is little research on functional grasping with large models for human-like dexterous hands. In this paper, we introduce DexVLG, a large Vision-Language-Grasp model for Dexterous grasp pose prediction aligned with language instructions using single-view RGBD input. To accomplish this, we generate a dataset of 170 million dexterous grasp poses mapped to semantic parts across 174,000 objects in simulation, paired with detailed part-level captions. This large-scale dataset, named DexGraspNet 3.0, is used to train a VLM and flow-matching-based pose head capable of producing instruction-aligned grasp poses for tabletop objects. To assess DexVLG's performance, we create benchmarks in physics-based simulations and conduct real-world experiments. Extensive testing demonstrates DexVLG's strong zero-shot generalization capabilities-achieving over 76% zero-shot execution success rate and state-of-the-art part-grasp accuracy in simulation-and successful part-aligned grasps on physical objects in real-world scenarios.
SoFar: Language-Grounded Orientation Bridges Spatial Reasoning and Object Manipulation
Feb 18, 2025


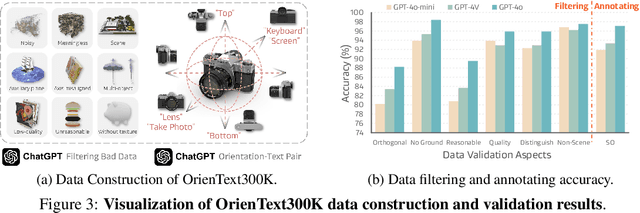
Spatial intelligence is a critical component of embodied AI, promoting robots to understand and interact with their environments. While recent advances have enhanced the ability of VLMs to perceive object locations and positional relationships, they still lack the capability to precisely understand object orientations-a key requirement for tasks involving fine-grained manipulations. Addressing this limitation not only requires geometric reasoning but also an expressive and intuitive way to represent orientation. In this context, we propose that natural language offers a more flexible representation space than canonical frames, making it particularly suitable for instruction-following robotic systems. In this paper, we introduce the concept of semantic orientation, which defines object orientations using natural language in a reference-frame-free manner (e.g., the ''plug-in'' direction of a USB or the ''handle'' direction of a knife). To support this, we construct OrienText300K, a large-scale dataset of 3D models annotated with semantic orientations that link geometric understanding to functional semantics. By integrating semantic orientation into a VLM system, we enable robots to generate manipulation actions with both positional and orientational constraints. Extensive experiments in simulation and real world demonstrate that our approach significantly enhances robotic manipulation capabilities, e.g., 48.7% accuracy on Open6DOR and 74.9% accuracy on SIMPLER.
Scene Graph Disentanglement and Composition for Generalizable Complex Image Generation
Oct 01, 2024



There has been exciting progress in generating images from natural language or layout conditions. However, these methods struggle to faithfully reproduce complex scenes due to the insufficient modeling of multiple objects and their relationships. To address this issue, we leverage the scene graph, a powerful structured representation, for complex image generation. Different from the previous works that directly use scene graphs for generation, we employ the generative capabilities of variational autoencoders and diffusion models in a generalizable manner, compositing diverse disentangled visual clues from scene graphs. Specifically, we first propose a Semantics-Layout Variational AutoEncoder (SL-VAE) to jointly derive (layouts, semantics) from the input scene graph, which allows a more diverse and reasonable generation in a one-to-many mapping. We then develop a Compositional Masked Attention (CMA) integrated with a diffusion model, incorporating (layouts, semantics) with fine-grained attributes as generation guidance. To further achieve graph manipulation while keeping the visual content consistent, we introduce a Multi-Layered Sampler (MLS) for an "isolated" image editing effect. Extensive experiments demonstrate that our method outperforms recent competitors based on text, layout, or scene graph, in terms of generation rationality and controllability.
Hierarchical Temporal Context Learning for Camera-based Semantic Scene Completion
Jul 02, 2024Camera-based 3D semantic scene completion (SSC) is pivotal for predicting complicated 3D layouts with limited 2D image observations. The existing mainstream solutions generally leverage temporal information by roughly stacking history frames to supplement the current frame, such straightforward temporal modeling inevitably diminishes valid clues and increases learning difficulty. To address this problem, we present HTCL, a novel Hierarchical Temporal Context Learning paradigm for improving camera-based semantic scene completion. The primary innovation of this work involves decomposing temporal context learning into two hierarchical steps: (a) cross-frame affinity measurement and (b) affinity-based dynamic refinement. Firstly, to separate critical relevant context from redundant information, we introduce the pattern affinity with scale-aware isolation and multiple independent learners for fine-grained contextual correspondence modeling. Subsequently, to dynamically compensate for incomplete observations, we adaptively refine the feature sampling locations based on initially identified locations with high affinity and their neighboring relevant regions. Our method ranks $1^{st}$ on the SemanticKITTI benchmark and even surpasses LiDAR-based methods in terms of mIoU on the OpenOccupancy benchmark. Our code is available on https://github.com/Arlo0o/HTCL.
Closed-Loop Unsupervised Representation Disentanglement with $β$-VAE Distillation and Diffusion Probabilistic Feedback
Feb 04, 2024Representation disentanglement may help AI fundamentally understand the real world and thus benefit both discrimination and generation tasks. It currently has at least three unresolved core issues: (i) heavy reliance on label annotation and synthetic data -- causing poor generalization on natural scenarios; (ii) heuristic/hand-craft disentangling constraints make it hard to adaptively achieve an optimal training trade-off; (iii) lacking reasonable evaluation metric, especially for the real label-free data. To address these challenges, we propose a \textbf{C}losed-\textbf{L}oop unsupervised representation \textbf{Dis}entanglement approach dubbed \textbf{CL-Dis}. Specifically, we use diffusion-based autoencoder (Diff-AE) as a backbone while resorting to $\beta$-VAE as a co-pilot to extract semantically disentangled representations. The strong generation ability of diffusion model and the good disentanglement ability of VAE model are complementary. To strengthen disentangling, VAE-latent distillation and diffusion-wise feedback are interconnected in a closed-loop system for a further mutual promotion. Then, a self-supervised \textbf{Navigation} strategy is introduced to identify interpretable semantic directions in the disentangled latent space. Finally, a new metric based on content tracking is designed to evaluate the disentanglement effect. Experiments demonstrate the superiority of CL-Dis on applications like real image manipulation and visual analysis.
Token is All You Need for Zero-Shot Semantic Segmentation
Apr 13, 2023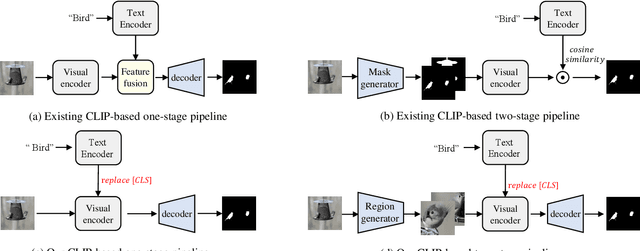
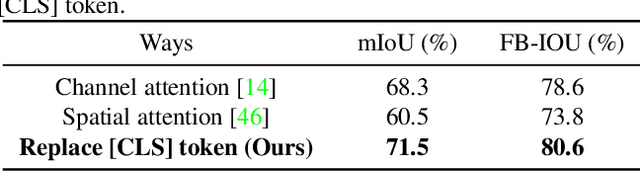
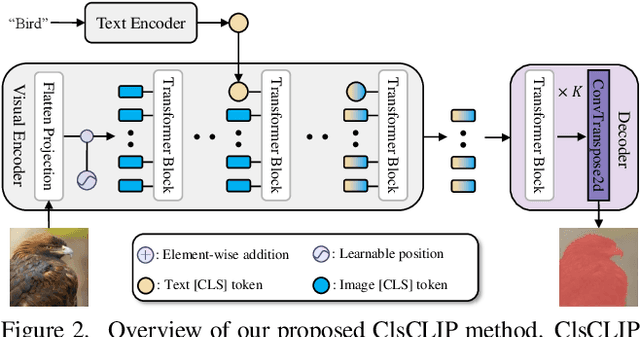
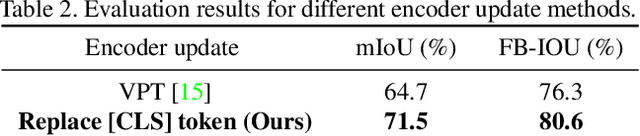
In this paper, we propose an embarrassingly simple yet highly effective zero-shot semantic segmentation (ZS3) method, based on the pre-trained vision-language model CLIP. First, our study provides a couple of key discoveries: (i) the global tokens (a.k.a [CLS] tokens in Transformer) of the text branch in CLIP provide a powerful representation of semantic information and (ii) these text-side [CLS] tokens can be regarded as category priors to guide CLIP visual encoder pay more attention on the corresponding region of interest. Based on that, we build upon the CLIP model as a backbone which we extend with a One-Way [CLS] token navigation from text to the visual branch that enables zero-shot dense prediction, dubbed \textbf{ClsCLIP}. Specifically, we use the [CLS] token output from the text branch, as an auxiliary semantic prompt, to replace the [CLS] token in shallow layers of the ViT-based visual encoder. This one-way navigation embeds such global category prior earlier and thus promotes semantic segmentation. Furthermore, to better segment tiny objects in ZS3, we further enhance ClsCLIP with a local zoom-in strategy, which employs a region proposal pre-processing and we get ClsCLIP+. Extensive experiments demonstrate that our proposed ZS3 method achieves a SOTA performance, and it is even comparable with those few-shot semantic segmentation methods.
Predict the Rover Mobility over Soft Terrain using Articulated Wheeled Bevameter
Feb 17, 2022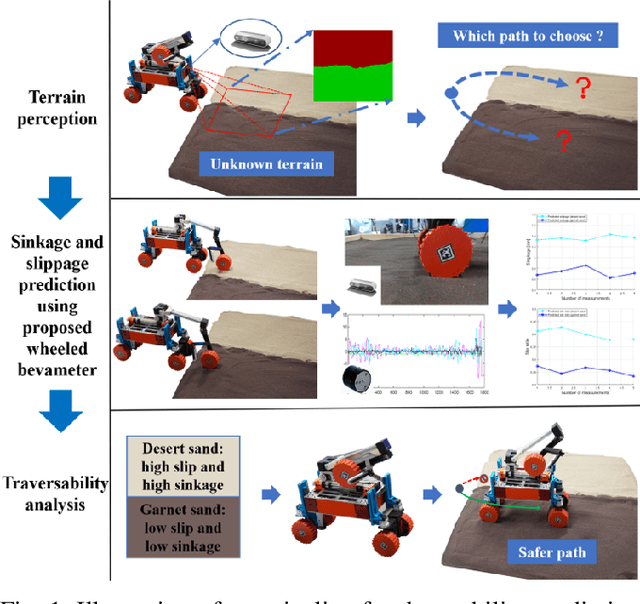
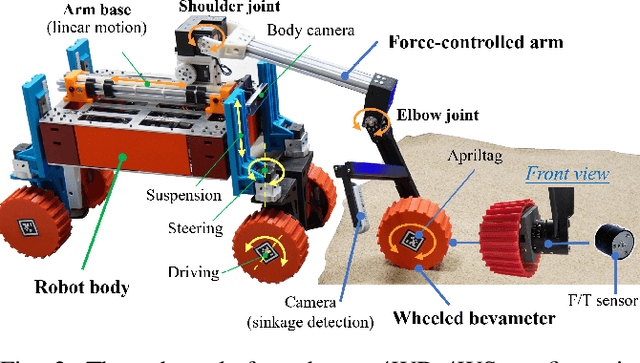
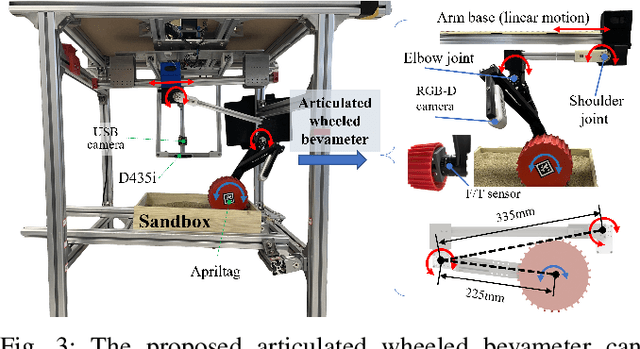

Robot mobility is critical for mission success, especially in soft or deformable terrains, where the complex wheel-soil interaction mechanics often leads to excessive wheel slip and sinkage, causing the eventual mission failure. To improve the success rate, online mobility prediction using vision, infrared imaging, or model-based stochastic methods have been used in the literature. This paper proposes an on-board mobility prediction approach using an articulated wheeled bevameter that consists of a force-controlled arm and an instrumented bevameter (with force and vision sensors) as its end-effector. The proposed bevameter, which emulates the traditional terramechanics tests such as pressure-sinkage and shear experiments, can measure contact parameters ahead of the rover's body in real-time, and predict the slip and sinkage of supporting wheels over the probed region. Based on the predicted mobility, the rover can select a safer path in order to avoid dangerous regions such as those covered with quicksand. Compared to the literature, our proposed method can avoid the complicated terramechanics modeling and time-consuming stochastic prediction; it can also mitigate the inaccuracy issues arising in non-contact vision-based methods. We also conduct multiple experiments to validate the proposed approach.