 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMA2CL:Masked Attentive Contrastive Learning for Multi-Agent Reinforcement Learning
Jun 03, 2023



Recent approaches have utilized self-supervised auxiliary tasks as representation learning to improve the performance and sample efficiency of vision-based reinforcement learning algorithms in single-agent settings. However, in multi-agent reinforcement learning (MARL), these techniques face challenges because each agent only receives partial observation from an environment influenced by others, resulting in correlated observations in the agent dimension. So it is necessary to consider agent-level information in representation learning for MARL. In this paper, we propose an effective framework called \textbf{M}ulti-\textbf{A}gent \textbf{M}asked \textbf{A}ttentive \textbf{C}ontrastive \textbf{L}earning (MA2CL), which encourages learning representation to be both temporal and agent-level predictive by reconstructing the masked agent observation in latent space. Specifically, we use an attention reconstruction model for recovering and the model is trained via contrastive learning. MA2CL allows better utilization of contextual information at the agent level, facilitating the training of MARL agents for cooperation tasks. Extensive experiments demonstrate that our method significantly improves the performance and sample efficiency of different MARL algorithms and outperforms other methods in various vision-based and state-based scenarios. Our code can be found in \url{https://github.com/ustchlsong/MA2CL}
H-TSP: Hierarchically Solving the Large-Scale Travelling Salesman Problem
Apr 19, 2023



We propose an end-to-end learning framework based on hierarchical reinforcement learning, called H-TSP, for addressing the large-scale Travelling Salesman Problem (TSP). The proposed H-TSP constructs a solution of a TSP instance starting from the scratch relying on two components: the upper-level policy chooses a small subset of nodes (up to 200 in our experiment) from all nodes that are to be traversed, while the lower-level policy takes the chosen nodes as input and outputs a tour connecting them to the existing partial route (initially only containing the depot). After jointly training the upper-level and lower-level policies, our approach can directly generate solutions for the given TSP instances without relying on any time-consuming search procedures. To demonstrate effectiveness of the proposed approach, we have conducted extensive experiments on randomly generated TSP instances with different numbers of nodes. We show that H-TSP can achieve comparable results (gap 3.42% vs. 7.32%) as SOTA search-based approaches, and more importantly, we reduce the time consumption up to two orders of magnitude (3.32s vs. 395.85s). To the best of our knowledge, H-TSP is the first end-to-end deep reinforcement learning approach that can scale to TSP instances of up to 10000 nodes. Although there are still gaps to SOTA results with respect to solution quality, we believe that H-TSP will be useful for practical applications, particularly those that are time-sensitive e.g., on-call routing and ride hailing service.
Multi-Agent Reinforcement Learning with Shared Resources for Inventory Management
Dec 18, 2022



In this paper, we consider the inventory management (IM) problem where we need to make replenishment decisions for a large number of stock keeping units (SKUs) to balance their supply and demand. In our setting, the constraint on the shared resources (such as the inventory capacity) couples the otherwise independent control for each SKU. We formulate the problem with this structure as Shared-Resource Stochastic Game (SRSG)and propose an efficient algorithm called Context-aware Decentralized PPO (CD-PPO). Through extensive experiments, we demonstrate that CD-PPO can accelerate the learning procedure compared with standard MARL algorithms.
Stabilizing Voltage in Power Distribution Networks via Multi-Agent Reinforcement Learning with Transformer
Jun 08, 2022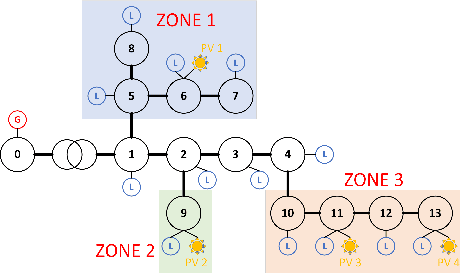
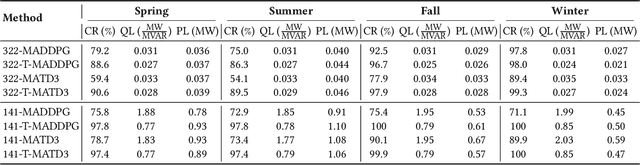
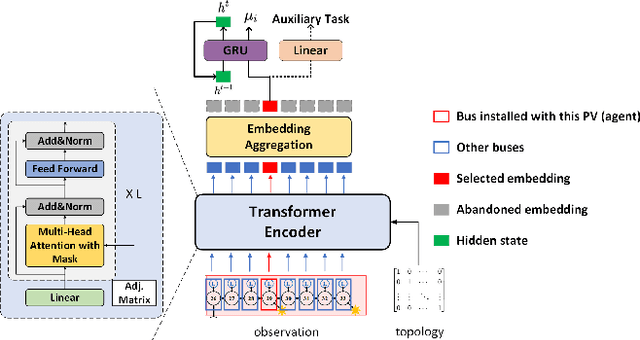
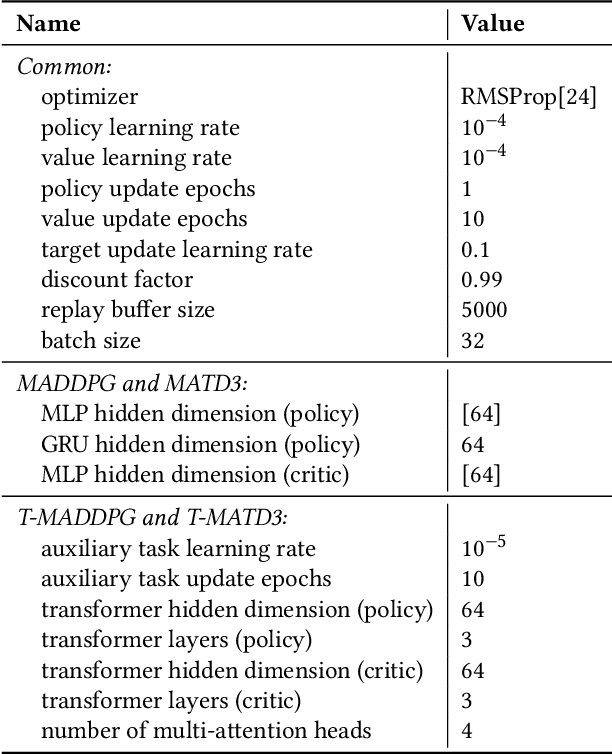
The increased integration of renewable energy poses a slew of technical challenges for the operation of power distribution networks. Among them, voltage fluctuations caused by the instability of renewable energy are receiving increasing attention. Utilizing MARL algorithms to coordinate multiple control units in the grid, which is able to handle rapid changes of power systems, has been widely studied in active voltage control task recently. However, existing approaches based on MARL ignore the unique nature of the grid and achieve limited performance. In this paper, we introduce the transformer architecture to extract representations adapting to power network problems and propose a Transformer-based Multi-Agent Actor-Critic framework (T-MAAC) to stabilize voltage in power distribution networks. In addition, we adopt a novel auxiliary-task training process tailored to the voltage control task, which improves the sample efficiency and facilitating the representation learning of the transformer-based model. We couple T-MAAC with different multi-agent actor-critic algorithms, and the consistent improvements on the active voltage control task demonstrate the effectiveness of the proposed method.
PlayVirtual: Augmenting Cycle-Consistent Virtual Trajectories for Reinforcement Learning
Jun 08, 2021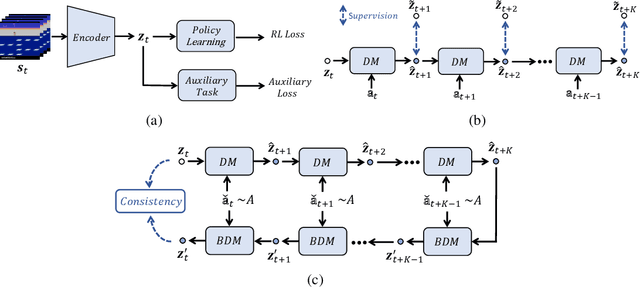
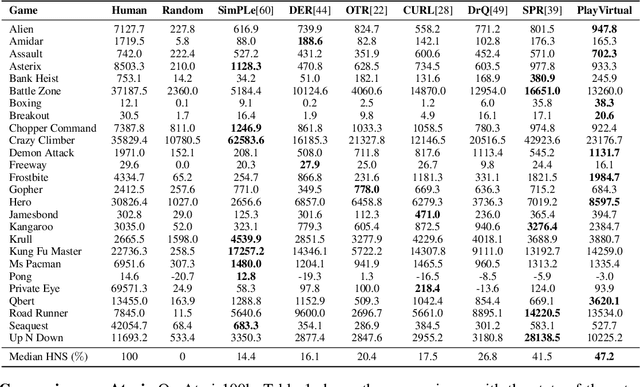

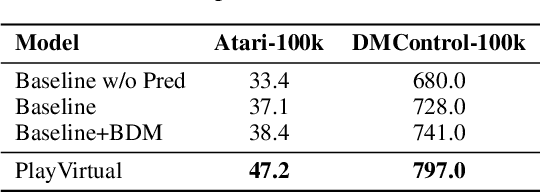
Learning good feature representations is important for deep reinforcement learning (RL). However, with limited experience, RL often suffers from data inefficiency for training. For un-experienced or less-experienced trajectories (i.e., state-action sequences), the lack of data limits the use of them for better feature learning. In this work, we propose a novel method, dubbed PlayVirtual, which augments cycle-consistent virtual trajectories to enhance the data efficiency for RL feature representation learning. Specifically, PlayVirtual predicts future states based on the current state and action by a dynamics model and then predicts the previous states by a backward dynamics model, which forms a trajectory cycle. Based on this, we augment the actions to generate a large amount of virtual state-action trajectories. Being free of groudtruth state supervision, we enforce a trajectory to meet the cycle consistency constraint, which can significantly enhance the data efficiency. We validate the effectiveness of our designs on the Atari and DeepMind Control Suite benchmarks. Our method outperforms the current state-of-the-art methods by a large margin on both benchmarks.