 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyFlow: Safe and Efficient Polytope-Constrained Flow Matching with Constraint Embedding and Projection-free Update
Jun 11, 2026While flow-based generative models have demonstrated strong performance across a wide range of domains, deploying them in safety-critical physical systems remains challenging due to strict constraint requirements. Existing approaches typically enforce safety through post-hoc corrections, which incur substantial computational overhead and may distort the learned distribution. We propose PolyFlow, a polytope-constrained flow matching framework that embeds constraints directly into the model and flow dynamics. PolyFlow introduces a discrete-time flow formulation and a projection-free architecture, which eliminate the discretization error and guarantee strict satisfaction of arbitrary polyhedral constraints, without the need for expensive iterative solvers. Experimental results show that PolyFlow achieves zero constraint violation while maintaining high distributional fidelity across a range of planning and control tasks. Compared to state-of-the-art constrained generation baselines, PolyFlow significantly reduces inference latency and demonstrates a favorable trade-off between safety, efficiency, and generative quality. Code is available on https://github.com/MJianM/PolyFlow.
TextReasoningBench: Does Reasoning Really Improve Text Classification in Large Language Models?
Mar 20, 2026Eliciting explicit, step-by-step reasoning traces from large language models (LLMs) has emerged as a dominant paradigm for enhancing model capabilities. Although such reasoning strategies were originally designed for problems requiring explicit multi-step reasoning, they have increasingly been applied to a broad range of NLP tasks. This expansion implicitly assumes that deliberative reasoning uniformly benefits heterogeneous tasks. However, whether such reasoning mechanisms truly benefit classification tasks remains largely underexplored, especially considering their substantial token and time costs. To fill this gap, we introduce TextReasoningBench, a systematic benchmark designed to evaluate the effectiveness and efficiency of reasoning strategies for text classification with LLMs. We compare seven reasoning strategies, namely IO, CoT, SC-CoT, ToT, GoT, BoC, and long-CoT across ten LLMs on five text classification datasets. Beyond traditional metrics such as accuracy and macro-F1, we introduce two cost-aware evaluation metrics that quantify the performance gain per reasoning token and the efficiency of performance improvement relative to token cost growth. Experimental results reveal three notable findings: (1) Reasoning does not universally improve classification performance: while moderate strategies such as CoT and SC-CoT yield consistent but limited gains (typically +1% to +3% on big models), more complex methods (e.g., ToT and GoT) often fail to outperform simpler baselines and can even degrade performance, especially on small models; (2) Reasoning is often inefficient: many reasoning strategies increase token consumption by 10$\times$ to 100$\times$ (e.g., SC-CoT and ToT) while providing only marginal performance improvements.
FocusNav: Spatial Selective Attention with Waypoint Guidance for Humanoid Local Navigation
Jan 19, 2026Robust local navigation in unstructured and dynamic environments remains a significant challenge for humanoid robots, requiring a delicate balance between long-range navigation targets and immediate motion stability. In this paper, we propose FocusNav, a spatial selective attention framework that adaptively modulates the robot's perceptual field based on navigational intent and real-time stability. FocusNav features a Waypoint-Guided Spatial Cross-Attention (WGSCA) mechanism that anchors environmental feature aggregation to a sequence of predicted collision-free waypoints, ensuring task-relevant perception along the planned trajectory. To enhance robustness in complex terrains, the Stability-Aware Selective Gating (SASG) module autonomously truncates distal information when detecting instability, compelling the policy to prioritize immediate foothold safety. Extensive experiments on the Unitree G1 humanoid robot demonstrate that FocusNav significantly improves navigation success rates in challenging scenarios, outperforming baselines in both collision avoidance and motion stability, achieving robust navigation in dynamic and complex environments.
Large Emotional World Model
Dec 30, 2025World Models serve as tools for understanding the current state of the world and predicting its future dynamics, with broad application potential across numerous fields. As a key component of world knowledge, emotion significantly influences human decision-making. While existing Large Language Models (LLMs) have shown preliminary capability in capturing world knowledge, they primarily focus on modeling physical-world regularities and lack systematic exploration of emotional factors. In this paper, we first demonstrate the importance of emotion in understanding the world by showing that removing emotionally relevant information degrades reasoning performance. Inspired by theory of mind, we further propose a Large Emotional World Model (LEWM). Specifically, we construct the Emotion-Why-How (EWH) dataset, which integrates emotion into causal relationships and enables reasoning about why actions occur and how emotions drive future world states. Based on this dataset, LEWM explicitly models emotional states alongside visual observations and actions, allowing the world model to predict both future states and emotional transitions. Experimental results show that LEWM more accurately predicts emotion-driven social behaviors while maintaining comparable performance to general world models on basic tasks.
Visual Room 2.0: Seeing is Not Understanding for MLLMs
Nov 17, 2025Can multi-modal large language models (MLLMs) truly understand what they can see? Extending Searle's Chinese Room into the multi-modal domain, this paper proposes the Visual Room argument: MLLMs may describe every visual detail precisely yet fail to comprehend the underlying emotions and intentions, namely seeing is not understanding. Building on this, we introduce \textit{Visual Room} 2.0, a hierarchical benchmark for evaluating perception-cognition alignment of MLLMs. We model human perceptive and cognitive processes across three levels: low, middle, and high, covering 17 representative tasks. The perception component ranges from attribute recognition to scene understanding, while the cognition component extends from textual entailment to causal and social reasoning. The dataset contains 350 multi-modal samples, each with six progressive questions (2,100 in total) spanning perception to cognition. Evaluating 10 state-of-the-art (SoTA) MLLMs, we highlight three key findings: (1) MLLMs exhibit stronger perceptual competence than cognitive ability (8.0\%$\uparrow$); (2) cognition appears not causally dependent on perception-based reasoning; and (3) cognition scales with model size, but perception does not consistently improve with larger variants. This work operationalizes Seeing $\ne$ Understanding as a testable hypothesis, offering a new paradigm from perceptual processing to cognitive reasoning in MLLMs. Our dataset is available at https://huggingface.co/datasets/LHK2003/PCBench.
One Model for All: Universal Pre-training for EEG based Emotion Recognition across Heterogeneous Datasets and Paradigms
Nov 11, 2025EEG-based emotion recognition is hampered by profound dataset heterogeneity (channel/subject variability), hindering generalizable models. Existing approaches struggle to transfer knowledge effectively. We propose 'One Model for All', a universal pre-training framework for EEG analysis across disparate datasets. Our paradigm decouples learning into two stages: (1) Univariate pre-training via self-supervised contrastive learning on individual channels, enabled by a Unified Channel Schema (UCS) that leverages the channel union (e.g., SEED-62ch, DEAP-32ch); (2) Multivariate fine-tuning with a novel 'ART' (Adaptive Resampling Transformer) and 'GAT' (Graph Attention Network) architecture to capture complex spatio-temporal dependencies. Experiments show universal pre-training is an essential stabilizer, preventing collapse on SEED (vs. scratch) and yielding substantial gains on DEAP (+7.65%) and DREAMER (+3.55%). Our framework achieves new SOTA performance on all within-subject benchmarks: SEED (99.27%), DEAP (93.69%), and DREAMER (93.93%). We also show SOTA cross-dataset transfer, achieving 94.08% (intersection) and 93.05% (UCS) on the unseen DREAMER dataset, with the former surpassing the within-domain pre-training benchmark. Ablation studies validate our architecture: the GAT module is critical, yielding a +22.19% gain over GCN on the high-noise DEAP dataset, and its removal causes a catastrophic -16.44% performance drop. This work paves the way for more universal, scalable, and effective pre-trained models for diverse EEG analysis tasks.
Large Language Models for Subjective Language Understanding: A Survey
Aug 11, 2025Subjective language understanding refers to a broad set of natural language processing tasks where the goal is to interpret or generate content that conveys personal feelings, opinions, or figurative meanings rather than objective facts. With the advent of large language models (LLMs) such as ChatGPT, LLaMA, and others, there has been a paradigm shift in how we approach these inherently nuanced tasks. In this survey, we provide a comprehensive review of recent advances in applying LLMs to subjective language tasks, including sentiment analysis, emotion recognition, sarcasm detection, humor understanding, stance detection, metaphor interpretation, intent detection, and aesthetics assessment. We begin by clarifying the definition of subjective language from linguistic and cognitive perspectives, and we outline the unique challenges posed by subjective language (e.g. ambiguity, figurativeness, context dependence). We then survey the evolution of LLM architectures and techniques that particularly benefit subjectivity tasks, highlighting why LLMs are well-suited to model subtle human-like judgments. For each of the eight tasks, we summarize task definitions, key datasets, state-of-the-art LLM-based methods, and remaining challenges. We provide comparative insights, discussing commonalities and differences among tasks and how multi-task LLM approaches might yield unified models of subjectivity. Finally, we identify open issues such as data limitations, model bias, and ethical considerations, and suggest future research directions. We hope this survey will serve as a valuable resource for researchers and practitioners interested in the intersection of affective computing, figurative language processing, and large-scale language models.
Commander-GPT: Dividing and Routing for Multimodal Sarcasm Detection
Jun 24, 2025Multimodal sarcasm understanding is a high-order cognitive task. Although large language models (LLMs) have shown impressive performance on many downstream NLP tasks, growing evidence suggests that they struggle with sarcasm understanding. In this paper, we propose Commander-GPT, a modular decision routing framework inspired by military command theory. Rather than relying on a single LLM's capability, Commander-GPT orchestrates a team of specialized LLM agents where each agent will be selectively assigned to a focused sub-task such as context modeling, sentiment analysis, etc. Their outputs are then routed back to the commander, which integrates the information and performs the final sarcasm judgment. To coordinate these agents, we introduce three types of centralized commanders: (1) a trained lightweight encoder-based commander (e.g., multi-modal BERT); (2) four small autoregressive language models, serving as moderately capable commanders (e.g., DeepSeek-VL); (3) two large LLM-based commander (Gemini Pro and GPT-4o) that performs task routing, output aggregation, and sarcasm decision-making in a zero-shot fashion. We evaluate Commander-GPT on the MMSD and MMSD 2.0 benchmarks, comparing five prompting strategies. Experimental results show that our framework achieves 4.4% and 11.7% improvement in F1 score over state-of-the-art (SoTA) baselines on average, demonstrating its effectiveness.
MALM: A Multi-Information Adapter for Large Language Models to Mitigate Hallucination
Jun 14, 2025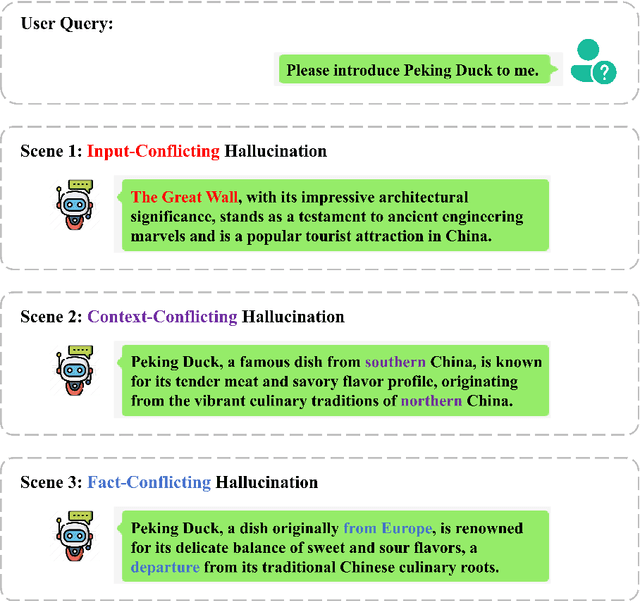

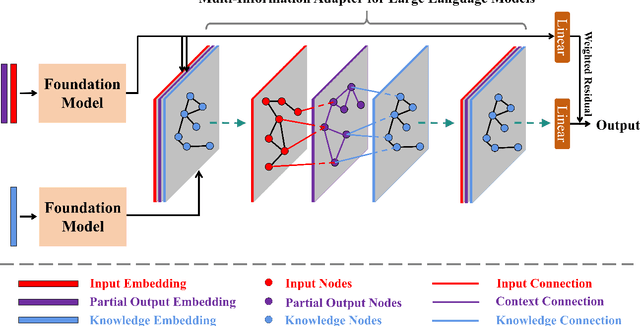

Large language models (LLMs) are prone to three types of hallucination: Input-Conflicting, Context-Conflicting and Fact-Conflicting hallucinations. The purpose of this study is to mitigate the different types of hallucination by exploiting the interdependence between them. For this purpose, we propose a Multi-Information Adapter for Large Language Models (MALM). This framework employs a tailored multi-graph learning approach designed to elucidate the interconnections between original inputs, contextual information, and external factual knowledge, thereby alleviating the three categories of hallucination within a cohesive framework. Experiments were carried out on four benchmarking datasets: HaluEval, TruthfulQA, Natural Questions, and TriviaQA. We evaluated the proposed framework in two aspects: (1) adaptability to different base LLMs on HaluEval and TruthfulQA, to confirm if MALM is effective when applied on 7 typical LLMs. MALM showed significant improvements over LLaMA-2; (2) generalizability to retrieval-augmented generation (RAG) by combining MALM with three representative retrievers (BM25, Spider and DPR) separately. Furthermore, automated and human evaluations were conducted to substantiate the correctness of experimental results, where GPT-4 and 3 human volunteers judged which response was better between LLaMA-2 and MALM. The results showed that both GPT-4 and human preferred MALM in 79.4% and 65.6% of cases respectively. The results validate that incorporating the complex interactions between the three types of hallucination through a multilayered graph attention network into the LLM generation process is effective to mitigate the them. The adapter design of the proposed approach is also proven flexible and robust across different base LLMs.
Are MLMs Trapped in the Visual Room?
May 29, 2025Can multi-modal large models (MLMs) that can ``see'' an image be said to ``understand'' it? Drawing inspiration from Searle's Chinese Room, we propose the \textbf{Visual Room} argument: a system may process and describe every detail of visual inputs by following algorithmic rules, without genuinely comprehending the underlying intention. This dilemma challenges the prevailing assumption that perceptual mastery implies genuine understanding. In implementation, we introduce a two-tier evaluation framework spanning perception and cognition. The perception component evaluates whether MLMs can accurately capture the surface-level details of visual contents, where the cognitive component examines their ability to infer sarcasm polarity. To support this framework, We further introduce a high-quality multi-modal sarcasm dataset comprising both 924 static images and 100 dynamic videos. All sarcasm labels are annotated by the original authors and verified by independent reviewers to ensure clarity and consistency. We evaluate eight state-of-the-art (SoTA) MLMs. Our results highlight three key findings: (1) MLMs perform well on perception tasks; (2) even with correct perception, models exhibit an average error rate of ~16.1\% in sarcasm understanding, revealing a significant gap between seeing and understanding; (3) error analysis attributes this gap to deficiencies in emotional reasoning, commonsense inference, and context alignment. This work provides empirical grounding for the proposed Visual Room argument and offers a new evaluation paradigm for MLMs.