 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComprehend and Talk: Text to Speech Synthesis via Dual Language Modeling
Sep 26, 2025Existing Large Language Model (LLM) based autoregressive (AR) text-to-speech (TTS) systems, while achieving state-of-the-art quality, still face critical challenges. The foundation of this LLM-based paradigm is the discretization of the continuous speech waveform into a sequence of discrete tokens by neural audio codec. However, single codebook modeling is well suited to text LLMs, but suffers from significant information loss; hierarchical acoustic tokens, typically generated via Residual Vector Quantization (RVQ), often lack explicit semantic structure, placing a heavy learning burden on the model. Furthermore, the autoregressive process is inherently susceptible to error accumulation, which can degrade generation stability. To address these limitations, we propose CaT-TTS, a novel framework for robust and semantically-grounded zero-shot synthesis. First, we introduce S3Codec, a split RVQ codec that injects explicit linguistic features into its primary codebook via semantic distillation from a state-of-the-art ASR model, providing a structured representation that simplifies the learning task. Second, we propose an ``Understand-then-Generate'' dual-Transformer architecture that decouples comprehension from rendering. An initial ``Understanding'' Transformer models the cross-modal relationship between text and the audio's semantic tokens to form a high-level utterance plan. A subsequent ``Generation'' Transformer then executes this plan, autoregressively synthesizing hierarchical acoustic tokens. Finally, to enhance generation stability, we introduce Masked Audio Parallel Inference (MAPI), a nearly parameter-free inference strategy that dynamically guides the decoding process to mitigate local errors.
PersPose: 3D Human Pose Estimation with Perspective Encoding and Perspective Rotation
Aug 24, 2025Monocular 3D human pose estimation (HPE) methods estimate the 3D positions of joints from individual images. Existing 3D HPE approaches often use the cropped image alone as input for their models. However, the relative depths of joints cannot be accurately estimated from cropped images without the corresponding camera intrinsics, which determine the perspective relationship between 3D objects and the cropped images. In this work, we introduce Perspective Encoding (PE) to encode the camera intrinsics of the cropped images. Moreover, since the human subject can appear anywhere within the original image, the perspective relationship between the 3D scene and the cropped image differs significantly, which complicates model fitting. Additionally, the further the human subject deviates from the image center, the greater the perspective distortions in the cropped image. To address these issues, we propose Perspective Rotation (PR), a transformation applied to the original image that centers the human subject, thereby reducing perspective distortions and alleviating the difficulty of model fitting. By incorporating PE and PR, we propose a novel 3D HPE framework, PersPose. Experimental results demonstrate that PersPose achieves state-of-the-art (SOTA) performance on the 3DPW, MPIINF-3DHP, and Human3.6M datasets. For example, on the in-the-wild dataset 3DPW, PersPose achieves an MPJPE of 60.1 mm, 7.54% lower than the previous SOTA approach. Code is available at: https://github.com/ KenAdamsJoseph/PersPose.
Quantize More, Lose Less: Autoregressive Generation from Residually Quantized Speech Representations
Jul 16, 2025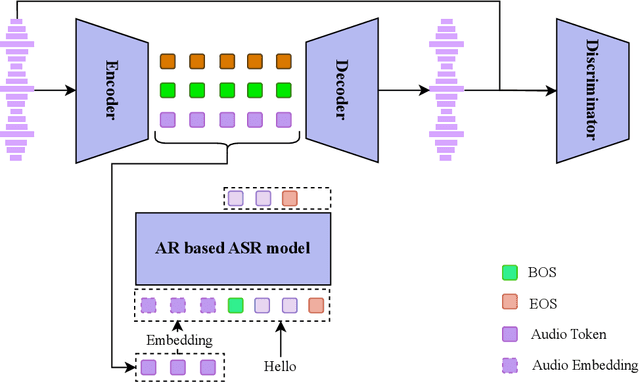

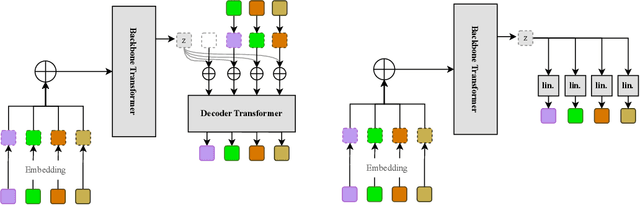
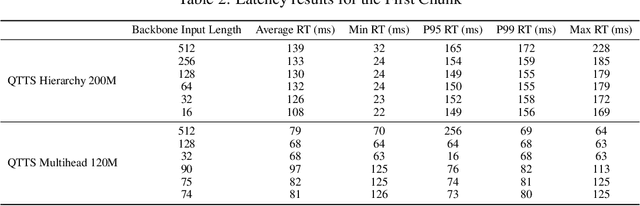
Text-to-speech (TTS) synthesis has seen renewed progress under the discrete modeling paradigm. Existing autoregressive approaches often rely on single-codebook representations, which suffer from significant information loss. Even with post-hoc refinement techniques such as flow matching, these methods fail to recover fine-grained details (e.g., prosodic nuances, speaker-specific timbres), especially in challenging scenarios like singing voice or music synthesis. We propose QTTS, a novel TTS framework built upon our new audio codec, QDAC. The core innovation of QDAC lies in its end-to-end training of an ASR-based auto-regressive network with a GAN, which achieves superior semantic feature disentanglement for scalable, near-lossless compression. QTTS models these discrete codes using two innovative strategies: the Hierarchical Parallel architecture, which uses a dual-AR structure to model inter-codebook dependencies for higher-quality synthesis, and the Delay Multihead approach, which employs parallelized prediction with a fixed delay to accelerate inference speed. Our experiments demonstrate that the proposed framework achieves higher synthesis quality and better preserves expressive content compared to baseline. This suggests that scaling up compression via multi-codebook modeling is a promising direction for high-fidelity, general-purpose speech and audio generation.
Towards Lightweight and Stable Zero-shot TTS with Self-distilled Representation Disentanglement
Jan 15, 2025Zero-shot Text-To-Speech (TTS) synthesis shows great promise for personalized voice customization through voice cloning. However, current methods for achieving zero-shot TTS heavily rely on large model scales and extensive training datasets to ensure satisfactory performance and generalizability across various speakers. This raises concerns regarding both deployment costs and data security. In this paper, we present a lightweight and stable zero-shot TTS system. We introduce a novel TTS architecture designed to effectively model linguistic content and various speaker attributes from source speech and prompt speech, respectively. Furthermore, we present a two-stage self-distillation framework that constructs parallel data pairs for effectively disentangling linguistic content and speakers from the perspective of training data. Extensive experiments show that our system exhibits excellent performance and superior stability on the zero-shot TTS tasks. Moreover, it shows markedly superior computational efficiency, with RTFs of 0.13 and 0.012 on the CPU and GPU, respectively.
Meta-Learning Guided Label Noise Distillation for Robust Signal Modulation Classification
Aug 09, 2024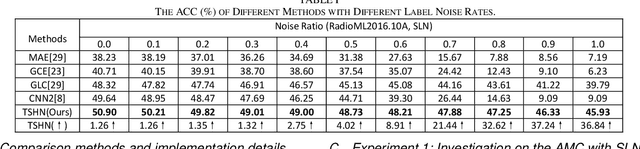
Automatic modulation classification (AMC) is an effective way to deal with physical layer threats of the internet of things (IoT). However, there is often label mislabeling in practice, which significantly impacts the performance and robustness of deep neural networks (DNNs). In this paper, we propose a meta-learning guided label noise distillation method for robust AMC. Specifically, a teacher-student heterogeneous network (TSHN) framework is proposed to distill and reuse label noise. Based on the idea that labels are representations, the teacher network with trusted meta-learning divides and conquers untrusted label samples and then guides the student network to learn better by reassessing and correcting labels. Furthermore, we propose a multi-view signal (MVS) method to further improve the performance of hard-to-classify categories with few-shot trusted label samples. Extensive experimental results show that our methods can significantly improve the performance and robustness of signal AMC in various and complex label noise scenarios, which is crucial for securing IoT applications.
D3L: Decomposition of 3D Rotation and Lift from 2D Joint to 3D for Human Mesh Recovery
Jun 10, 2023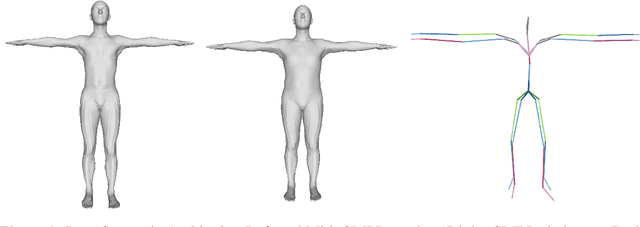

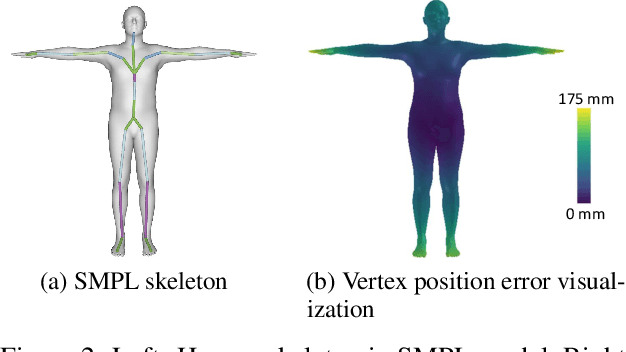
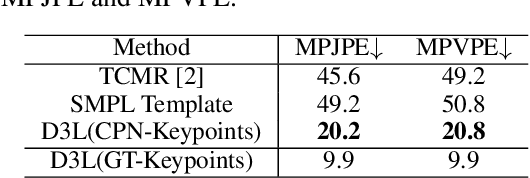
Existing methods for 3D human mesh recovery always directly estimate SMPL parameters, which involve both joint rotations and shape parameters. However, these methods present rotation semantic ambiguity, rotation error accumulation, and shape estimation overfitting, which also leads to errors in the estimated pose. Additionally, these methods have not efficiently leveraged the advancements in another hot topic, human pose estimation. To address these issues, we propose a novel approach, Decomposition of 3D Rotation and Lift from 2D Joint to 3D mesh (D3L). We disentangle 3D joint rotation into bone direction and bone twist direction so that the human mesh recovery task is broken down into estimation of pose, twist, and shape, which can be handled independently. Then we design a 2D-to-3D lifting network for estimating twist direction and 3D joint position from 2D joint position sequences and introduce a nonlinear optimization method for fitting shape parameters and bone directions. Our approach can leverage human pose estimation methods, and avoid pose errors introduced by shape estimation overfitting. We conduct experiments on the Human3.6M dataset and demonstrate improved performance compared to existing methods by a large margin.