 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Less, Know More: State-Aware Reasoning Compression with Knowledge Guidance for Efficient Reasoning
Apr 10, 2026Large Reasoning Models (LRMs) achieve strong performance on complex tasks by leveraging long Chain-of-Thought (CoT), but often suffer from overthinking, leading to excessive reasoning steps and high inference latency. Existing CoT compression methods struggle to balance accuracy and efficiency, and lack fine-grained, step-level adaptation to redundancy and reasoning bias. Therefore, we propose State-Aware Reasoning Compression with Knowledge Guidance (STACK), a framework that performs step-wise CoT compression by explicitly modeling stage-specific redundancy sources and integrating with a retrieval-augmented guidance. STACK constructs online long-short contrastive samples and dynamically switches between knowledge-guided compression for uncertain or biased reasoning state and self-prompted compression for overly long but confident state, complemented by an answer-convergence-based early stopping mechanism to suppress redundant verification. We further propose a reward-difference-driven training strategy by combining Proximal Policy Optimization (PPO) and Direct Preference Optimization (DPO), enabling models to learn state-conditioned compression strategies. Experiments on three mathematical reasoning benchmarks show that STACK achieves a superior accuracy-efficiency balance, reducing average response length by 59.9% while improving accuracy by 4.8 points over existing methods.
Beyond Literal Mapping: Benchmarking and Improving Non-Literal Translation Evaluation
Jan 12, 2026Large Language Models (LLMs) have significantly advanced Machine Translation (MT), applying them to linguistically complex domains-such as Social Network Services, literature etc. In these scenarios, translations often require handling non-literal expressions, leading to the inaccuracy of MT metrics. To systematically investigate the reliability of MT metrics, we first curate a meta-evaluation dataset focused on non-literal translations, namely MENT. MENT encompasses four non-literal translation domains and features source sentences paired with translations from diverse MT systems, with 7,530 human-annotated scores on translation quality. Experimental results reveal the inaccuracies of traditional MT metrics and the limitations of LLM-as-a-Judge, particularly the knowledge cutoff and score inconsistency problem. To mitigate these limitations, we propose RATE, a novel agentic translation evaluation framework, centered by a reflective Core Agent that dynamically invokes specialized sub-agents. Experimental results indicate the efficacy of RATE, achieving an improvement of at least 3.2 meta score compared with current metrics. Further experiments demonstrate the robustness of RATE to general-domain MT evaluation. Code and dataset are available at: https://github.com/BITHLP/RATE.
ZigzagAttention: Efficient Long-Context Inference with Exclusive Retrieval and Streaming Heads
Aug 17, 2025With the rapid development of large language models (LLMs), handling long context has become one of the vital abilities in LLMs. Such long-context ability is accompanied by difficulties in deployment, especially due to the increased consumption of KV cache. There is certain work aiming to optimize the memory footprint of KV cache, inspired by the observation that attention heads can be categorized into retrieval heads that are of great significance and streaming heads that are of less significance. Typically, identifying the streaming heads and and waiving the KV cache in the streaming heads would largely reduce the overhead without hurting the performance that much. However, since employing both retrieval and streaming heads in one layer decomposes one large round of attention computation into two small ones, it may unexpectedly bring extra latency on accessing and indexing tensors. Based on this intuition, we impose an important improvement to the identification process of retrieval and streaming heads, in which we design a criterion that enforces exclusively retrieval or streaming heads gathered in one unique layer. In this way, we further eliminate the extra latency and only incur negligible performance degradation. Our method named \textsc{ZigzagAttention} is competitive among considered baselines owing to reduced latency and comparable performance.
MALM: A Multi-Information Adapter for Large Language Models to Mitigate Hallucination
Jun 14, 2025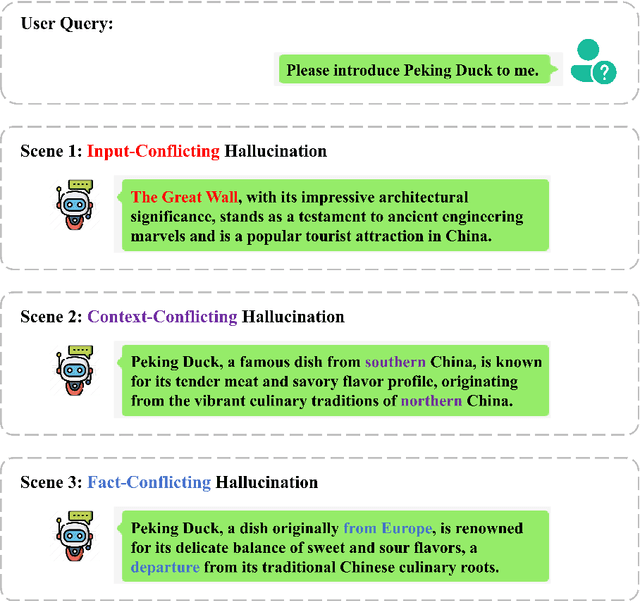

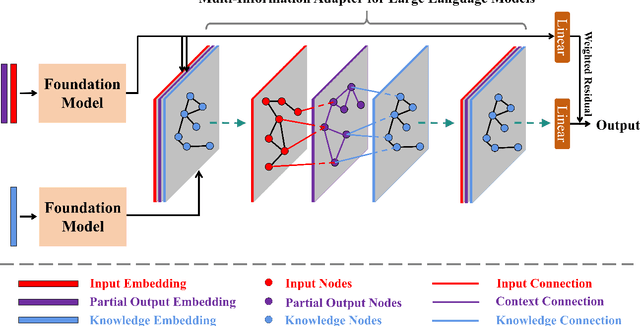

Large language models (LLMs) are prone to three types of hallucination: Input-Conflicting, Context-Conflicting and Fact-Conflicting hallucinations. The purpose of this study is to mitigate the different types of hallucination by exploiting the interdependence between them. For this purpose, we propose a Multi-Information Adapter for Large Language Models (MALM). This framework employs a tailored multi-graph learning approach designed to elucidate the interconnections between original inputs, contextual information, and external factual knowledge, thereby alleviating the three categories of hallucination within a cohesive framework. Experiments were carried out on four benchmarking datasets: HaluEval, TruthfulQA, Natural Questions, and TriviaQA. We evaluated the proposed framework in two aspects: (1) adaptability to different base LLMs on HaluEval and TruthfulQA, to confirm if MALM is effective when applied on 7 typical LLMs. MALM showed significant improvements over LLaMA-2; (2) generalizability to retrieval-augmented generation (RAG) by combining MALM with three representative retrievers (BM25, Spider and DPR) separately. Furthermore, automated and human evaluations were conducted to substantiate the correctness of experimental results, where GPT-4 and 3 human volunteers judged which response was better between LLaMA-2 and MALM. The results showed that both GPT-4 and human preferred MALM in 79.4% and 65.6% of cases respectively. The results validate that incorporating the complex interactions between the three types of hallucination through a multilayered graph attention network into the LLM generation process is effective to mitigate the them. The adapter design of the proposed approach is also proven flexible and robust across different base LLMs.
MoDification: Mixture of Depths Made Easy
Oct 18, 2024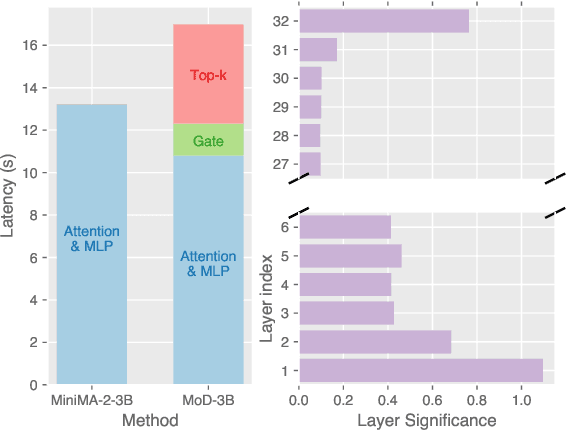
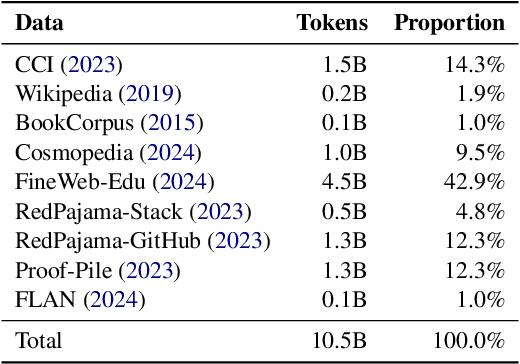
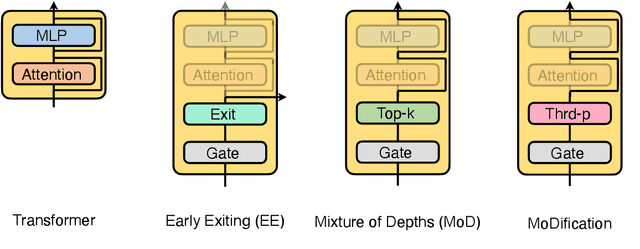
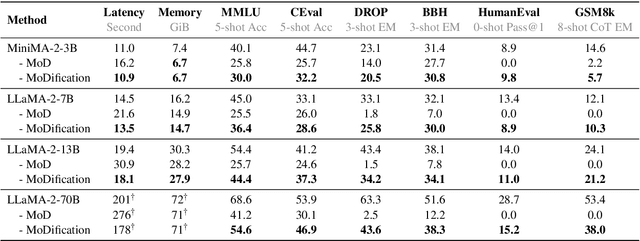
Long-context efficiency has recently become a trending topic in serving large language models (LLMs). And mixture of depths (MoD) is proposed as a perfect fit to bring down both latency and memory. In this paper, however, we discover that MoD can barely transform existing LLMs without costly training over an extensive number of tokens. To enable the transformations from any LLMs to MoD ones, we showcase top-k operator in MoD should be promoted to threshold-p operator, and refinement to architecture and data should also be crafted along. All these designs form our method termed MoDification. Through a comprehensive set of experiments covering model scales from 3B to 70B, we exhibit MoDification strikes an excellent balance between efficiency and effectiveness. MoDification can achieve up to ~1.2x speedup in latency and ~1.8x reduction in memory compared to original LLMs especially in long-context applications.
Investigating Context Effects in Similarity Judgements in Large Language Models
Aug 20, 2024



Large Language Models (LLMs) have revolutionised the capability of AI models in comprehending and generating natural language text. They are increasingly being used to empower and deploy agents in real-world scenarios, which make decisions and take actions based on their understanding of the context. Therefore researchers, policy makers and enterprises alike are working towards ensuring that the decisions made by these agents align with human values and user expectations. That being said, human values and decisions are not always straightforward to measure and are subject to different cognitive biases. There is a vast section of literature in Behavioural Science which studies biases in human judgements. In this work we report an ongoing investigation on alignment of LLMs with human judgements affected by order bias. Specifically, we focus on a famous human study which showed evidence of order effects in similarity judgements, and replicate it with various popular LLMs. We report the different settings where LLMs exhibit human-like order effect bias and discuss the implications of these findings to inform the design and development of LLM based applications.
Bi-DCSpell: A Bi-directional Detector-Corrector Interactive Framework for Chinese Spelling Check
Jun 04, 2024



Chinese Spelling Check (CSC) aims to detect and correct potentially misspelled characters in Chinese sentences. Naturally, it involves the detection and correction subtasks, which interact with each other dynamically. Such interactions are bi-directional, i.e., the detection result would help reduce the risk of over-correction and under-correction while the knowledge learnt from correction would help prevent false detection. Current CSC approaches are of two types: correction-only or single-directional detection-to-correction interactive frameworks. Nonetheless, they overlook the bi-directional interactions between detection and correction. This paper aims to fill the gap by proposing a Bi-directional Detector-Corrector framework for CSC (Bi-DCSpell). Notably, Bi-DCSpell contains separate detection and correction encoders, followed by a novel interactive learning module facilitating bi-directional feature interactions between detection and correction to improve each other's representation learning. Extensive experimental results demonstrate a robust correction performance of Bi-DCSpell on widely used benchmarking datasets while possessing a satisfactory detection ability.
A Supervised Information Enhanced Multi-Granularity Contrastive Learning Framework for EEG Based Emotion Recognition
May 12, 2024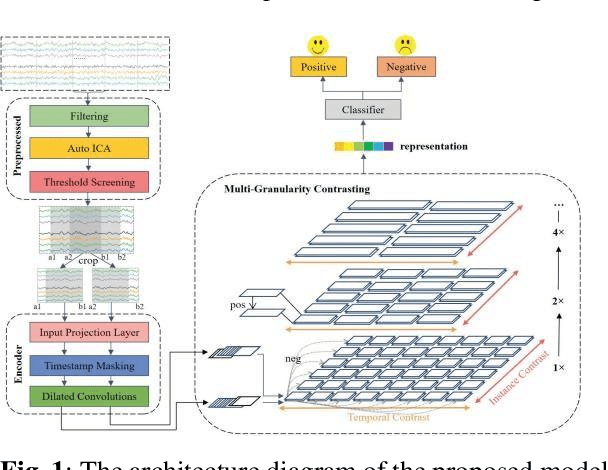
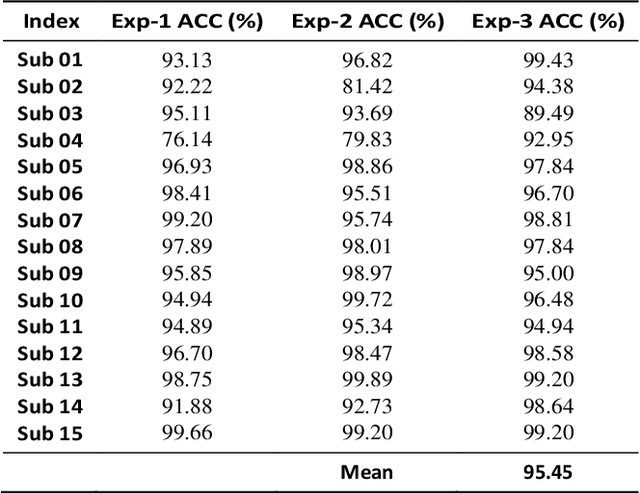
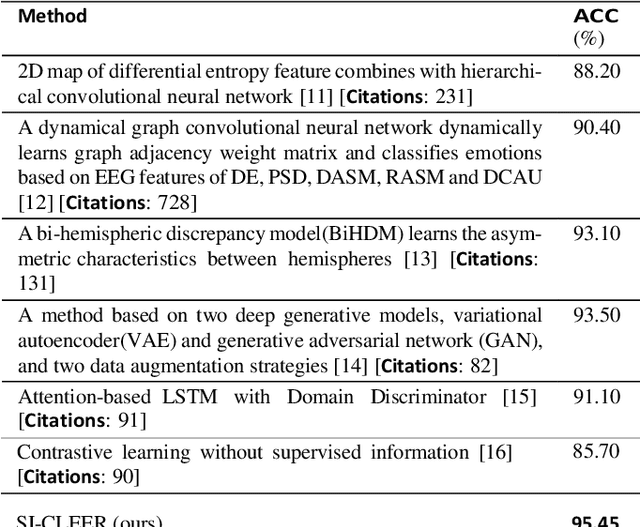
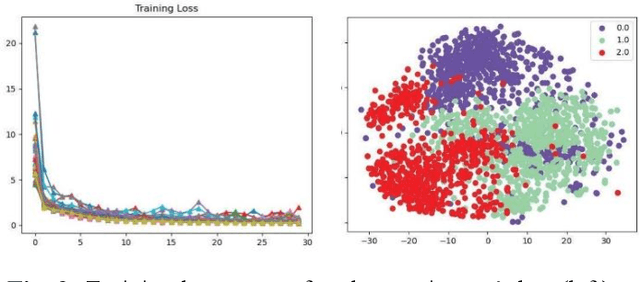
This study introduces a novel Supervised Info-enhanced Contrastive Learning framework for EEG based Emotion Recognition (SICLEER). SI-CLEER employs multi-granularity contrastive learning to create robust EEG contextual representations, potentiallyn improving emotion recognition effectiveness. Unlike existing methods solely guided by classification loss, we propose a joint learning model combining self-supervised contrastive learning loss and supervised classification loss. This model optimizes both loss functions, capturing subtle EEG signal differences specific to emotion detection. Extensive experiments demonstrate SI-CLEER's robustness and superior accuracy on the SEED dataset compared to state-of-the-art methods. Furthermore, we analyze electrode performance, highlighting the significance of central frontal and temporal brain region EEGs in emotion detection. This study offers an universally applicable approach with potential benefits for diverse EEG classification tasks.
Beyond the Speculative Game: A Survey of Speculative Execution in Large Language Models
Apr 23, 2024

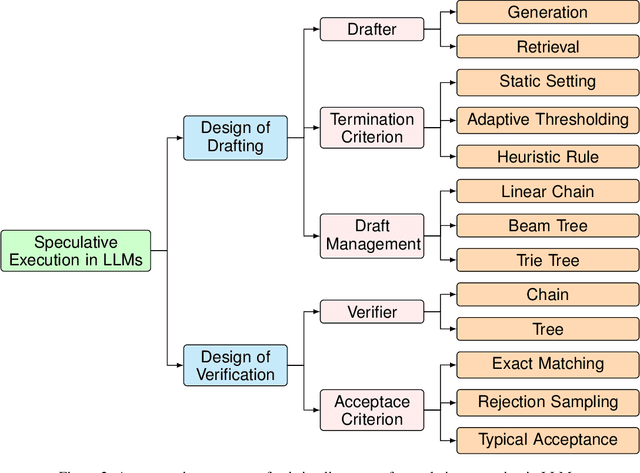

With the increasingly giant scales of (causal) large language models (LLMs), the inference efficiency comes as one of the core concerns along the improved performance. In contrast to the memory footprint, the latency bottleneck seems to be of greater importance as there can be billions of requests to a LLM (e.g., GPT-4) per day. The bottleneck is mainly due to the autoregressive innateness of LLMs, where tokens can only be generated sequentially during decoding. To alleviate the bottleneck, the idea of speculative execution, which originates from the field of computer architecture, is introduced to LLM decoding in a \textit{draft-then-verify} style. Under this regime, a sequence of tokens will be drafted in a fast pace by utilizing some heuristics, and then the tokens shall be verified in parallel by the LLM. As the costly sequential inference is parallelized, LLM decoding speed can be significantly boosted. Driven by the success of LLMs in recent couple of years, a growing literature in this direction has emerged. Yet, there lacks a position survey to summarize the current landscape and draw a roadmap for future development of this promising area. To meet this demand, we present the very first survey paper that reviews and unifies literature of speculative execution in LLMs (e.g., blockwise parallel decoding, speculative decoding, etc.) in a comprehensive framework and a systematic taxonomy. Based on the taxonomy, we present a critical review and comparative analysis of the current arts. Finally we highlight various key challenges and future directions to further develop the area.
LLM-Oriented Retrieval Tuner
Mar 04, 2024



Dense Retrieval (DR) is now considered as a promising tool to enhance the memorization capacity of Large Language Models (LLM) such as GPT3 and GPT-4 by incorporating external memories. However, due to the paradigm discrepancy between text generation of LLM and DR, it is still an open challenge to integrate the retrieval and generation tasks in a shared LLM. In this paper, we propose an efficient LLM-Oriented Retrieval Tuner, namely LMORT, which decouples DR capacity from base LLM and non-invasively coordinates the optimally aligned and uniform layers of the LLM towards a unified DR space, achieving an efficient and effective DR without tuning the LLM itself. The extensive experiments on six BEIR datasets show that our approach could achieve competitive zero-shot retrieval performance compared to a range of strong DR models while maintaining the generation ability of LLM.