 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastStair: Learning to Run Up Stairs with Humanoid Robots
Jan 15, 2026Running up stairs is effortless for humans but remains extremely challenging for humanoid robots due to the simultaneous requirements of high agility and strict stability. Model-free reinforcement learning (RL) can generate dynamic locomotion, yet implicit stability rewards and heavy reliance on task-specific reward shaping tend to result in unsafe behaviors, especially on stairs; conversely, model-based foothold planners encode contact feasibility and stability structure, but enforcing their hard constraints often induces conservative motion that limits speed. We present FastStair, a planner-guided, multi-stage learning framework that reconciles these complementary strengths to achieve fast and stable stair ascent. FastStair integrates a parallel model-based foothold planner into the RL training loop to bias exploration toward dynamically feasible contacts and to pretrain a safety-focused base policy. To mitigate planner-induced conservatism and the discrepancy between low- and high-speed action distributions, the base policy was fine-tuned into speed-specialized experts and then integrated via Low-Rank Adaptation (LoRA) to enable smooth operation across the full commanded-speed range. We deploy the resulting controller on the Oli humanoid robot, achieving stable stair ascent at commanded speeds up to 1.65 m/s and traversing a 33-step spiral staircase (17 cm rise per step) in 12 s, demonstrating robust high-speed performance on long staircases. Notably, the proposed approach served as the champion solution in the Canton Tower Robot Run Up Competition.
PvP: Data-Efficient Humanoid Robot Learning with Proprioceptive-Privileged Contrastive Representations
Dec 15, 2025Achieving efficient and robust whole-body control (WBC) is essential for enabling humanoid robots to perform complex tasks in dynamic environments. Despite the success of reinforcement learning (RL) in this domain, its sample inefficiency remains a significant challenge due to the intricate dynamics and partial observability of humanoid robots. To address this limitation, we propose PvP, a Proprioceptive-Privileged contrastive learning framework that leverages the intrinsic complementarity between proprioceptive and privileged states. PvP learns compact and task-relevant latent representations without requiring hand-crafted data augmentations, enabling faster and more stable policy learning. To support systematic evaluation, we develop SRL4Humanoid, the first unified and modular framework that provides high-quality implementations of representative state representation learning (SRL) methods for humanoid robot learning. Extensive experiments on the LimX Oli robot across velocity tracking and motion imitation tasks demonstrate that PvP significantly improves sample efficiency and final performance compared to baseline SRL methods. Our study further provides practical insights into integrating SRL with RL for humanoid WBC, offering valuable guidance for data-efficient humanoid robot learning.
Gait-Adaptive Perceptive Humanoid Locomotion with Real-Time Under-Base Terrain Reconstruction
Dec 08, 2025For full-size humanoid robots, even with recent advances in reinforcement learning-based control, achieving reliable locomotion on complex terrains, such as long staircases, remains challenging. In such settings, limited perception, ambiguous terrain cues, and insufficient adaptation of gait timing can cause even a single misplaced or mistimed step to result in rapid loss of balance. We introduce a perceptive locomotion framework that merges terrain sensing, gait regulation, and whole-body control into a single reinforcement learning policy. A downward-facing depth camera mounted under the base observes the support region around the feet, and a compact U-Net reconstructs a dense egocentric height map from each frame in real time, operating at the same frequency as the control loop. The perceptual height map, together with proprioceptive observations, is processed by a unified policy that produces joint commands and a global stepping-phase signal, allowing gait timing and whole-body posture to be adapted jointly to the commanded motion and local terrain geometry. We further adopt a single-stage successive teacher-student training scheme for efficient policy learning and knowledge transfer. Experiments conducted on a 31-DoF, 1.65 m humanoid robot demonstrate robust locomotion in both simulation and real-world settings, including forward and backward stair ascent and descent, as well as crossing a 46 cm gap. Project Page:https://ga-phl.github.io/
Is Intermediate Fusion All You Need for UAV-based Collaborative Perception?
Apr 30, 2025Collaborative perception enhances environmental awareness through inter-agent communication and is regarded as a promising solution to intelligent transportation systems. However, existing collaborative methods for Unmanned Aerial Vehicles (UAVs) overlook the unique characteristics of the UAV perspective, resulting in substantial communication overhead. To address this issue, we propose a novel communication-efficient collaborative perception framework based on late-intermediate fusion, dubbed LIF. The core concept is to exchange informative and compact detection results and shift the fusion stage to the feature representation level. In particular, we leverage vision-guided positional embedding (VPE) and box-based virtual augmented feature (BoBEV) to effectively integrate complementary information from various agents. Additionally, we innovatively introduce an uncertainty-driven communication mechanism that uses uncertainty evaluation to select high-quality and reliable shared areas. Experimental results demonstrate that our LIF achieves superior performance with minimal communication bandwidth, proving its effectiveness and practicality. Code and models are available at https://github.com/uestchjw/LIF.
MA2CL:Masked Attentive Contrastive Learning for Multi-Agent Reinforcement Learning
Jun 03, 2023



Recent approaches have utilized self-supervised auxiliary tasks as representation learning to improve the performance and sample efficiency of vision-based reinforcement learning algorithms in single-agent settings. However, in multi-agent reinforcement learning (MARL), these techniques face challenges because each agent only receives partial observation from an environment influenced by others, resulting in correlated observations in the agent dimension. So it is necessary to consider agent-level information in representation learning for MARL. In this paper, we propose an effective framework called \textbf{M}ulti-\textbf{A}gent \textbf{M}asked \textbf{A}ttentive \textbf{C}ontrastive \textbf{L}earning (MA2CL), which encourages learning representation to be both temporal and agent-level predictive by reconstructing the masked agent observation in latent space. Specifically, we use an attention reconstruction model for recovering and the model is trained via contrastive learning. MA2CL allows better utilization of contextual information at the agent level, facilitating the training of MARL agents for cooperation tasks. Extensive experiments demonstrate that our method significantly improves the performance and sample efficiency of different MARL algorithms and outperforms other methods in various vision-based and state-based scenarios. Our code can be found in \url{https://github.com/ustchlsong/MA2CL}
A Survey of Controllable Text Generation using Transformer-based Pre-trained Language Models
Jan 14, 2022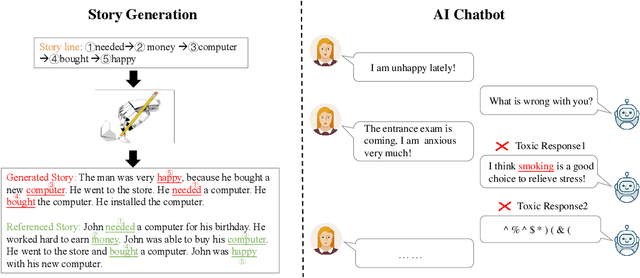
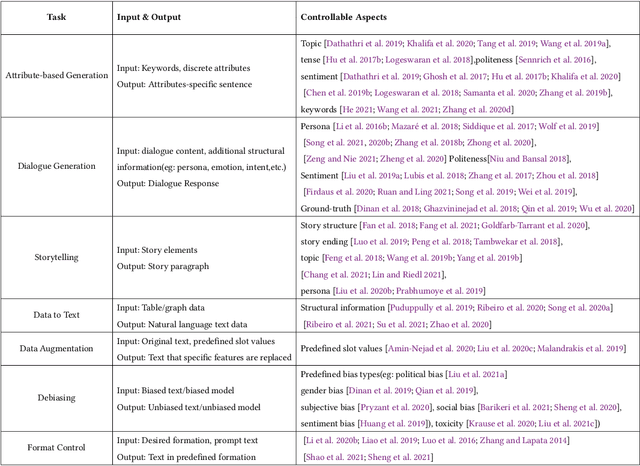
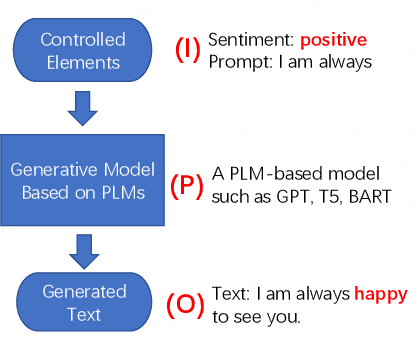
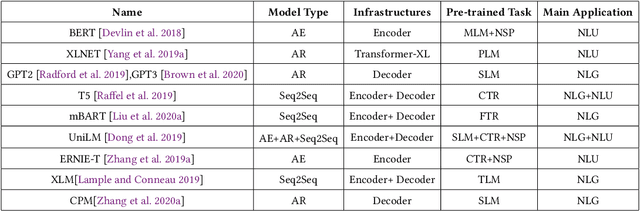
Controllable Text Generation (CTG) is emerging area in the field of natural language generation (NLG). It is regarded as crucial for the development of advanced text generation technologies that are more natural and better meet the specific constraints in practical applications. In recent years, methods using large-scale pre-trained language models (PLMs), in particular the widely used transformer-based PLMs, have become a new paradigm of NLG, allowing generation of more diverse and fluent text. However, due to the lower level of interpretability of deep neural networks, the controllability of these methods need to be guaranteed. To this end, controllable text generation using transformer-based PLMs has become a rapidly growing yet challenging new research hotspot. A diverse range of approaches have emerged in the recent 3-4 years, targeting different CTG tasks which may require different types of controlled constraints. In this paper, we present a systematic critical review on the common tasks, main approaches and evaluation methods in this area. Finally, we discuss the challenges that the field is facing, and put forward various promising future directions. To the best of our knowledge, this is the first survey paper to summarize CTG techniques from the perspective of PLMs. We hope it can help researchers in related fields to quickly track the academic frontier, providing them with a landscape of the area and a roadmap for future research.
End-to-end Emotion-Cause Pair Extraction via Learning to Link
Feb 25, 2020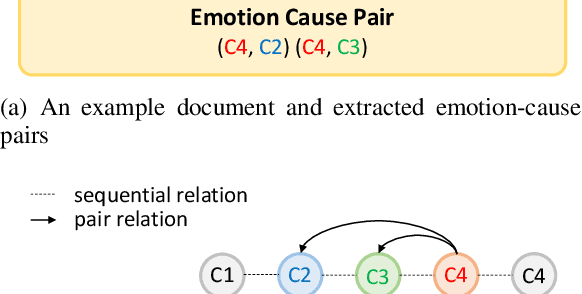
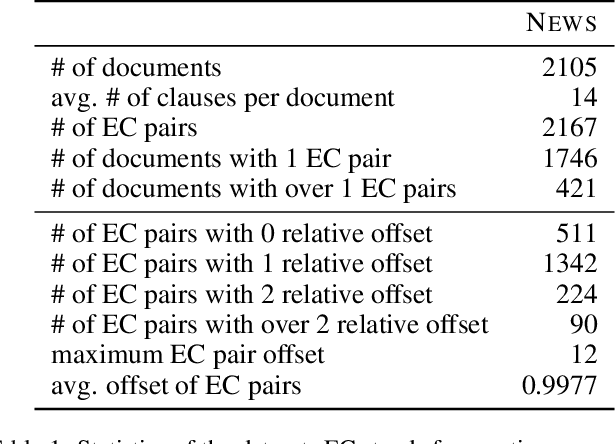
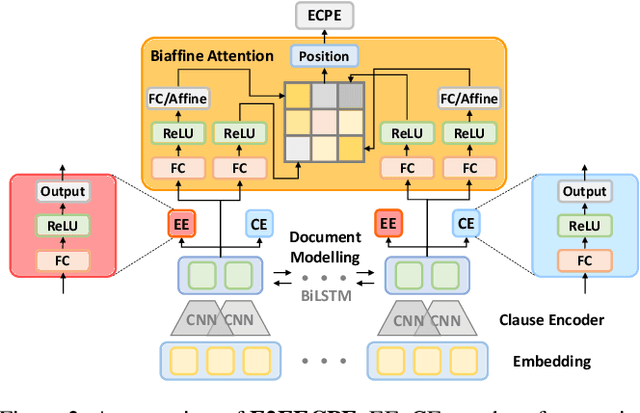
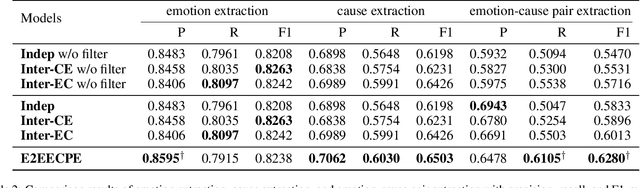
Emotion-cause pair extraction (ECPE), as an emergent natural language processing task, aims at jointly investigating emotions and their underlying causes in documents. It extends the previous emotion cause extraction (ECE) task, yet without requiring a set of pre-given emotion clauses as in ECE. Existing approaches to ECPE generally adopt a two-stage method, i.e., (1) emotion and cause detection, and then (2) pairing the detected emotions and causes. Such pipeline method, while intuitive, suffers from two critical issues, including error propagation across stages that may hinder the effectiveness, and high computational cost that would limit the practical application of the method. To tackle these issues, we propose a multi-task learning model that can extract emotions, causes and emotion-cause pairs simultaneously in an end-to-end manner. Specifically, our model regards pair extraction as a link prediction task, and learns to link from emotion clauses to cause clauses, i.e., the links are directional. Emotion extraction and cause extraction are incorporated into the model as auxiliary tasks, which further boost the pair extraction. Experiments are conducted on an ECPE benchmarking dataset. The results show that our proposed model outperforms a range of state-of-the-art approaches in terms of both effectiveness and efficiency.