 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Bridging the Gap between Large-Scale Pretraining and Efficient Finetuning for Humanoid Control
Jan 29, 2026Reinforcement learning (RL) is widely used for humanoid control, with on-policy methods such as Proximal Policy Optimization (PPO) enabling robust training via large-scale parallel simulation and, in some cases, zero-shot deployment to real robots. However, the low sample efficiency of on-policy algorithms limits safe adaptation to new environments. Although off-policy RL and model-based RL have shown improved sample efficiency, the gap between large-scale pretraining and efficient finetuning on humanoids still exists. In this paper, we find that off-policy Soft Actor-Critic (SAC), with large-batch update and a high Update-To-Data (UTD) ratio, reliably supports large-scale pretraining of humanoid locomotion policies, achieving zero-shot deployment on real robots. For adaptation, we demonstrate that these SAC-pretrained policies can be finetuned in new environments and out-of-distribution tasks using model-based methods. Data collection in the new environment executes a deterministic policy while stochastic exploration is instead confined to a physics-informed world model. This separation mitigates the risks of random exploration during adaptation while preserving exploratory coverage for improvement. Overall, the approach couples the wall-clock efficiency of large-scale simulation during pretraining with the sample efficiency of model-based learning during fine-tuning.
DI3CL: Contrastive Learning With Dynamic Instances and Contour Consistency for SAR Land-Cover Classification Foundation Model
Nov 12, 2025Although significant advances have been achieved in SAR land-cover classification, recent methods remain predominantly focused on supervised learning, which relies heavily on extensive labeled datasets. This dependency not only limits scalability and generalization but also restricts adaptability to diverse application scenarios. In this paper, a general-purpose foundation model for SAR land-cover classification is developed, serving as a robust cornerstone to accelerate the development and deployment of various downstream models. Specifically, a Dynamic Instance and Contour Consistency Contrastive Learning (DI3CL) pre-training framework is presented, which incorporates a Dynamic Instance (DI) module and a Contour Consistency (CC) module. DI module enhances global contextual awareness by enforcing local consistency across different views of the same region. CC module leverages shallow feature maps to guide the model to focus on the geometric contours of SAR land-cover objects, thereby improving structural discrimination. Additionally, to enhance robustness and generalization during pre-training, a large-scale and diverse dataset named SARSense, comprising 460,532 SAR images, is constructed to enable the model to capture comprehensive and representative features. To evaluate the generalization capability of our foundation model, we conducted extensive experiments across a variety of SAR land-cover classification tasks, including SAR land-cover mapping, water body detection, and road extraction. The results consistently demonstrate that the proposed DI3CL outperforms existing methods. Our code and pre-trained weights are publicly available at: https://github.com/SARpre-train/DI3CL.
Hierarchical Direction Perception via Atomic Dot-Product Operators for Rotation-Invariant Point Clouds Learning
Nov 11, 2025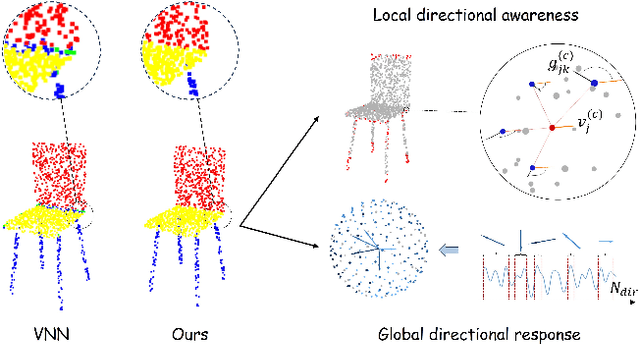
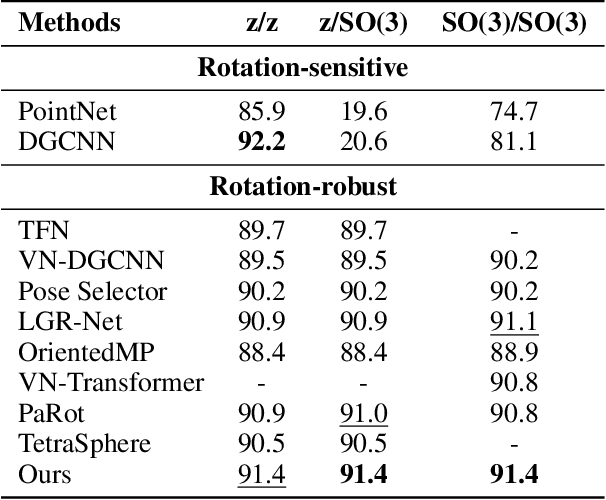
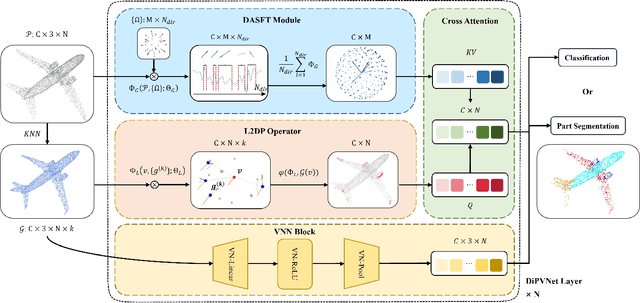
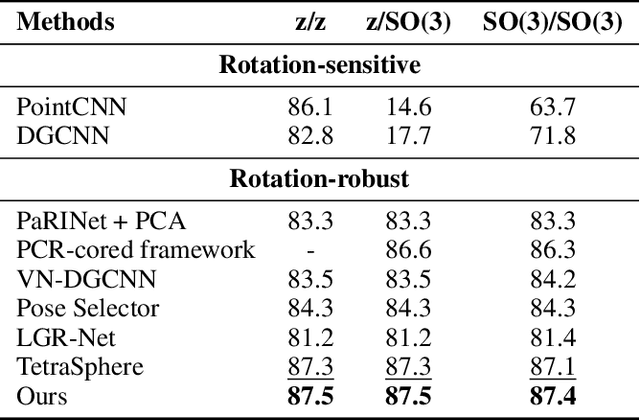
Point cloud processing has become a cornerstone technology in many 3D vision tasks. However, arbitrary rotations introduce variations in point cloud orientations, posing a long-standing challenge for effective representation learning. The core of this issue is the disruption of the point cloud's intrinsic directional characteristics caused by rotational perturbations. Recent methods attempt to implicitly model rotational equivariance and invariance, preserving directional information and propagating it into deep semantic spaces. Yet, they often fall short of fully exploiting the multiscale directional nature of point clouds to enhance feature representations. To address this, we propose the Direction-Perceptive Vector Network (DiPVNet). At its core is an atomic dot-product operator that simultaneously encodes directional selectivity and rotation invariance--endowing the network with both rotational symmetry modeling and adaptive directional perception. At the local level, we introduce a Learnable Local Dot-Product (L2DP) Operator, which enables interactions between a center point and its neighbors to adaptively capture the non-uniform local structures of point clouds. At the global level, we leverage generalized harmonic analysis to prove that the dot-product between point clouds and spherical sampling vectors is equivalent to a direction-aware spherical Fourier transform (DASFT). This leads to the construction of a global directional response spectrum for modeling holistic directional structures. We rigorously prove the rotation invariance of both operators. Extensive experiments on challenging scenarios involving noise and large-angle rotations demonstrate that DiPVNet achieves state-of-the-art performance on point cloud classification and segmentation tasks. Our code is available at https://github.com/wxszreal0/DiPVNet.
SpecRouter: Adaptive Routing for Multi-Level Speculative Decoding in Large Language Models
May 12, 2025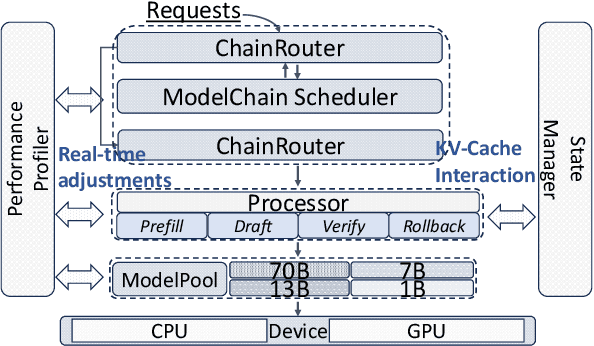
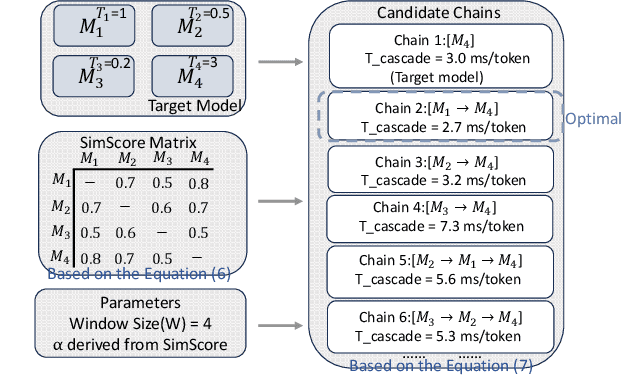
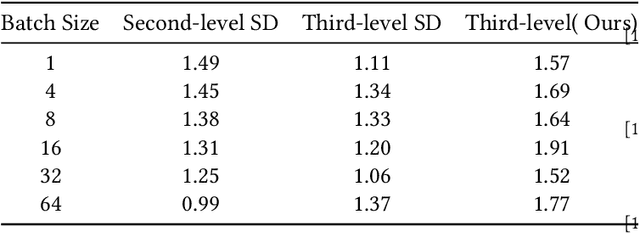
Large Language Models (LLMs) present a critical trade-off between inference quality and computational cost: larger models offer superior capabilities but incur significant latency, while smaller models are faster but less powerful. Existing serving strategies often employ fixed model scales or static two-stage speculative decoding, failing to dynamically adapt to the varying complexities of user requests or fluctuations in system performance. This paper introduces \systemname{}, a novel framework that reimagines LLM inference as an adaptive routing problem solved through multi-level speculative decoding. \systemname{} dynamically constructs and optimizes inference "paths" (chains of models) based on real-time feedback, addressing the limitations of static approaches. Our contributions are threefold: (1) An \textbf{adaptive model chain scheduling} mechanism that leverages performance profiling (execution times) and predictive similarity metrics (derived from token distribution divergence) to continuously select the optimal sequence of draft and verifier models, minimizing predicted latency per generated token. (2) A \textbf{multi-level collaborative verification} framework where intermediate models within the selected chain can validate speculative tokens, reducing the verification burden on the final, most powerful target model. (3) A \textbf{synchronized state management} system providing efficient, consistent KV cache handling across heterogeneous models in the chain, including precise, low-overhead rollbacks tailored for asynchronous batch processing inherent in multi-level speculation. Preliminary experiments demonstrate the validity of our method.
Renormalized Connection for Scale-preferred Object Detection in Satellite Imagery
Sep 09, 2024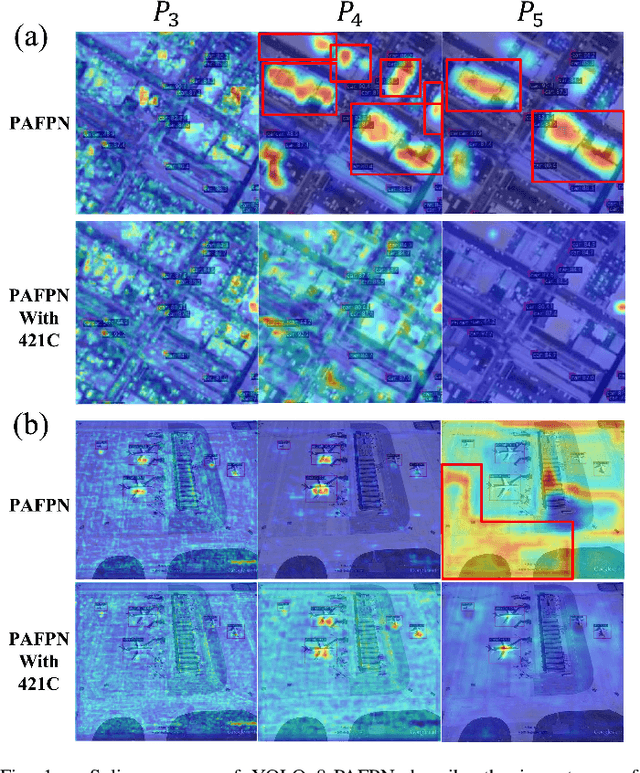
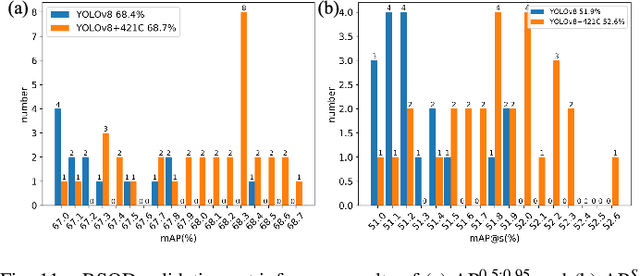
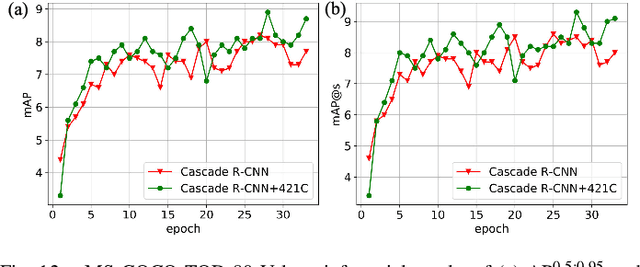
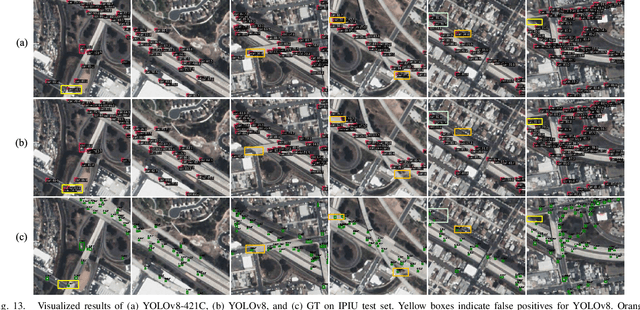
Satellite imagery, due to its long-range imaging, brings with it a variety of scale-preferred tasks, such as the detection of tiny/small objects, making the precise localization and detection of small objects of interest a challenging task. In this article, we design a Knowledge Discovery Network (KDN) to implement the renormalization group theory in terms of efficient feature extraction. Renormalized connection (RC) on the KDN enables ``synergistic focusing'' of multi-scale features. Based on our observations of KDN, we abstract a class of RCs with different connection strengths, called n21C, and generalize it to FPN-based multi-branch detectors. In a series of FPN experiments on the scale-preferred tasks, we found that the ``divide-and-conquer'' idea of FPN severely hampers the detector's learning in the right direction due to the large number of large-scale negative samples and interference from background noise. Moreover, these negative samples cannot be eliminated by the focal loss function. The RCs extends the multi-level feature's ``divide-and-conquer'' mechanism of the FPN-based detectors to a wide range of scale-preferred tasks, and enables synergistic effects of multi-level features on the specific learning goal. In addition, interference activations in two aspects are greatly reduced and the detector learns in a more correct direction. Extensive experiments of 17 well-designed detection architectures embedded with n21s on five different levels of scale-preferred tasks validate the effectiveness and efficiency of the RCs. Especially the simplest linear form of RC, E421C performs well in all tasks and it satisfies the scaling property of RGT. We hope that our approach will transfer a large number of well-designed detectors from the computer vision community to the remote sensing community.
* 24 pages, 14 figures Journal
Masked Angle-Aware Autoencoder for Remote Sensing Images
Aug 04, 2024To overcome the inherent domain gap between remote sensing (RS) images and natural images, some self-supervised representation learning methods have made promising progress. However, they have overlooked the diverse angles present in RS objects. This paper proposes the Masked Angle-Aware Autoencoder (MA3E) to perceive and learn angles during pre-training. We design a \textit{scaling center crop} operation to create the rotated crop with random orientation on each original image, introducing the explicit angle variation. MA3E inputs this composite image while reconstruct the original image, aiming to effectively learn rotation-invariant representations by restoring the angle variation introduced on the rotated crop. To avoid biases caused by directly reconstructing the rotated crop, we propose an Optimal Transport (OT) loss that automatically assigns similar original image patches to each rotated crop patch for reconstruction. MA3E demonstrates more competitive performance than existing pre-training methods on seven different RS image datasets in three downstream tasks.
Spatio-Temporal Tuples Transformer for Skeleton-Based Action Recognition
Jan 08, 2022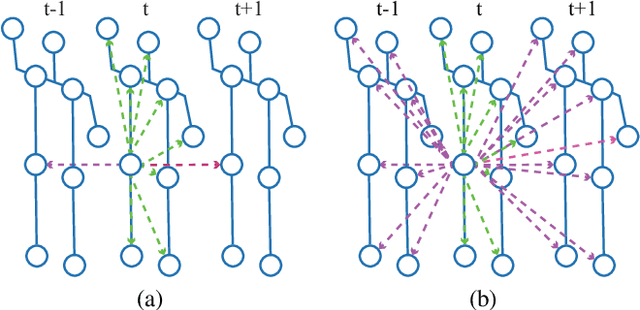
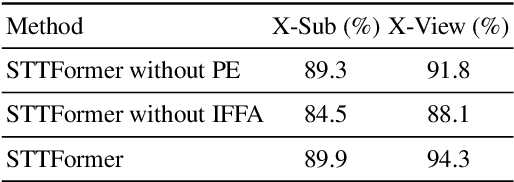

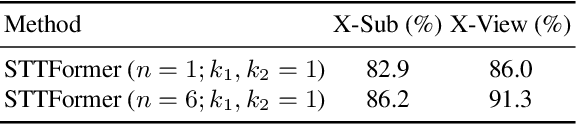
Capturing the dependencies between joints is critical in skeleton-based action recognition task. Transformer shows great potential to model the correlation of important joints. However, the existing Transformer-based methods cannot capture the correlation of different joints between frames, which the correlation is very useful since different body parts (such as the arms and legs in "long jump") between adjacent frames move together. Focus on this problem, A novel spatio-temporal tuples Transformer (STTFormer) method is proposed. The skeleton sequence is divided into several parts, and several consecutive frames contained in each part are encoded. And then a spatio-temporal tuples self-attention module is proposed to capture the relationship of different joints in consecutive frames. In addition, a feature aggregation module is introduced between non-adjacent frames to enhance the ability to distinguish similar actions. Compared with the state-of-the-art methods, our method achieves better performance on two large-scale datasets.
FCOSR: A Simple Anchor-free Rotated Detector for Aerial Object Detection
Dec 01, 2021

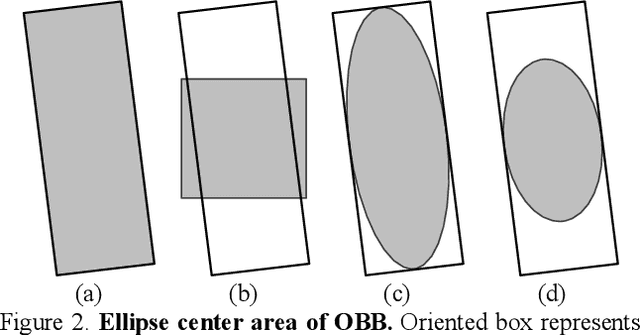

Existing anchor-base oriented object detection methods have achieved amazing results, but these methods require some manual preset boxes, which introduces additional hyperparameters and calculations. The existing anchor-free methods usually have complex architectures and are not easy to deploy. Our goal is to propose an algorithm which is simple and easy-to-deploy for aerial image detection. In this paper, we present a one-stage anchor-free rotated object detector (FCOSR) based on FCOS, which can be deployed on most platforms. The FCOSR has a simple architecture consisting of only convolution layers. Our work focuses on the label assignment strategy for the training phase. We use ellipse center sampling method to define a suitable sampling region for oriented bounding box (OBB). The fuzzy sample assignment strategy provides reasonable labels for overlapping objects. To solve the insufficient sampling problem, a multi-level sampling module is designed. These strategies allocate more appropriate labels to training samples. Our algorithm achieves 79.25, 75.41, and 90.15 mAP on DOTA1.0, DOTA1.5, and HRSC2016 datasets, respectively. FCOSR demonstrates superior performance to other methods in single-scale evaluation. We convert a lightweight FCOSR model to TensorRT format, which achieves 73.93 mAP on DOTA1.0 at a speed of 10.68 FPS on Jetson Xavier NX with single scale. The code is available at: https://github.com/lzh420202/FCOSR
More Separable and Easier to Segment: A Cluster Alignment Method for Cross-Domain Semantic Segmentation
May 07, 2021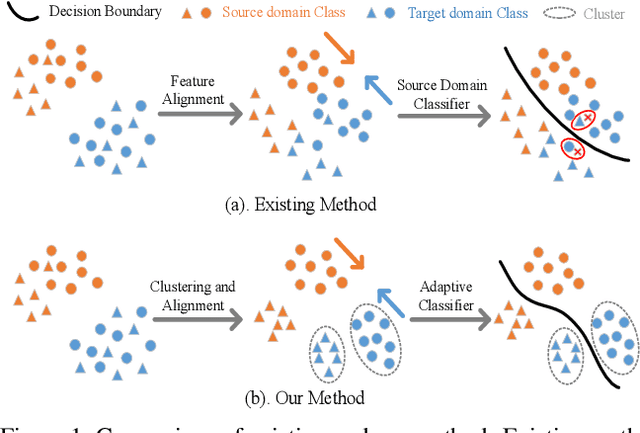



Feature alignment between domains is one of the mainstream methods for Unsupervised Domain Adaptation (UDA) semantic segmentation. Existing feature alignment methods for semantic segmentation learn domain-invariant features by adversarial training to reduce domain discrepancy, but they have two limits: 1) associations among pixels are not maintained, 2) the classifier trained on the source domain couldn't adapted well to the target. In this paper, we propose a new UDA semantic segmentation approach based on domain closeness assumption to alleviate the above problems. Specifically, a prototype clustering strategy is applied to cluster pixels with the same semantic, which will better maintain associations among target domain pixels during the feature alignment. After clustering, to make the classifier more adaptive, a normalized cut loss based on the affinity graph of the target domain is utilized, which will make the decision boundary target-specific. Sufficient experiments conducted on GTA5 $\rightarrow$ Cityscapes and SYNTHIA $\rightarrow$ Cityscapes proved the effectiveness of our method, which illustrated that our results achieved the new state-of-the-art.
Modified Diversity of Class Probability Estimation Co-training for Hyperspectral Image Classification
Sep 05, 2018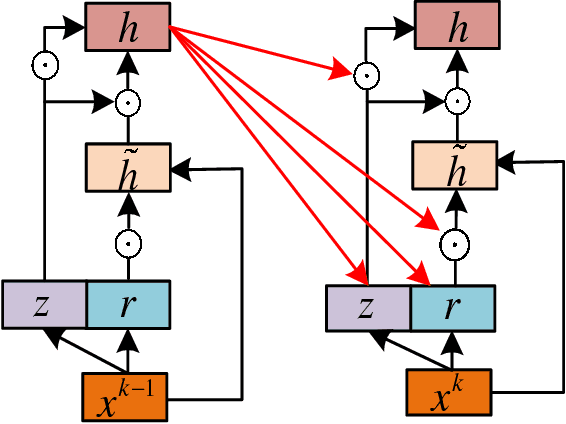
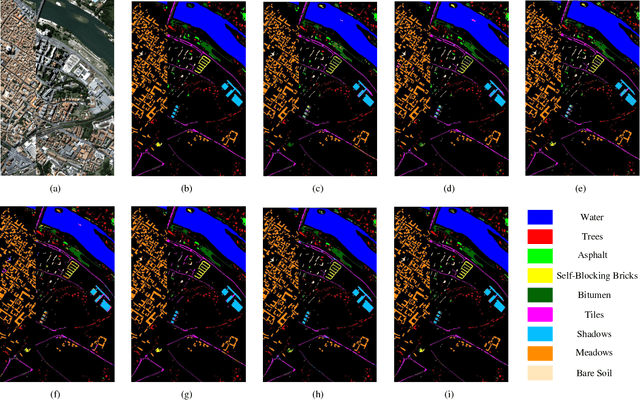
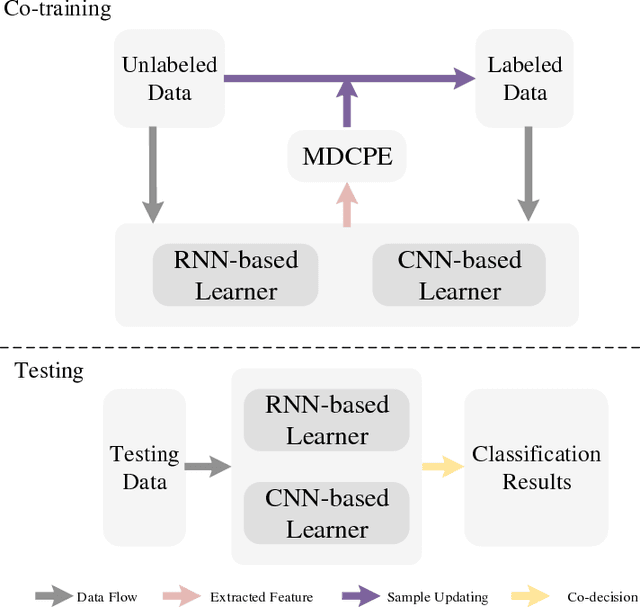
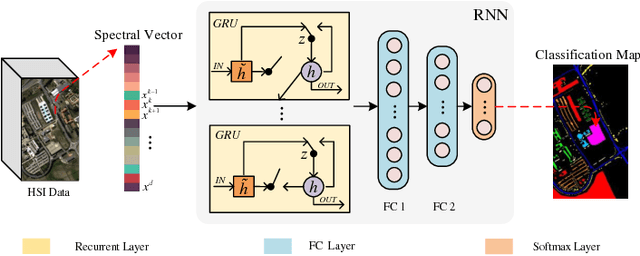
Due to the limited amount and imbalanced classes of labeled training data, the conventional supervised learning can not ensure the discrimination of the learned feature for hyperspectral image (HSI) classification. In this paper, we propose a modified diversity of class probability estimation (MDCPE) with two deep neural networks to learn spectral-spatial feature for HSI classification. In co-training phase, recurrent neural network (RNN) and convolutional neural network (CNN) are utilized as two learners to extract features from labeled and unlabeled data. Based on the extracted features, MDCPE selects most credible samples to update initial labeled data by combining k-means clustering with the traditional diversity of class probability estimation (DCPE) co-training. In this way, MDCPE can keep new labeled data class-balanced and extract discriminative features for both the minority and majority classes. During testing process, classification results are acquired by co-decision of the two learners. Experimental results demonstrate that the proposed semi-supervised co-training method can make full use of unlabeled information to enhance generality of the learners and achieve favorable accuracies on all three widely used data sets: Salinas, Pavia University and Pavia Center.