 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Keypoint Based Enhancement Method for Audio Driven Free View Talking Head Synthesis
Oct 07, 2022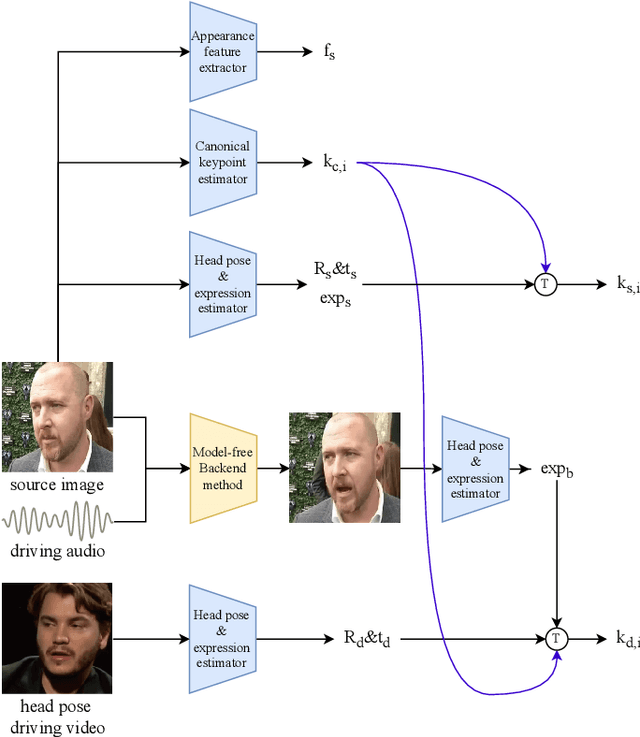
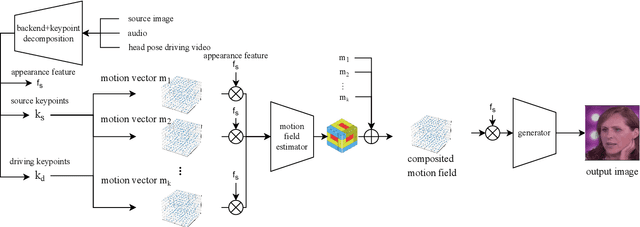


Audio driven talking head synthesis is a challenging task that attracts increasing attention in recent years. Although existing methods based on 2D landmarks or 3D face models can synthesize accurate lip synchronization and rhythmic head pose for arbitrary identity, they still have limitations, such as the cut feeling in the mouth mapping and the lack of skin highlights. The morphed region is blurry compared to the surrounding face. A Keypoint Based Enhancement (KPBE) method is proposed for audio driven free view talking head synthesis to improve the naturalness of the generated video. Firstly, existing methods were used as the backend to synthesize intermediate results. Then we used keypoint decomposition to extract video synthesis controlling parameters from the backend output and the source image. After that, the controlling parameters were composited to the source keypoints and the driving keypoints. A motion field based method was used to generate the final image from the keypoint representation. With keypoint representation, we overcame the cut feeling in the mouth mapping and the lack of skin highlights. Experiments show that our proposed enhancement method improved the quality of talking-head videos in terms of mean opinion score.