 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantize More, Lose Less: Autoregressive Generation from Residually Quantized Speech Representations
Jul 16, 2025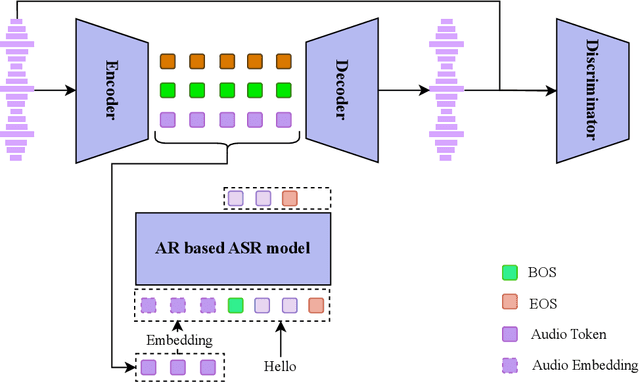

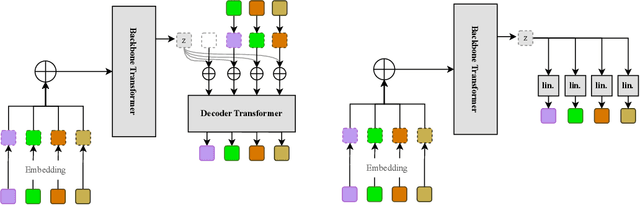
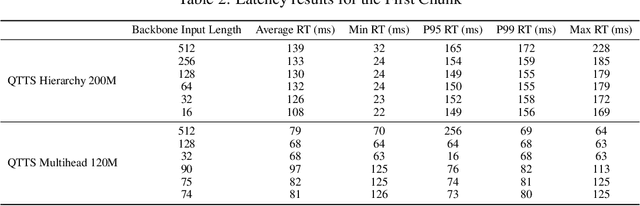
Text-to-speech (TTS) synthesis has seen renewed progress under the discrete modeling paradigm. Existing autoregressive approaches often rely on single-codebook representations, which suffer from significant information loss. Even with post-hoc refinement techniques such as flow matching, these methods fail to recover fine-grained details (e.g., prosodic nuances, speaker-specific timbres), especially in challenging scenarios like singing voice or music synthesis. We propose QTTS, a novel TTS framework built upon our new audio codec, QDAC. The core innovation of QDAC lies in its end-to-end training of an ASR-based auto-regressive network with a GAN, which achieves superior semantic feature disentanglement for scalable, near-lossless compression. QTTS models these discrete codes using two innovative strategies: the Hierarchical Parallel architecture, which uses a dual-AR structure to model inter-codebook dependencies for higher-quality synthesis, and the Delay Multihead approach, which employs parallelized prediction with a fixed delay to accelerate inference speed. Our experiments demonstrate that the proposed framework achieves higher synthesis quality and better preserves expressive content compared to baseline. This suggests that scaling up compression via multi-codebook modeling is a promising direction for high-fidelity, general-purpose speech and audio generation.
Span-level Bidirectional Cross-attention Framework for Aspect Sentiment Triplet Extraction
Apr 27, 2022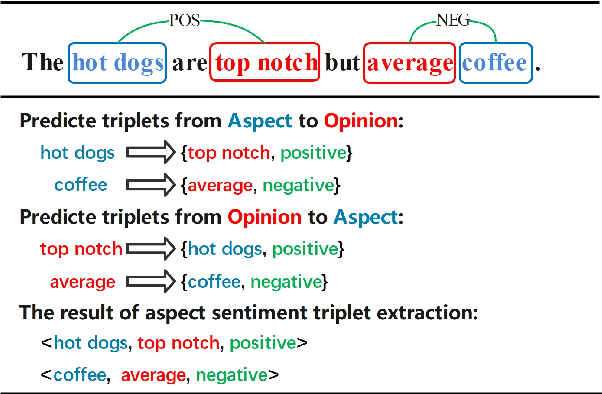
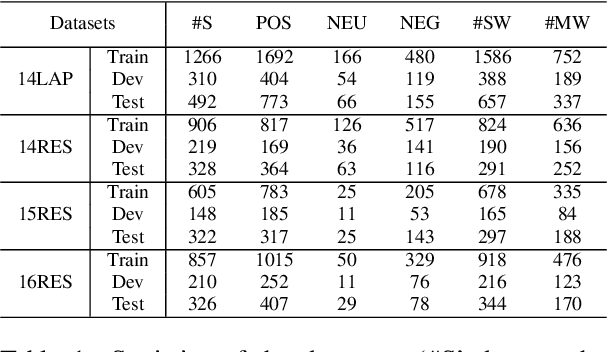
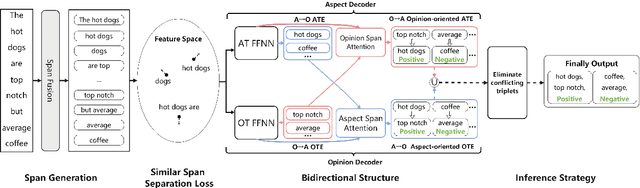
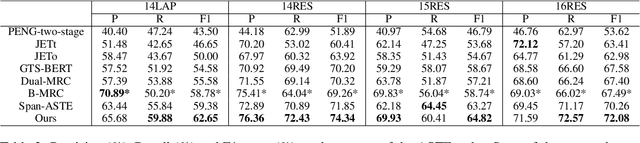
Aspect Sentiment Triplet Extraction (ASTE) is a new fine-grained sentiment analysis task that aims to extract triplets of aspect terms, sentiments, and opinion terms from review sentences. Recently, span-level models achieve gratifying results on ASTE task by taking advantage of whole span predictions. However, all the spans generated by these methods inevitably share at least one token with some others, and these method suffer from the similarity of these spans due to their similar distributions. Moreover, since either the aspect term or opinion term can trigger a sentiment triplet, it is challenging to make use of the information more comprehensively and adequately. To address these concerns, we propose a span-level bidirectional cross-attention framework. Specifically, we design a similar span separation loss to detach the spans with shared tokens and a bidirectional cross-attention structure that consists of aspect and opinion decoders to decode the span-level representations in both aspect-to-opinion and opinion-to-aspect directions. With differentiated span representations and bidirectional decoding structure, our model can extract sentiment triplets more precisely and efficiently. Experimental results show that our framework significantly outperforms state-of-the-art methods, achieving better performance in predicting triplets with multi-token entities and extracting triplets in sentences with multi-triplets.
Mengzi: Towards Lightweight yet Ingenious Pre-trained Models for Chinese
Oct 14, 2021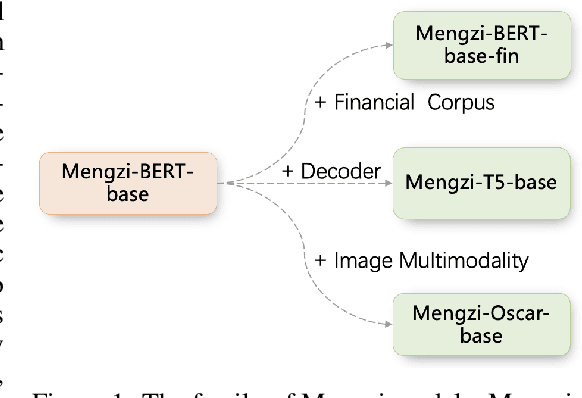
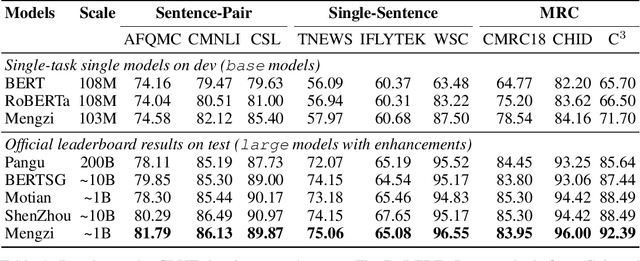

Although pre-trained models (PLMs) have achieved remarkable improvements in a wide range of NLP tasks, they are expensive in terms of time and resources. This calls for the study of training more efficient models with less computation but still ensures impressive performance. Instead of pursuing a larger scale, we are committed to developing lightweight yet more powerful models trained with equal or less computation and friendly to rapid deployment. This technical report releases our pre-trained model called Mengzi, which stands for a family of discriminative, generative, domain-specific, and multimodal pre-trained model variants, capable of a wide range of language and vision tasks. Compared with public Chinese PLMs, Mengzi is simple but more powerful. Our lightweight model has achieved new state-of-the-art results on the widely-used CLUE benchmark with our optimized pre-training and fine-tuning techniques. Without modifying the model architecture, our model can be easily employed as an alternative to existing PLMs. Our sources are available at https://github.com/Langboat/Mengzi.