 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComprehend and Talk: Text to Speech Synthesis via Dual Language Modeling
Sep 26, 2025Existing Large Language Model (LLM) based autoregressive (AR) text-to-speech (TTS) systems, while achieving state-of-the-art quality, still face critical challenges. The foundation of this LLM-based paradigm is the discretization of the continuous speech waveform into a sequence of discrete tokens by neural audio codec. However, single codebook modeling is well suited to text LLMs, but suffers from significant information loss; hierarchical acoustic tokens, typically generated via Residual Vector Quantization (RVQ), often lack explicit semantic structure, placing a heavy learning burden on the model. Furthermore, the autoregressive process is inherently susceptible to error accumulation, which can degrade generation stability. To address these limitations, we propose CaT-TTS, a novel framework for robust and semantically-grounded zero-shot synthesis. First, we introduce S3Codec, a split RVQ codec that injects explicit linguistic features into its primary codebook via semantic distillation from a state-of-the-art ASR model, providing a structured representation that simplifies the learning task. Second, we propose an ``Understand-then-Generate'' dual-Transformer architecture that decouples comprehension from rendering. An initial ``Understanding'' Transformer models the cross-modal relationship between text and the audio's semantic tokens to form a high-level utterance plan. A subsequent ``Generation'' Transformer then executes this plan, autoregressively synthesizing hierarchical acoustic tokens. Finally, to enhance generation stability, we introduce Masked Audio Parallel Inference (MAPI), a nearly parameter-free inference strategy that dynamically guides the decoding process to mitigate local errors.
Quantize More, Lose Less: Autoregressive Generation from Residually Quantized Speech Representations
Jul 16, 2025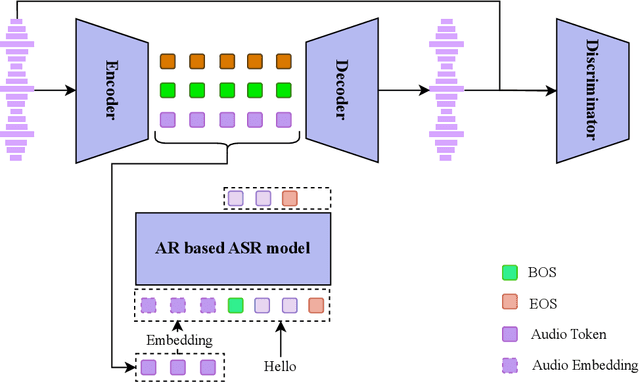

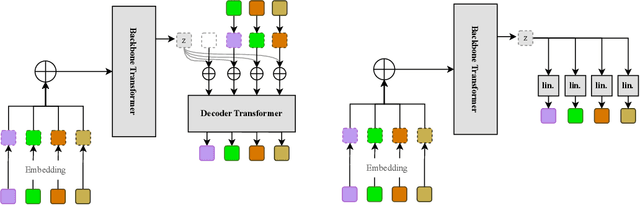
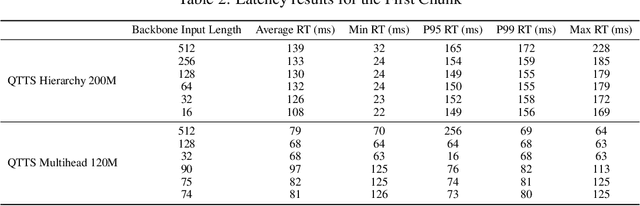
Text-to-speech (TTS) synthesis has seen renewed progress under the discrete modeling paradigm. Existing autoregressive approaches often rely on single-codebook representations, which suffer from significant information loss. Even with post-hoc refinement techniques such as flow matching, these methods fail to recover fine-grained details (e.g., prosodic nuances, speaker-specific timbres), especially in challenging scenarios like singing voice or music synthesis. We propose QTTS, a novel TTS framework built upon our new audio codec, QDAC. The core innovation of QDAC lies in its end-to-end training of an ASR-based auto-regressive network with a GAN, which achieves superior semantic feature disentanglement for scalable, near-lossless compression. QTTS models these discrete codes using two innovative strategies: the Hierarchical Parallel architecture, which uses a dual-AR structure to model inter-codebook dependencies for higher-quality synthesis, and the Delay Multihead approach, which employs parallelized prediction with a fixed delay to accelerate inference speed. Our experiments demonstrate that the proposed framework achieves higher synthesis quality and better preserves expressive content compared to baseline. This suggests that scaling up compression via multi-codebook modeling is a promising direction for high-fidelity, general-purpose speech and audio generation.
Frame-level emotional state alignment method for speech emotion recognition
Dec 27, 2023Speech emotion recognition (SER) systems aim to recognize human emotional state during human-computer interaction. Most existing SER systems are trained based on utterance-level labels. However, not all frames in an audio have affective states consistent with utterance-level label, which makes it difficult for the model to distinguish the true emotion of the audio and perform poorly. To address this problem, we propose a frame-level emotional state alignment method for SER. First, we fine-tune HuBERT model to obtain a SER system with task-adaptive pretraining (TAPT) method, and extract embeddings from its transformer layers to form frame-level pseudo-emotion labels with clustering. Then, the pseudo labels are used to pretrain HuBERT. Hence, the each frame output of HuBERT has corresponding emotional information. Finally, we fine-tune the above pretrained HuBERT for SER by adding an attention layer on the top of it, which can focus only on those frames that are emotionally more consistent with utterance-level label. The experimental results performed on IEMOCAP indicate that our proposed method performs better than state-of-the-art (SOTA) methods.
CONCSS: Contrastive-based Context Comprehension for Dialogue-appropriate Prosody in Conversational Speech Synthesis
Dec 16, 2023Conversational speech synthesis (CSS) incorporates historical dialogue as supplementary information with the aim of generating speech that has dialogue-appropriate prosody. While previous methods have already delved into enhancing context comprehension, context representation still lacks effective representation capabilities and context-sensitive discriminability. In this paper, we introduce a contrastive learning-based CSS framework, CONCSS. Within this framework, we define an innovative pretext task specific to CSS that enables the model to perform self-supervised learning on unlabeled conversational datasets to boost the model's context understanding. Additionally, we introduce a sampling strategy for negative sample augmentation to enhance context vectors' discriminability. This is the first attempt to integrate contrastive learning into CSS. We conduct ablation studies on different contrastive learning strategies and comprehensive experiments in comparison with prior CSS systems. Results demonstrate that the synthesized speech from our proposed method exhibits more contextually appropriate and sensitive prosody.
A Keypoint Based Enhancement Method for Audio Driven Free View Talking Head Synthesis
Oct 07, 2022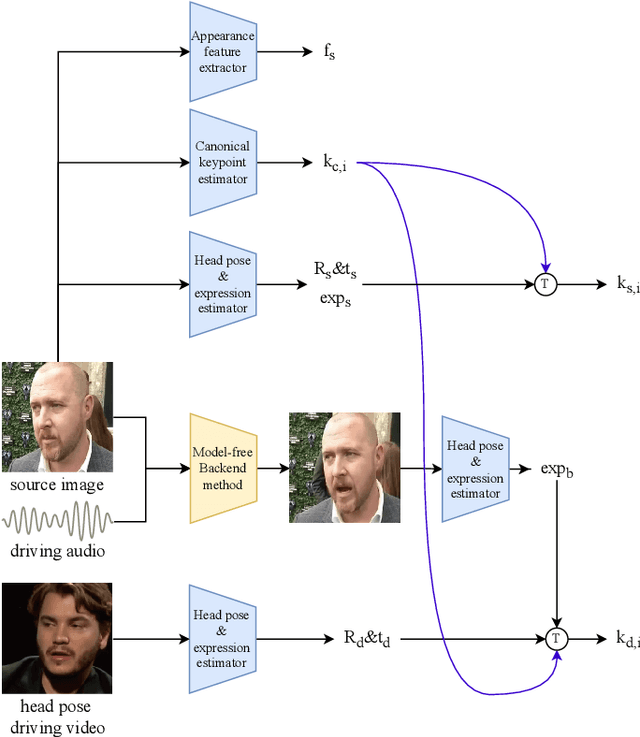
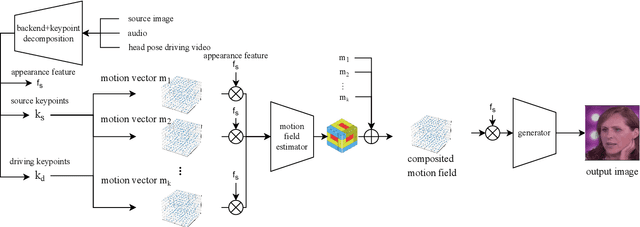


Audio driven talking head synthesis is a challenging task that attracts increasing attention in recent years. Although existing methods based on 2D landmarks or 3D face models can synthesize accurate lip synchronization and rhythmic head pose for arbitrary identity, they still have limitations, such as the cut feeling in the mouth mapping and the lack of skin highlights. The morphed region is blurry compared to the surrounding face. A Keypoint Based Enhancement (KPBE) method is proposed for audio driven free view talking head synthesis to improve the naturalness of the generated video. Firstly, existing methods were used as the backend to synthesize intermediate results. Then we used keypoint decomposition to extract video synthesis controlling parameters from the backend output and the source image. After that, the controlling parameters were composited to the source keypoints and the driving keypoints. A motion field based method was used to generate the final image from the keypoint representation. With keypoint representation, we overcame the cut feeling in the mouth mapping and the lack of skin highlights. Experiments show that our proposed enhancement method improved the quality of talking-head videos in terms of mean opinion score.
ECAPA-TDNN for Multi-speaker Text-to-speech Synthesis
Mar 26, 2022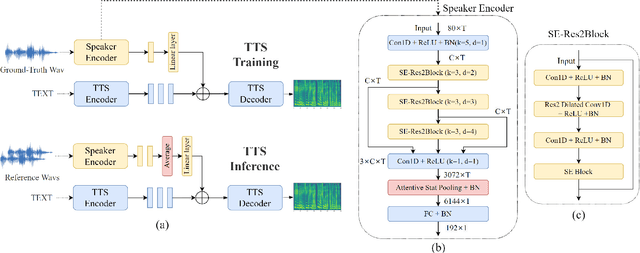
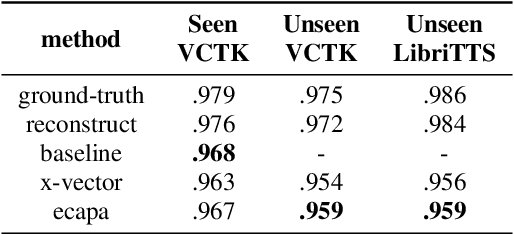
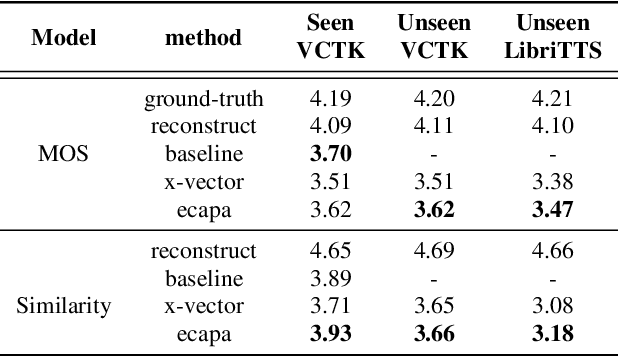
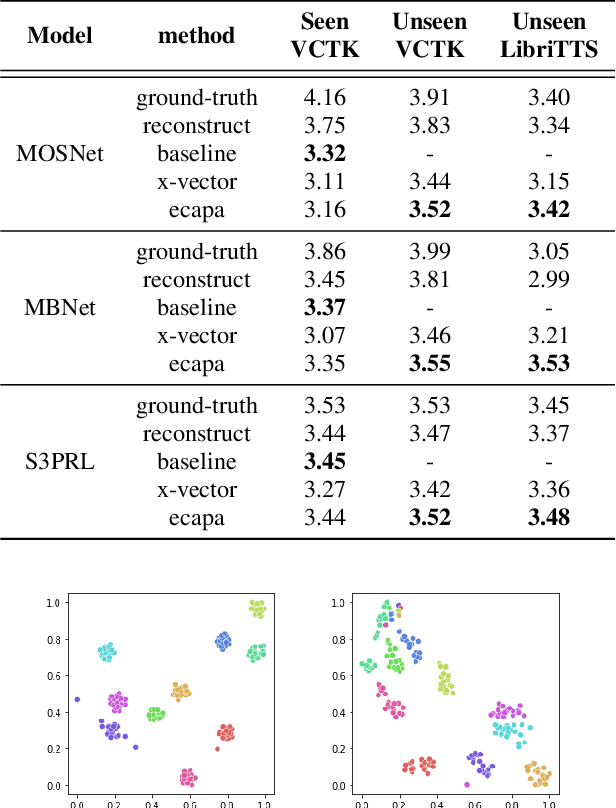
In recent years, neural network based methods for multi-speaker text-to-speech synthesis (TTS) have made significant progress. However, the current speaker encoder models used in these methods still cannot capture enough speaker information. In this paper, we focus on accurate speaker encoder modeling and propose an end-to-end method that can generate high-quality speech and better similarity for both seen and unseen speakers. The proposed architecture consists of three separately trained components: a speaker encoder based on the state-of-the-art ECAPA-TDNN model which is derived from speaker verification task, a FastSpeech2 based synthesizer, and a HiFi-GAN vocoder. The comparison among different speaker encoder models shows our proposed method can achieve better naturalness and similarity. To efficiently evaluate our synthesized speech, we are the first to adopt deep learning based automatic MOS evaluation methods to assess our results, and these methods show great potential in automatic speech quality assessment.