 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge-aware GAT-based protein binding site prediction
Jan 05, 2026Accurate identification of protein binding sites is crucial for understanding biomolecular interaction mechanisms and for the rational design of drug targets. Traditional predictive methods often struggle to balance prediction accuracy with computational efficiency when capturing complex spatial conformations. To address this challenge, we propose an Edge-aware Graph Attention Network (Edge-aware GAT) model for the fine-grained prediction of binding sites across various biomolecules, including proteins, DNA/RNA, ions, ligands, and lipids. Our method constructs atom-level graphs and integrates multidimensional structural features, including geometric descriptors, DSSP-derived secondary structure, and relative solvent accessibility (RSA), to generate spatially aware embedding vectors. By incorporating interatomic distances and directional vectors as edge features within the attention mechanism, the model significantly enhances its representation capacity. On benchmark datasets, our model achieves an ROC-AUC of 0.93 for protein-protein binding site prediction, outperforming several state-of-the-art methods. The use of directional tensor propagation and residue-level attention pooling further improves both binding site localization and the capture of local structural details. Visualizations using PyMOL confirm the model's practical utility and interpretability. To facilitate community access and application, we have deployed a publicly accessible web server at http://119.45.201.89:5000/. In summary, our approach offers a novel and efficient solution that balances prediction accuracy, generalization, and interpretability for identifying functional sites in proteins.
Bi-DCSpell: A Bi-directional Detector-Corrector Interactive Framework for Chinese Spelling Check
Jun 04, 2024



Chinese Spelling Check (CSC) aims to detect and correct potentially misspelled characters in Chinese sentences. Naturally, it involves the detection and correction subtasks, which interact with each other dynamically. Such interactions are bi-directional, i.e., the detection result would help reduce the risk of over-correction and under-correction while the knowledge learnt from correction would help prevent false detection. Current CSC approaches are of two types: correction-only or single-directional detection-to-correction interactive frameworks. Nonetheless, they overlook the bi-directional interactions between detection and correction. This paper aims to fill the gap by proposing a Bi-directional Detector-Corrector framework for CSC (Bi-DCSpell). Notably, Bi-DCSpell contains separate detection and correction encoders, followed by a novel interactive learning module facilitating bi-directional feature interactions between detection and correction to improve each other's representation learning. Extensive experimental results demonstrate a robust correction performance of Bi-DCSpell on widely used benchmarking datasets while possessing a satisfactory detection ability.
LLM-Oriented Retrieval Tuner
Mar 04, 2024



Dense Retrieval (DR) is now considered as a promising tool to enhance the memorization capacity of Large Language Models (LLM) such as GPT3 and GPT-4 by incorporating external memories. However, due to the paradigm discrepancy between text generation of LLM and DR, it is still an open challenge to integrate the retrieval and generation tasks in a shared LLM. In this paper, we propose an efficient LLM-Oriented Retrieval Tuner, namely LMORT, which decouples DR capacity from base LLM and non-invasively coordinates the optimally aligned and uniform layers of the LLM towards a unified DR space, achieving an efficient and effective DR without tuning the LLM itself. The extensive experiments on six BEIR datasets show that our approach could achieve competitive zero-shot retrieval performance compared to a range of strong DR models while maintaining the generation ability of LLM.
Controllable Text Generation with Residual Memory Transformer
Sep 28, 2023



Large-scale Causal Language Models (CLMs), e.g., GPT3 and ChatGPT, have brought great success in text generation. However, it is still an open challenge to control the generation process of CLM while balancing flexibility, control granularity, and generation efficiency. In this paper, we provide a new alternative for controllable text generation (CTG), by designing a non-intrusive, lightweight control plugin to accompany the generation of CLM at arbitrary time steps. The proposed control plugin, namely Residual Memory Transformer (RMT), has an encoder-decoder setup, which can accept any types of control conditions and cooperate with CLM through a residual learning paradigm, to achieve a more flexible, general, and efficient CTG. Extensive experiments are carried out on various control tasks, in the form of both automatic and human evaluations. The results show the superiority of RMT over a range of state-of-the-art approaches, proving the effectiveness and versatility of our approach.
DisCup: Discriminator Cooperative Unlikelihood Prompt-tuning for Controllable Text Generation
Oct 18, 2022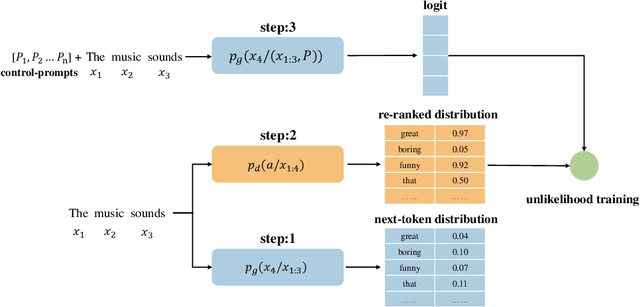
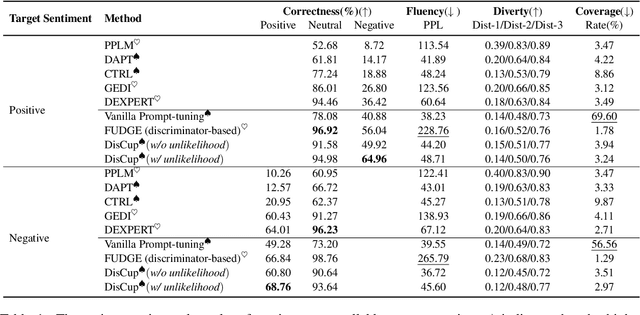

Prompt learning with immensely large Casual Language Models (CLMs) has been shown promising for attribute-controllable text generation (CTG). However, vanilla prompt tuning tends to imitate training corpus characteristics beyond the control attributes, resulting in a poor generalization ability. Moreover, it is less able to capture the relationship between different attributes, further limiting the control performance. In this paper, we propose a new CTG approach, namely DisCup, which incorporates the attribute knowledge of discriminator to optimize the control-prompts, steering a frozen CLM to produce attribute-specific texts. Specifically, the frozen CLM model, capable of producing multitudinous texts, is first used to generate the next-token candidates based on the context, so as to ensure the diversity of tokens to be predicted. Then, we leverage an attribute-discriminator to select desired/undesired tokens from those candidates, providing the inter-attribute knowledge. Finally, we bridge the above two traits by an unlikelihood objective for prompt-tuning. Extensive experimental results show that DisCup can achieve a new state-of-the-art control performance while maintaining an efficient and high-quality text generation, only relying on around 10 virtual tokens.
A Survey of Controllable Text Generation using Transformer-based Pre-trained Language Models
Jan 14, 2022
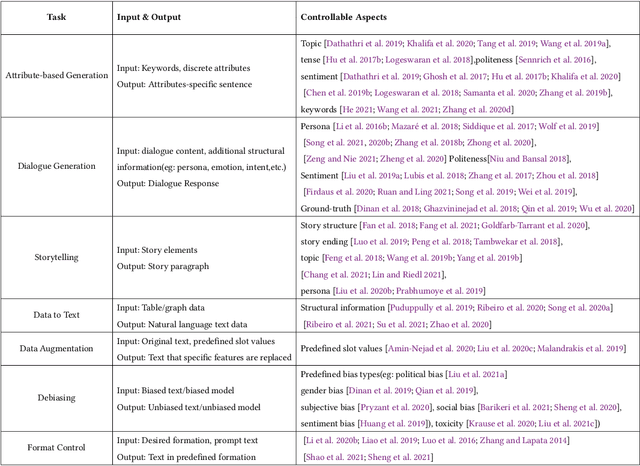
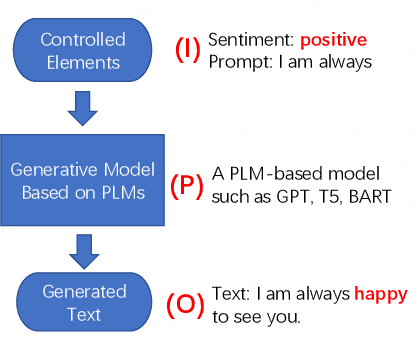
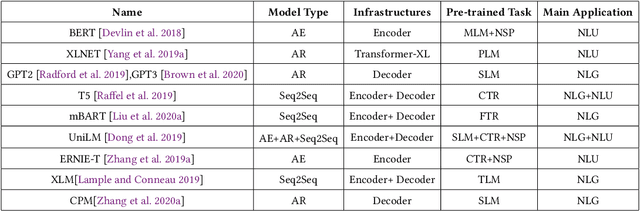
Controllable Text Generation (CTG) is emerging area in the field of natural language generation (NLG). It is regarded as crucial for the development of advanced text generation technologies that are more natural and better meet the specific constraints in practical applications. In recent years, methods using large-scale pre-trained language models (PLMs), in particular the widely used transformer-based PLMs, have become a new paradigm of NLG, allowing generation of more diverse and fluent text. However, due to the lower level of interpretability of deep neural networks, the controllability of these methods need to be guaranteed. To this end, controllable text generation using transformer-based PLMs has become a rapidly growing yet challenging new research hotspot. A diverse range of approaches have emerged in the recent 3-4 years, targeting different CTG tasks which may require different types of controlled constraints. In this paper, we present a systematic critical review on the common tasks, main approaches and evaluation methods in this area. Finally, we discuss the challenges that the field is facing, and put forward various promising future directions. To the best of our knowledge, this is the first survey paper to summarize CTG techniques from the perspective of PLMs. We hope it can help researchers in related fields to quickly track the academic frontier, providing them with a landscape of the area and a roadmap for future research.
Mengzi: Towards Lightweight yet Ingenious Pre-trained Models for Chinese
Oct 14, 2021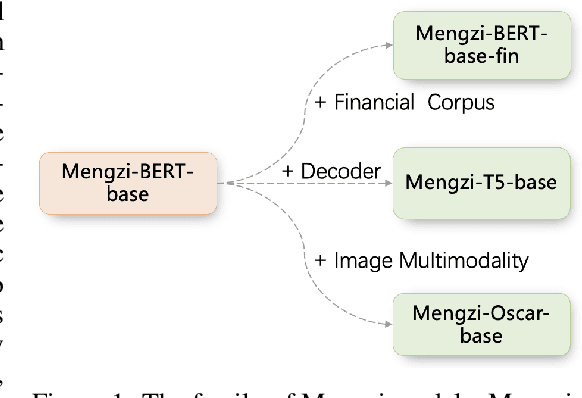
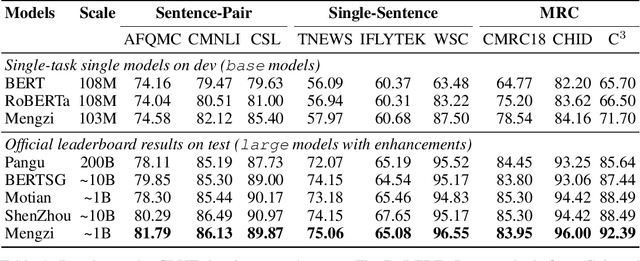

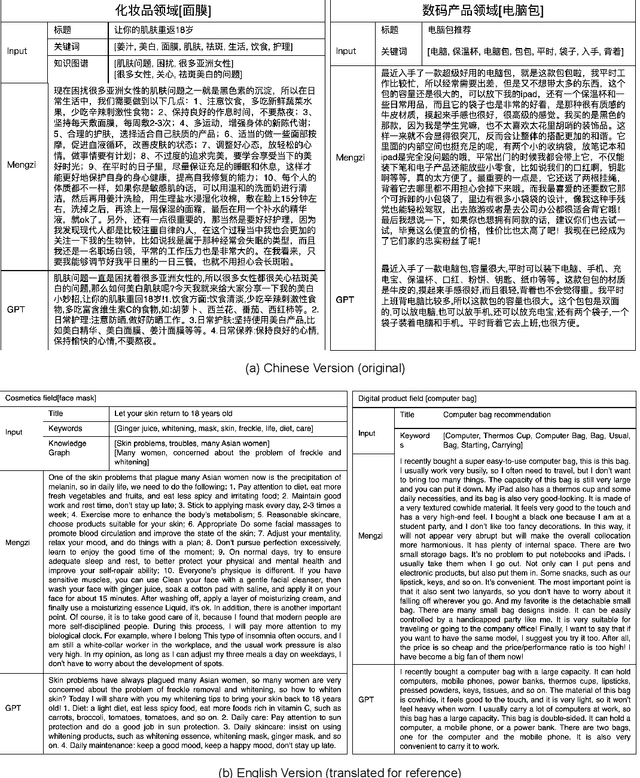
Although pre-trained models (PLMs) have achieved remarkable improvements in a wide range of NLP tasks, they are expensive in terms of time and resources. This calls for the study of training more efficient models with less computation but still ensures impressive performance. Instead of pursuing a larger scale, we are committed to developing lightweight yet more powerful models trained with equal or less computation and friendly to rapid deployment. This technical report releases our pre-trained model called Mengzi, which stands for a family of discriminative, generative, domain-specific, and multimodal pre-trained model variants, capable of a wide range of language and vision tasks. Compared with public Chinese PLMs, Mengzi is simple but more powerful. Our lightweight model has achieved new state-of-the-art results on the widely-used CLUE benchmark with our optimized pre-training and fine-tuning techniques. Without modifying the model architecture, our model can be easily employed as an alternative to existing PLMs. Our sources are available at https://github.com/Langboat/Mengzi.
ToxTrac: a fast and robust software for tracking organisms
Jun 08, 2017
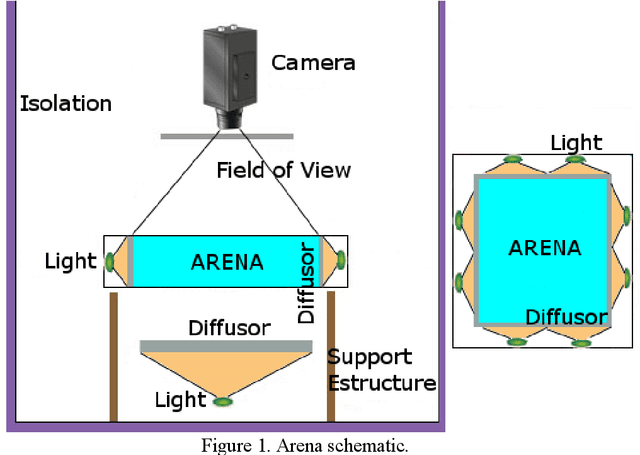
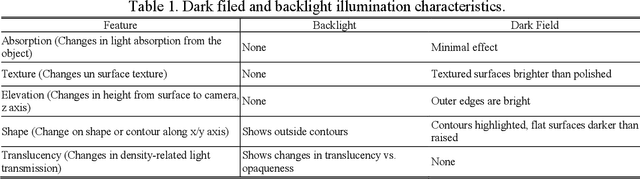
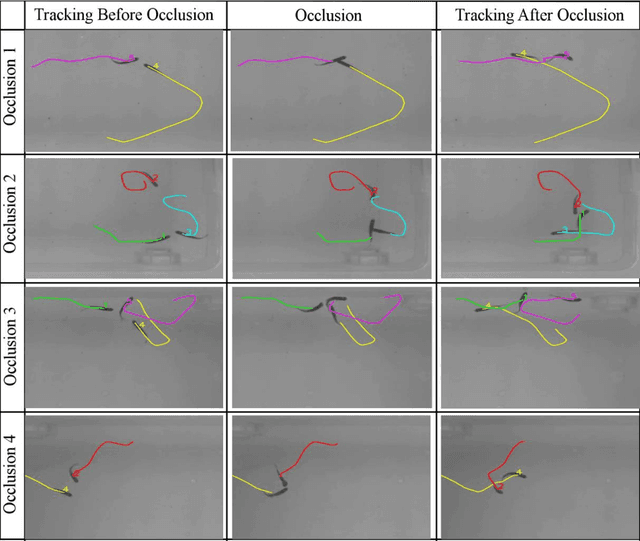
1. Behavioral analysis based on video recording is becoming increasingly popular within research fields such as; ecology, medicine, ecotoxicology, and toxicology. However, the programs available to analyze the data, which are; free of cost, user-friendly, versatile, robust, fast and provide reliable statistics for different organisms (invertebrates, vertebrates and mammals) are significantly limited. 2. We present an automated open-source executable software (ToxTrac) for image-based tracking that can simultaneously handle several organisms monitored in a laboratory environment. We compare the performance of ToxTrac with current accessible programs on the web. 3. The main advantages of ToxTrac are: i) no specific knowledge of the geometry of the tracked bodies is needed; ii) processing speed, ToxTrac can operate at a rate >25 frames per second in HD videos using modern desktop computers; iii) simultaneous tracking of multiple organisms in multiple arenas; iv) integrated distortion correction and camera calibration; v) robust against false positives; vi) preservation of individual identification if crossing occurs; vii) useful statistics and heat maps in real scale are exported in: image, text and excel formats. 4. ToxTrac can be used for high speed tracking of insects, fish, rodents or other species, and provides useful locomotor information. We suggest using ToxTrac for future studies of animal behavior independent of research area. Download ToxTrac here: https://toxtrac.sourceforge.io
UmUTracker: A versatile MATLAB program for automated particle tracking of 2D light microscopy or 3D digital holography data
Apr 21, 2017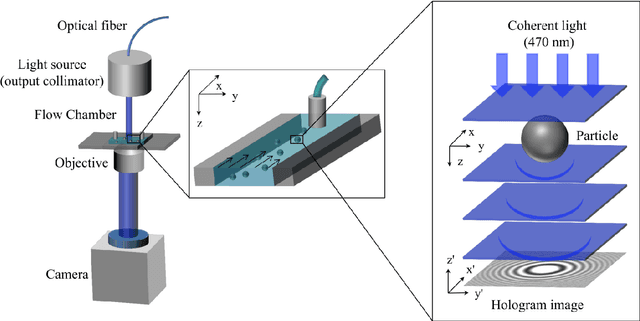
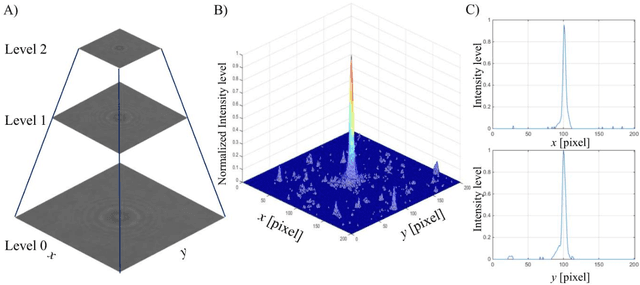
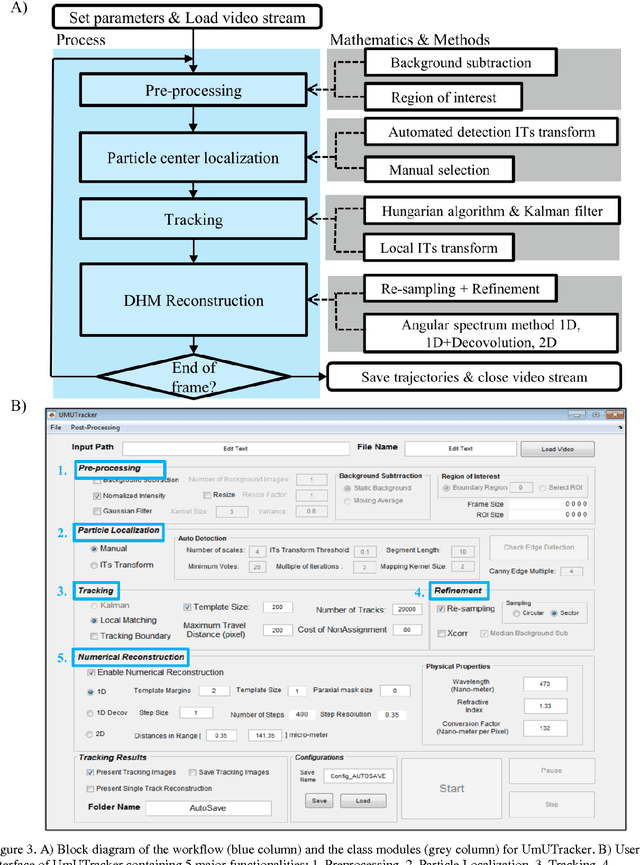
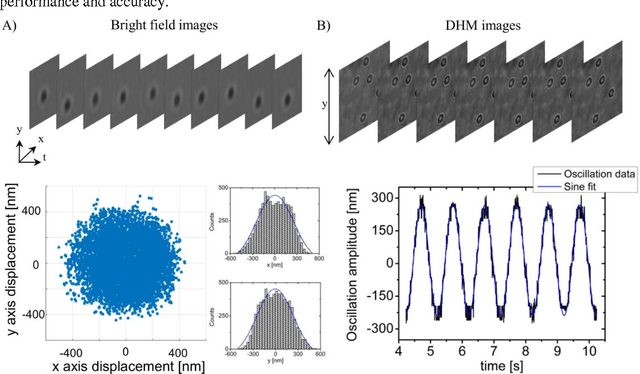
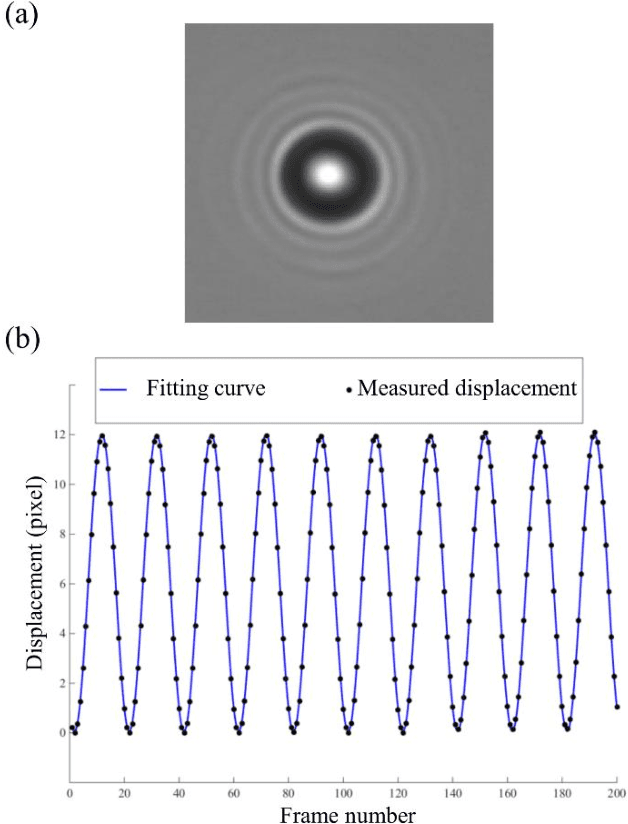
We present a versatile and fast MATLAB program (UmUTracker) that automatically detects and tracks particles by analyzing video sequences acquired by either light microscopy or digital in-line holographic microscopy. Our program detects the 2D lateral positions of particles with an algorithm based on the isosceles triangle transform, and reconstructs their 3D axial positions by a fast implementation of the Rayleigh-Sommerfeld model using a radial intensity profile. To validate the accuracy and performance of our program, we first track the 2D position of polystyrene particles using bright field and digital holographic microscopy. Second, we determine the 3D particle position by analyzing synthetic and experimentally acquired holograms. Finally, to highlight the full program features, we profile the microfluidic flow in a 100 micrometer high flow chamber. This result agrees with computational fluid dynamic simulations. On a regular desktop computer UmUTracker can detect, analyze, and track multiple particles at 5 frames per second for a template size of 201 x 201 in a 1024 x 1024 image. To enhance usability and to make it easy to implement new functions we used object-oriented programming. UmUTracker is suitable for studies related to: particle dynamics, cell localization, colloids and microfluidic flow measurement.
A robust particle detection algorithm based on symmetry
May 11, 2016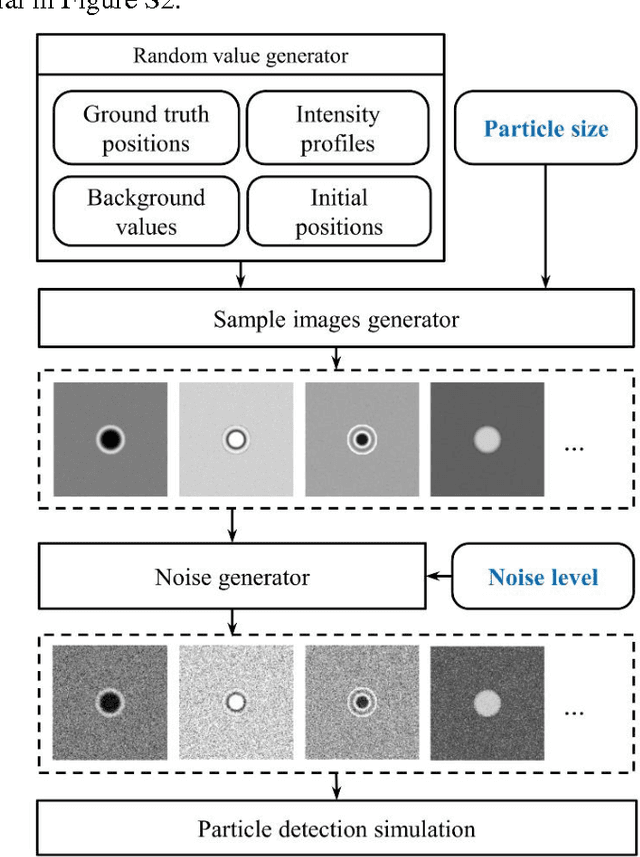
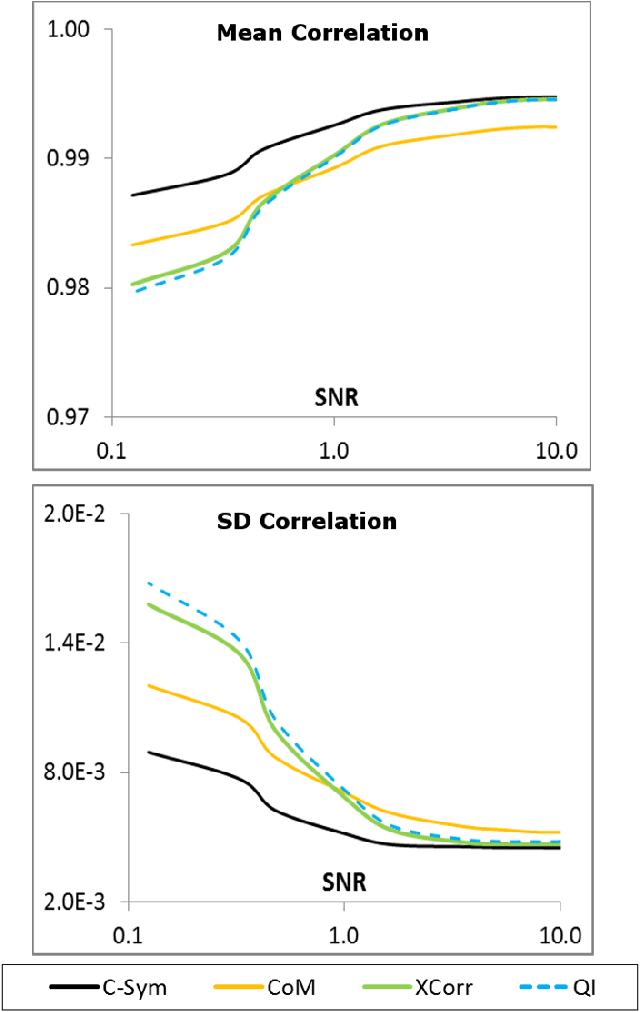
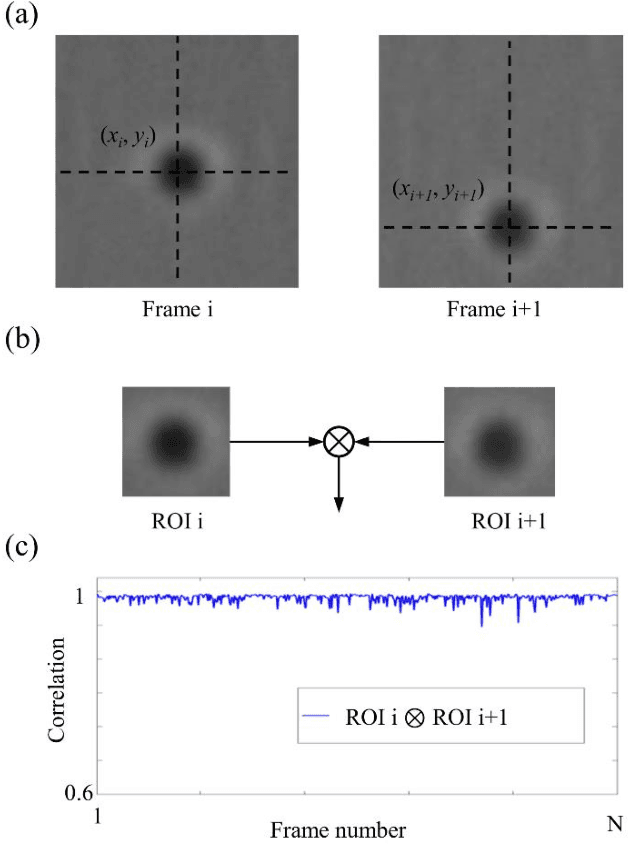
Particle tracking is common in many biophysical, ecological, and micro-fluidic applications. Reliable tracking information is heavily dependent on of the system under study and algorithms that correctly determines particle position between images. However, in a real environmental context with the presence of noise including particular or dissolved matter in water, and low and fluctuating light conditions, many algorithms fail to obtain reliable information. We propose a new algorithm, the Circular Symmetry algorithm (C-Sym), for detecting the position of a circular particle with high accuracy and precision in noisy conditions. The algorithm takes advantage of the spatial symmetry of the particle allowing for subpixel accuracy. We compare the proposed algorithm with four different methods using both synthetic and experimental datasets. The results show that C-Sym is the most accurate and precise algorithm when tracking micro-particles in all tested conditions and it has the potential for use in applications including tracking biota in their environment.