 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJMedEthicBench: A Multi-Turn Conversational Benchmark for Evaluating Medical Safety in Japanese Large Language Models
Jan 04, 2026As Large Language Models (LLMs) are increasingly deployed in healthcare field, it becomes essential to carefully evaluate their medical safety before clinical use. However, existing safety benchmarks remain predominantly English-centric, and test with only single-turn prompts despite multi-turn clinical consultations. To address these gaps, we introduce JMedEthicBench, the first multi-turn conversational benchmark for evaluating medical safety of LLMs for Japanese healthcare. Our benchmark is based on 67 guidelines from the Japan Medical Association and contains over 50,000 adversarial conversations generated using seven automatically discovered jailbreak strategies. Using a dual-LLM scoring protocol, we evaluate 27 models and find that commercial models maintain robust safety while medical-specialized models exhibit increased vulnerability. Furthermore, safety scores decline significantly across conversation turns (median: 9.5 to 5.0, $p < 0.001$). Cross-lingual evaluation on both Japanese and English versions of our benchmark reveals that medical model vulnerabilities persist across languages, indicating inherent alignment limitations rather than language-specific factors. These findings suggest that domain-specific fine-tuning may accidentally weaken safety mechanisms and that multi-turn interactions represent a distinct threat surface requiring dedicated alignment strategies.
Scene Graph Disentanglement and Composition for Generalizable Complex Image Generation
Oct 01, 2024



There has been exciting progress in generating images from natural language or layout conditions. However, these methods struggle to faithfully reproduce complex scenes due to the insufficient modeling of multiple objects and their relationships. To address this issue, we leverage the scene graph, a powerful structured representation, for complex image generation. Different from the previous works that directly use scene graphs for generation, we employ the generative capabilities of variational autoencoders and diffusion models in a generalizable manner, compositing diverse disentangled visual clues from scene graphs. Specifically, we first propose a Semantics-Layout Variational AutoEncoder (SL-VAE) to jointly derive (layouts, semantics) from the input scene graph, which allows a more diverse and reasonable generation in a one-to-many mapping. We then develop a Compositional Masked Attention (CMA) integrated with a diffusion model, incorporating (layouts, semantics) with fine-grained attributes as generation guidance. To further achieve graph manipulation while keeping the visual content consistent, we introduce a Multi-Layered Sampler (MLS) for an "isolated" image editing effect. Extensive experiments demonstrate that our method outperforms recent competitors based on text, layout, or scene graph, in terms of generation rationality and controllability.
Graph-based Unsupervised Disentangled Representation Learning via Multimodal Large Language Models
Jul 26, 2024
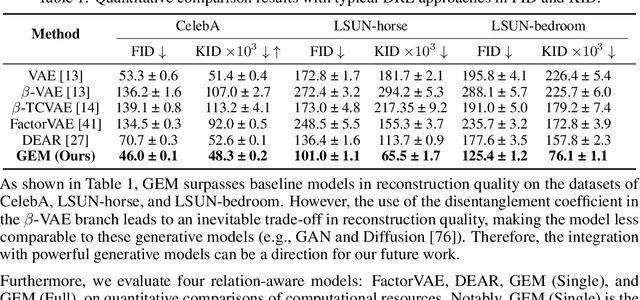
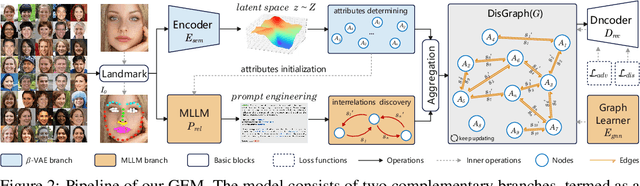
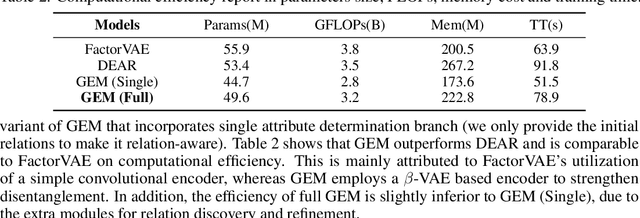
Disentangled representation learning (DRL) aims to identify and decompose underlying factors behind observations, thus facilitating data perception and generation. However, current DRL approaches often rely on the unrealistic assumption that semantic factors are statistically independent. In reality, these factors may exhibit correlations, which off-the-shelf solutions have yet to properly address. To tackle this challenge, we introduce a bidirectional weighted graph-based framework, to learn factorized attributes and their interrelations within complex data. Specifically, we propose a $\beta$-VAE based module to extract factors as the initial nodes of the graph, and leverage the multimodal large language model (MLLM) to discover and rank latent correlations, thereby updating the weighted edges. By integrating these complementary modules, our model successfully achieves fine-grained, practical and unsupervised disentanglement. Experiments demonstrate our method's superior performance in disentanglement and reconstruction. Furthermore, the model inherits enhanced interpretability and generalizability from MLLMs.
A Large Language Model-based multi-agent manufacturing system for intelligent shopfloor
May 27, 2024



As productivity advances, the demand of customers for multi-variety and small-batch production is increasing, thereby putting forward higher requirements for manufacturing systems. When production tasks frequent changes due to this demand, traditional manufacturing systems often cannot response promptly. The multi-agent manufacturing system is proposed to address this problem. However, because of technical limitations, the negotiation among agents in this kind of system is realized through predefined heuristic rules, which is not intelligent enough to deal with the multi-variety and small batch production. To this end, a Large Language Model-based (LLM-based) multi-agent manufacturing system for intelligent shopfloor is proposed in the present study. This system delineates the diverse agents and defines their collaborative methods. The roles of the agents encompass Machine Server Agent (MSA), Bid Inviter Agent (BIA), Bidder Agent (BA), Thinking Agent (TA), and Decision Agent (DA). Due to the support of LLMs, TA and DA acquire the ability of analyzing the shopfloor condition and choosing the most suitable machine, as opposed to executing a predefined program artificially. The negotiation between BAs and BIA is the most crucial step in connecting manufacturing resources. With the support of TA and DA, BIA will finalize the distribution of orders, relying on the information of each machine returned by BA. MSAs bears the responsibility for connecting the agents with the physical shopfloor. This system aims to distribute and transmit workpieces through the collaboration of the agents with these distinct roles, distinguishing it from other scheduling approaches. Comparative experiments were also conducted to validate the performance of this system.
RLLTE: Long-Term Evolution Project of Reinforcement Learning
Sep 28, 2023



We present RLLTE: a long-term evolution, extremely modular, and open-source framework for reinforcement learning (RL) research and application. Beyond delivering top-notch algorithm implementations, RLLTE also serves as a toolkit for developing algorithms. More specifically, RLLTE decouples the RL algorithms completely from the exploitation-exploration perspective, providing a large number of components to accelerate algorithm development and evolution. In particular, RLLTE is the first RL framework to build a complete and luxuriant ecosystem, which includes model training, evaluation, deployment, benchmark hub, and large language model (LLM)-empowered copilot. RLLTE is expected to set standards for RL engineering practice and be highly stimulative for industry and academia.
Thinking Like an Expert:Multimodal Hypergraph-of-Thought (HoT) Reasoning to boost Foundation Modals
Aug 11, 2023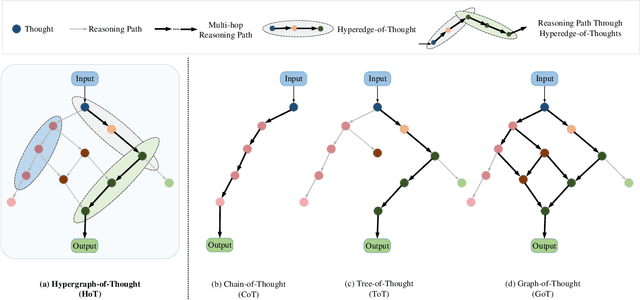

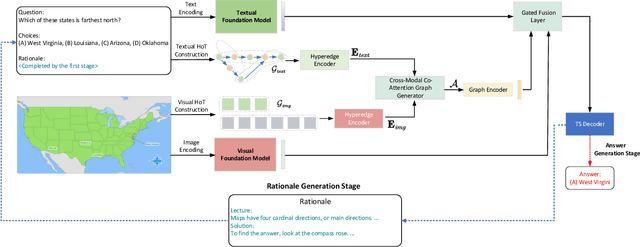

Reasoning ability is one of the most crucial capabilities of a foundation model, signifying its capacity to address complex reasoning tasks. Chain-of-Thought (CoT) technique is widely regarded as one of the effective methods for enhancing the reasoning ability of foundation models and has garnered significant attention. However, the reasoning process of CoT is linear, step-by-step, similar to personal logical reasoning, suitable for solving general and slightly complicated problems. On the contrary, the thinking pattern of an expert owns two prominent characteristics that cannot be handled appropriately in CoT, i.e., high-order multi-hop reasoning and multimodal comparative judgement. Therefore, the core motivation of this paper is transcending CoT to construct a reasoning paradigm that can think like an expert. The hyperedge of a hypergraph could connect various vertices, making it naturally suitable for modelling high-order relationships. Inspired by this, this paper innovatively proposes a multimodal Hypergraph-of-Thought (HoT) reasoning paradigm, which enables the foundation models to possess the expert-level ability of high-order multi-hop reasoning and multimodal comparative judgement. Specifically, a textual hypergraph-of-thought is constructed utilizing triple as the primary thought to model higher-order relationships, and a hyperedge-of-thought is generated through multi-hop walking paths to achieve multi-hop inference. Furthermore, we devise a visual hypergraph-of-thought to interact with the textual hypergraph-of-thought via Cross-modal Co-Attention Graph Learning for multimodal comparative verification. Experimentations on the ScienceQA benchmark demonstrate the proposed HoT-based T5 outperforms CoT-based GPT3.5 and chatGPT, which is on par with CoT-based GPT4 with a lower model size.
NaviNeRF: NeRF-based 3D Representation Disentanglement by Latent Semantic Navigation
Apr 22, 20233D representation disentanglement aims to identify, decompose, and manipulate the underlying explanatory factors of 3D data, which helps AI fundamentally understand our 3D world. This task is currently under-explored and poses great challenges: (i) the 3D representations are complex and in general contains much more information than 2D image; (ii) many 3D representations are not well suited for gradient-based optimization, let alone disentanglement. To address these challenges, we use NeRF as a differentiable 3D representation, and introduce a self-supervised Navigation to identify interpretable semantic directions in the latent space. To our best knowledge, this novel method, dubbed NaviNeRF, is the first work to achieve fine-grained 3D disentanglement without any priors or supervisions. Specifically, NaviNeRF is built upon the generative NeRF pipeline, and equipped with an Outer Navigation Branch and an Inner Refinement Branch. They are complementary -- the outer navigation is to identify global-view semantic directions, and the inner refinement dedicates to fine-grained attributes. A synergistic loss is further devised to coordinate two branches. Extensive experiments demonstrate that NaviNeRF has a superior fine-grained 3D disentanglement ability than the previous 3D-aware models. Its performance is also comparable to editing-oriented models relying on semantic or geometry priors.
TOT: Topology-Aware Optimal Transport For Multimodal Hate Detection
Feb 27, 2023



Multimodal hate detection, which aims to identify harmful content online such as memes, is crucial for building a wholesome internet environment. Previous work has made enlightening exploration in detecting explicit hate remarks. However, most of their approaches neglect the analysis of implicit harm, which is particularly challenging as explicit text markers and demographic visual cues are often twisted or missing. The leveraged cross-modal attention mechanisms also suffer from the distributional modality gap and lack logical interpretability. To address these semantic gaps issues, we propose TOT: a topology-aware optimal transport framework to decipher the implicit harm in memes scenario, which formulates the cross-modal aligning problem as solutions for optimal transportation plans. Specifically, we leverage an optimal transport kernel method to capture complementary information from multiple modalities. The kernel embedding provides a non-linear transformation ability to reproduce a kernel Hilbert space (RKHS), which reflects significance for eliminating the distributional modality gap. Moreover, we perceive the topology information based on aligned representations to conduct bipartite graph path reasoning. The newly achieved state-of-the-art performance on two publicly available benchmark datasets, together with further visual analysis, demonstrate the superiority of TOT in capturing implicit cross-modal alignment.
Span-level Bidirectional Cross-attention Framework for Aspect Sentiment Triplet Extraction
Apr 27, 2022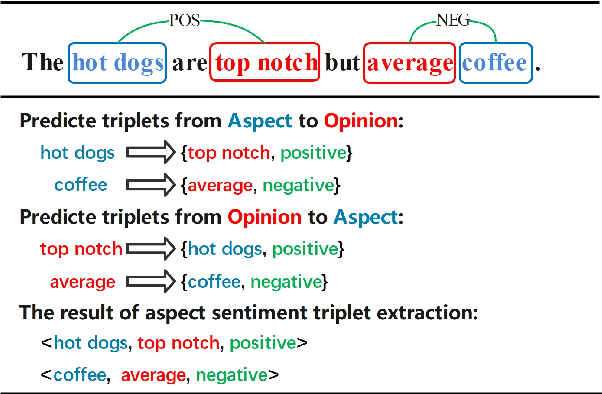
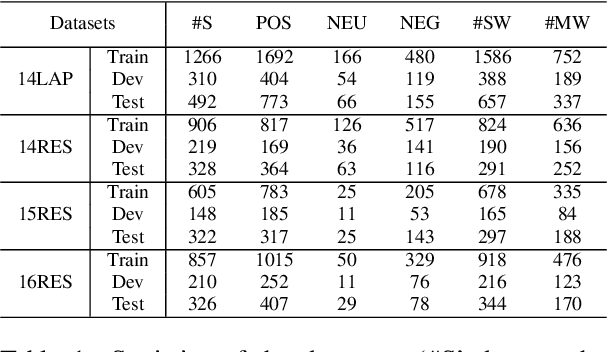
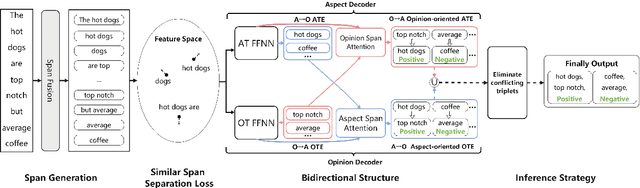
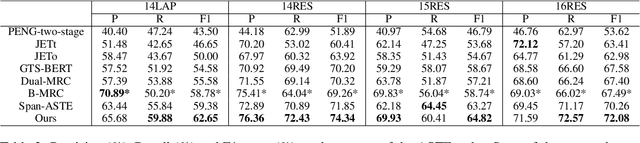
Aspect Sentiment Triplet Extraction (ASTE) is a new fine-grained sentiment analysis task that aims to extract triplets of aspect terms, sentiments, and opinion terms from review sentences. Recently, span-level models achieve gratifying results on ASTE task by taking advantage of whole span predictions. However, all the spans generated by these methods inevitably share at least one token with some others, and these method suffer from the similarity of these spans due to their similar distributions. Moreover, since either the aspect term or opinion term can trigger a sentiment triplet, it is challenging to make use of the information more comprehensively and adequately. To address these concerns, we propose a span-level bidirectional cross-attention framework. Specifically, we design a similar span separation loss to detach the spans with shared tokens and a bidirectional cross-attention structure that consists of aspect and opinion decoders to decode the span-level representations in both aspect-to-opinion and opinion-to-aspect directions. With differentiated span representations and bidirectional decoding structure, our model can extract sentiment triplets more precisely and efficiently. Experimental results show that our framework significantly outperforms state-of-the-art methods, achieving better performance in predicting triplets with multi-token entities and extracting triplets in sentences with multi-triplets.
HYPER^2: Hyperbolic Poincare Embedding for Hyper-Relational Link Prediction
Apr 20, 2021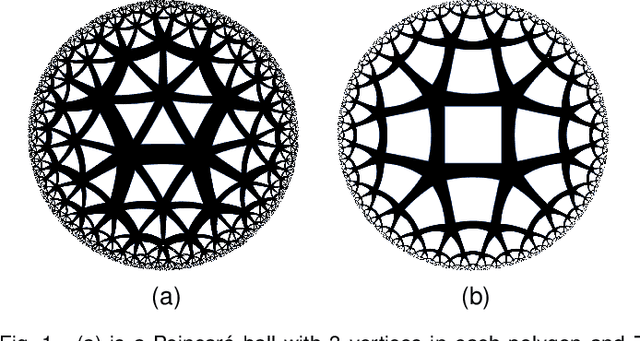
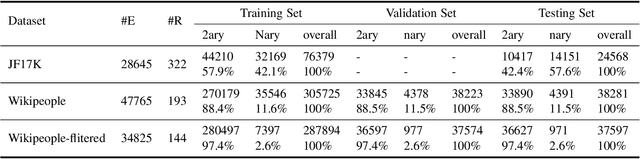
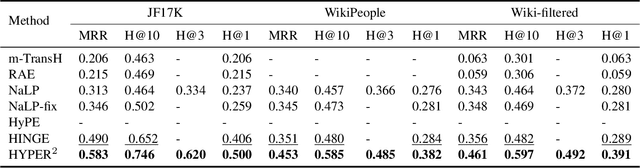
Link Prediction, addressing the issue of completing KGs with missing facts, has been broadly studied. However, less light is shed on the ubiquitous hyper-relational KGs. Most existing hyper-relational KG embedding models still tear an n-ary fact into smaller tuples, neglecting the indecomposability of some n-ary facts. While other frameworks work for certain arity facts only or ignore the significance of primary triple. In this paper, we represent an n-ary fact as a whole, simultaneously keeping the integrity of n-ary fact and maintaining the vital role that the primary triple plays. In addition, we generalize hyperbolic Poincar\'e embedding from binary to arbitrary arity data, which has not been studied yet. To tackle the weak expressiveness and high complexity issue, we propose HYPER^2 which is qualified for capturing the interaction between entities within and beyond triple through information aggregation on the tangent space. Extensive experiments demonstrate HYPER^2 achieves superior performance to its translational and deep analogues, improving SOTA by up to 34.5\% with relatively few dimensions. Moreover, we study the side effect of literals and we theoretically and experimentally compare the computational complexity of HYPER^2 against several best performing baselines, HYPER^2 is 49-61 times quicker than its counterparts.