 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShaft-integrated Force Sensing with Transformer-based Dynamics Compensation for Telesurgery
May 29, 2026Robot-Assisted Minimally Invasive Surgery (RAMIS) enhances surgeon dexterity, with newer platforms leveraging haptic feedback to further improve performance. Such force information has broader potential to inform performance assessment, tactile localization, and surgical autonomy. This motivates the need for accessible approaches to integrating force sensing into RAMIS tools. This work presents a method for integrating a six-axis commercial force sensor into the distal end of a standard cable-driven surgical instrument, enabling end-effector force measurement while preserving the original mechanical functionality of the device. The proposed design emphasizes reproducibility and accessibility for research applications, requiring no specialized manufacturing tools. A transformer neural network integrates force sensor measurements with robot state information to aid estimation of applied forces at the end-effector, compensating for internal cable forces arising from actuation. Our proposed approach achieved normalized errors below 6%, and generalized to unseen conditions better than purely proximal data-driven sensing approaches. High internal cable forces caused sensor saturation and reduced axial force observability, which can degrade performance along the tool's major axis and under higher load conditions. Given current levels of performance, the balance of system integrability and performance enables applications and research into timely topics of haptic feedback, skill assessment, and force-informed autonomy in RAMIS. Videos and code are available at https://enhanced-telerobotics.github.io/shaft force sensing.
Data-centric Design of Learning-based Surgical Gaze Perception Models in Multi-Task Simulation
Feb 09, 2026In robot-assisted minimally invasive surgery (RMIS), reduced haptic feedback and depth cues increase reliance on expert visual perception, motivating gaze-guided training and learning-based surgical perception models. However, operative expert gaze is costly to collect, and it remains unclear how the source of gaze supervision, both expertise level (intermediate vs. novice) and perceptual modality (active execution vs. passive viewing), shapes what attention models learn. We introduce a paired active-passive, multi-task surgical gaze dataset collected on the da Vinci SimNow simulator across four drills. Active gaze was recorded during task execution using a VR headset with eye tracking, and the corresponding videos were reused as stimuli to collect passive gaze from observers, enabling controlled same-video comparisons. We quantify skill- and modality-dependent differences in gaze organization and evaluate the substitutability of passive gaze for operative supervision using fixation density overlap analyses and single-frame saliency modeling. Across settings, MSI-Net produced stable, interpretable predictions, whereas SalGAN was unstable and often poorly aligned with human fixations. Models trained on passive gaze recovered a substantial portion of intermediate active attention, but with predictable degradation, and transfer was asymmetric between active and passive targets. Notably, novice passive labels approximated intermediate-passive targets with limited loss on higher-quality demonstrations, suggesting a practical path for scalable, crowd-sourced gaze supervision in surgical coaching and perception modeling.
Task-free Adaptive Meta Black-box Optimization
Jan 29, 2026Handcrafted optimizers become prohibitively inefficient for complex black-box optimization (BBO) tasks. MetaBBO addresses this challenge by meta-learning to automatically configure optimizers for low-level BBO tasks, thereby eliminating heuristic dependencies. However, existing methods typically require extensive handcrafted training tasks to learn meta-strategies that generalize to target tasks, which poses a critical limitation for realistic applications with unknown task distributions. To overcome the issue, we propose the Adaptive meta Black-box Optimization Model (ABOM), which performs online parameter adaptation using solely optimization data from the target task, obviating the need for predefined task distributions. Unlike conventional metaBBO frameworks that decouple meta-training and optimization phases, ABOM introduces a closed-loop adaptive parameter learning mechanism, where parameterized evolutionary operators continuously self-update by leveraging generated populations during optimization. This paradigm shift enables zero-shot optimization: ABOM achieves competitive performance on synthetic BBO benchmarks and realistic unmanned aerial vehicle path planning problems without any handcrafted training tasks. Visualization studies reveal that parameterized evolutionary operators exhibit statistically significant search patterns, including natural selection and genetic recombination.
Real-time Capable Learning-based Visual Tool Pose Correction via Differentiable Simulation
May 13, 2025



Autonomy in Minimally Invasive Robotic Surgery (MIRS) has the potential to reduce surgeon cognitive and task load, thereby increasing procedural efficiency. However, implementing accurate autonomous control can be difficult due to poor end-effector proprioception, a limitation of their cable-driven mechanisms. Although the robot may have joint encoders for the end-effector pose calculation, various non-idealities make the entire kinematics chain inaccurate. Modern vision-based pose estimation methods lack real-time capability or can be hard to train and generalize. In this work, we demonstrate a real-time capable, vision transformer-based pose estimation approach that is trained using end-to-end differentiable kinematics and rendering in simulation. We demonstrate the potential of this method to correct for noisy pose estimates in simulation, with the longer term goal of verifying the sim-to-real transferability of our approach.
PVUW 2025 Challenge Report: Advances in Pixel-level Understanding of Complex Videos in the Wild
Apr 15, 2025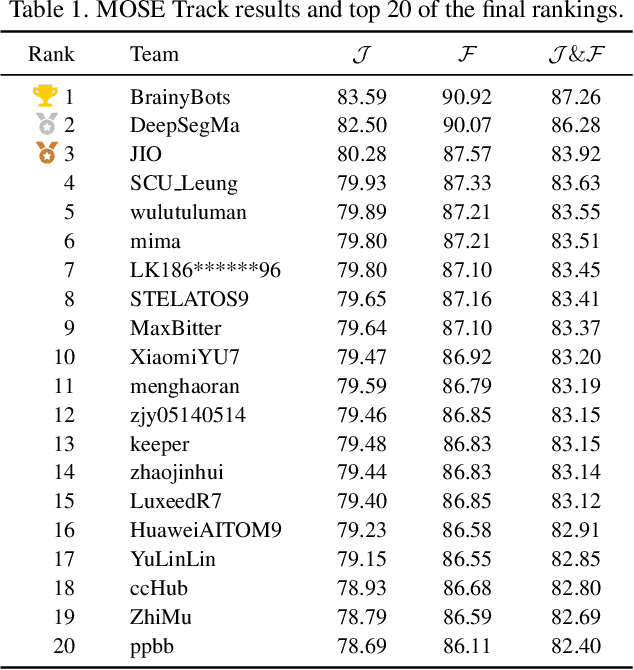
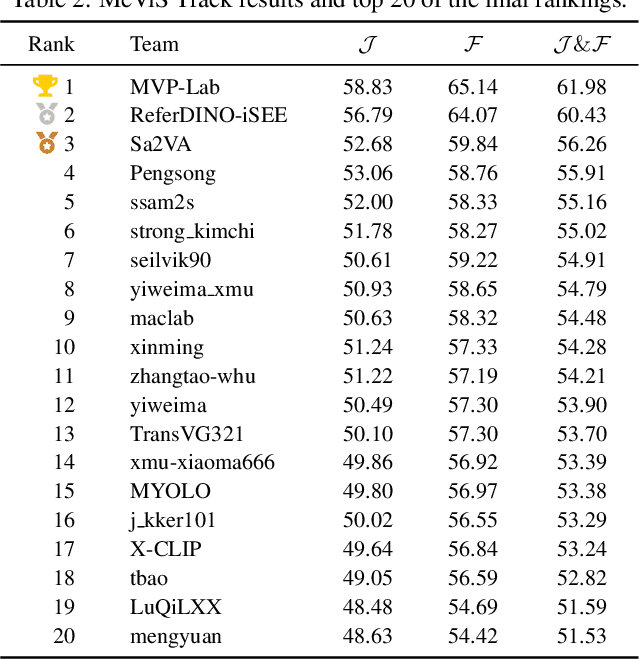
This report provides a comprehensive overview of the 4th Pixel-level Video Understanding in the Wild (PVUW) Challenge, held in conjunction with CVPR 2025. It summarizes the challenge outcomes, participating methodologies, and future research directions. The challenge features two tracks: MOSE, which focuses on complex scene video object segmentation, and MeViS, which targets motion-guided, language-based video segmentation. Both tracks introduce new, more challenging datasets designed to better reflect real-world scenarios. Through detailed evaluation and analysis, the challenge offers valuable insights into the current state-of-the-art and emerging trends in complex video segmentation. More information can be found on the workshop website: https://pvuw.github.io/.
STSeg-Complex Video Object Segmentation: The 1st Solution for 4th PVUW MOSE Challenge
Apr 11, 2025

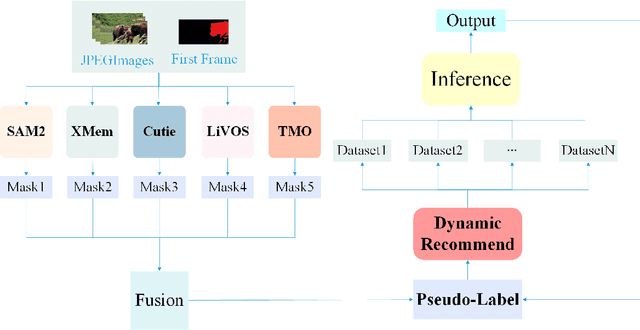
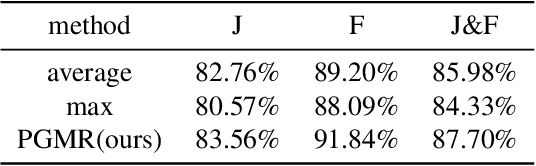
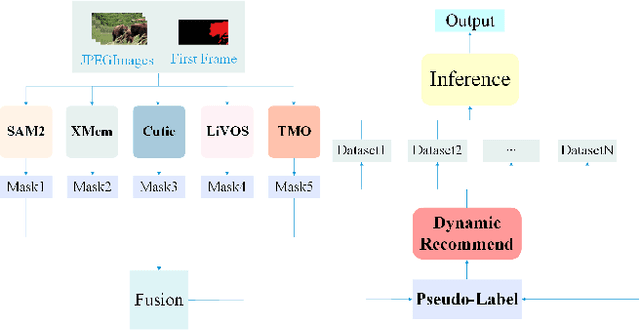
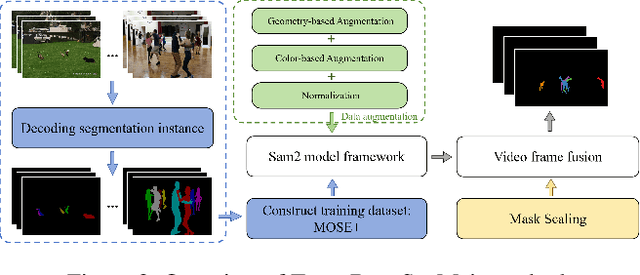
Segmentation of video objects in complex scenarios is highly challenging, and the MOSE dataset has significantly contributed to the development of this field. This technical report details the STSeg solution proposed by the "imaplus" team.By finetuning SAM2 and the unsupervised model TMO on the MOSE dataset, the STSeg solution demonstrates remarkable advantages in handling complex object motions and long-video sequences. In the inference phase, an Adaptive Pseudo-labels Guided Model Refinement Pipeline is adopted to intelligently select appropriate models for processing each video. Through finetuning the models and employing the Adaptive Pseudo-labels Guided Model Refinement Pipeline in the inference phase, the STSeg solution achieved a J&F score of 87.26% on the test set of the 2025 4th PVUW Challenge MOSE Track, securing the 1st place and advancing the technology for video object segmentation in complex scenarios.
RadioLLM: Introducing Large Language Model into Cognitive Radio via Hybrid Prompt and Token Reprogrammings
Jan 28, 2025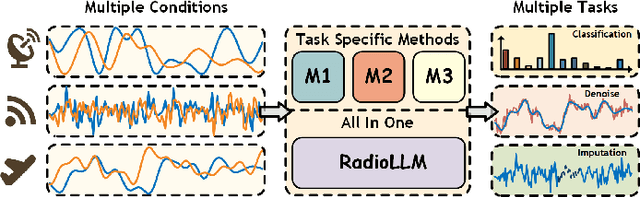



The increasing scarcity of spectrum resources and the rapid growth of wireless device have made efficient management of radio networks a critical challenge. Cognitive Radio Technology (CRT), when integrated with deep learning (DL), offers promising solutions for tasks such as radio signal classification (RSC), signal denoising, and spectrum allocation. However, existing DL-based CRT frameworks are often task-specific and lack scalability to diverse real-world scenarios. Meanwhile, Large Language Models (LLMs) have demonstrated exceptional generalization capabilities across multiple domains, making them a potential candidate for advancing CRT technologies. In this paper, we introduce RadioLLM, a novel framework that incorporates Hybrid Prompt and Token Reprogramming (HPTR) and a Frequency Attuned Fusion (FAF) module to enhance LLMs for CRT tasks. HPTR enables the integration of radio signal features with expert knowledge, while FAF improves the modeling of high-frequency features critical for precise signal processing. These innovations allow RadioLLM to handle diverse CRT tasks, bridging the gap between LLMs and traditional signal processing methods. Extensive empirical studies on multiple benchmark datasets demonstrate that the proposed RadioLLM achieves superior performance over current baselines.
Learning Evolution via Optimization Knowledge Adaptation
Jan 04, 2025



Evolutionary algorithms (EAs) maintain populations through evolutionary operators to discover diverse solutions for complex tasks while gathering valuable knowledge, such as historical population data and fitness evaluations. However, traditional EAs face challenges in dynamically adapting to expanding knowledge bases, hindering the efficient exploitation of accumulated information and limiting adaptability to new situations. To address these issues, we introduce an Optimization Knowledge Adaptation Evolutionary Model (OKAEM), which features dynamic parameter adjustment using accumulated knowledge to enhance its optimization capabilities. OKAEM employs attention mechanisms to model the interactions among individuals, fitness landscapes, and genetic components separately, thereby parameterizing the evolutionary operators of selection, crossover, and mutation. These powerful learnable operators enable OKAEM to benefit from pre-learned extensive prior knowledge and self-tune with real-time evolutionary insights. Experimental results demonstrate that OKAEM: 1) exploits prior knowledge for significant performance gains across various knowledge transfer settings; 2) achieves competitive performance through self-tuning alone, even without prior knowledge; 3) outperforms state-of-the-art black-box baselines in a vision-language model tuning case; 4) can improve its optimization capabilities with growing knowledge; 5) is capable of emulating principles of natural selection and genetic recombination.
Knowledge-aware Evolutionary Graph Neural Architecture Search
Nov 26, 2024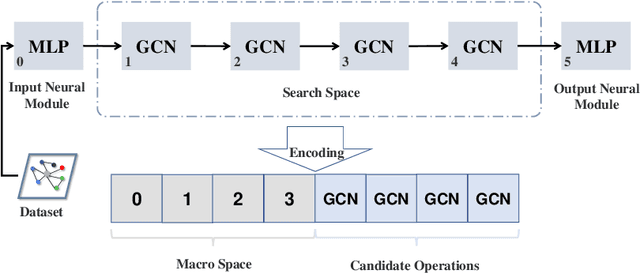
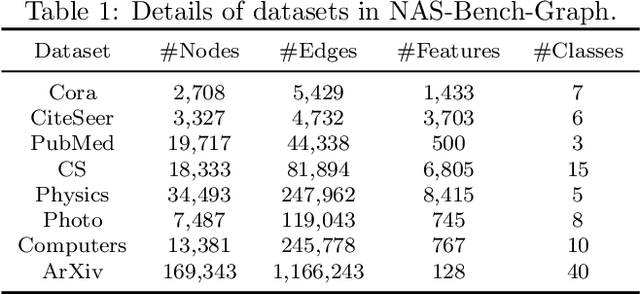
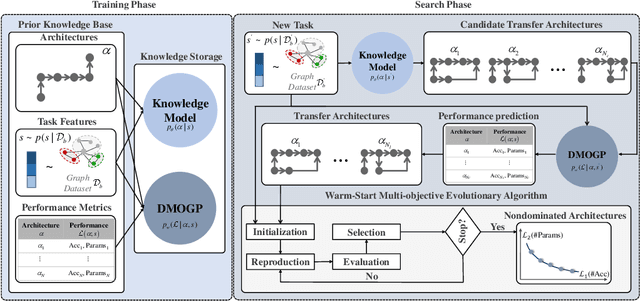
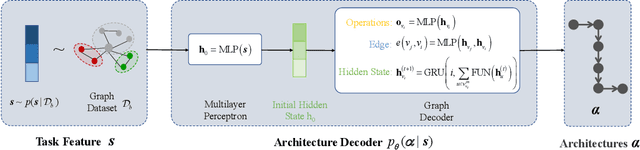
Graph neural architecture search (GNAS) can customize high-performance graph neural network architectures for specific graph tasks or datasets. However, existing GNAS methods begin searching for architectures from a zero-knowledge state, ignoring the prior knowledge that may improve the search efficiency. The available knowledge base (e.g. NAS-Bench-Graph) contains many rich architectures and their multiple performance metrics, such as the accuracy (#Acc) and number of parameters (#Params). This study proposes exploiting such prior knowledge to accelerate the multi-objective evolutionary search on a new graph dataset, named knowledge-aware evolutionary GNAS (KEGNAS). KEGNAS employs the knowledge base to train a knowledge model and a deep multi-output Gaussian process (DMOGP) in one go, which generates and evaluates transfer architectures in only a few GPU seconds. The knowledge model first establishes a dataset-to-architecture mapping, which can quickly generate candidate transfer architectures for a new dataset. Subsequently, the DMOGP with architecture and dataset encodings is designed to predict multiple performance metrics for candidate transfer architectures on the new dataset. According to the predicted metrics, non-dominated candidate transfer architectures are selected to warm-start the multi-objective evolutionary algorithm for optimizing the #Acc and #Params on a new dataset. Empirical studies on NAS-Bench-Graph and five real-world datasets show that KEGNAS swiftly generates top-performance architectures, achieving 4.27% higher accuracy than advanced evolutionary baselines and 11.54% higher accuracy than advanced differentiable baselines. In addition, ablation studies demonstrate that the use of prior knowledge significantly improves the search performance.
Peri-midFormer: Periodic Pyramid Transformer for Time Series Analysis
Nov 07, 2024



Time series analysis finds wide applications in fields such as weather forecasting, anomaly detection, and behavior recognition. Previous methods attempted to model temporal variations directly using 1D time series. However, this has been quite challenging due to the discrete nature of data points in time series and the complexity of periodic variation. In terms of periodicity, taking weather and traffic data as an example, there are multi-periodic variations such as yearly, monthly, weekly, and daily, etc. In order to break through the limitations of the previous methods, we decouple the implied complex periodic variations into inclusion and overlap relationships among different level periodic components based on the observation of the multi-periodicity therein and its inclusion relationships. This explicitly represents the naturally occurring pyramid-like properties in time series, where the top level is the original time series and lower levels consist of periodic components with gradually shorter periods, which we call the periodic pyramid. To further extract complex temporal variations, we introduce self-attention mechanism into the periodic pyramid, capturing complex periodic relationships by computing attention between periodic components based on their inclusion, overlap, and adjacency relationships. Our proposed Peri-midFormer demonstrates outstanding performance in five mainstream time series analysis tasks, including short- and long-term forecasting, imputation, classification, and anomaly detection.