 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRectify Evaluation Preference: Improving LLMs' Critique on Math Reasoning via Perplexity-aware Reinforcement Learning
Nov 13, 2025To improve Multi-step Mathematical Reasoning (MsMR) of Large Language Models (LLMs), it is crucial to obtain scalable supervision from the corpus by automatically critiquing mistakes in the reasoning process of MsMR and rendering a final verdict of the problem-solution. Most existing methods rely on crafting high-quality supervised fine-tuning demonstrations for critiquing capability enhancement and pay little attention to delving into the underlying reason for the poor critiquing performance of LLMs. In this paper, we orthogonally quantify and investigate the potential reason -- imbalanced evaluation preference, and conduct a statistical preference analysis. Motivated by the analysis of the reason, a novel perplexity-aware reinforcement learning algorithm is proposed to rectify the evaluation preference, elevating the critiquing capability. Specifically, to probe into LLMs' critiquing characteristics, a One-to-many Problem-Solution (OPS) benchmark is meticulously constructed to quantify the behavior difference of LLMs when evaluating the problem solutions generated by itself and others. Then, to investigate the behavior difference in depth, we conduct a statistical preference analysis oriented on perplexity and find an intriguing phenomenon -- ``LLMs incline to judge solutions with lower perplexity as correct'', which is dubbed as \textit{imbalanced evaluation preference}. To rectify this preference, we regard perplexity as the baton in the algorithm of Group Relative Policy Optimization, supporting the LLMs to explore trajectories that judge lower perplexity as wrong and higher perplexity as correct. Extensive experimental results on our built OPS and existing available critic benchmarks demonstrate the validity of our method.
Thinking Like an Expert:Multimodal Hypergraph-of-Thought (HoT) Reasoning to boost Foundation Modals
Aug 11, 2023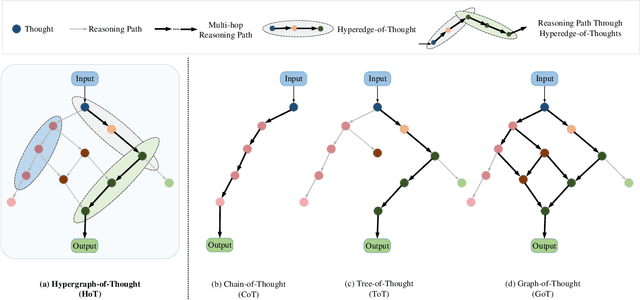

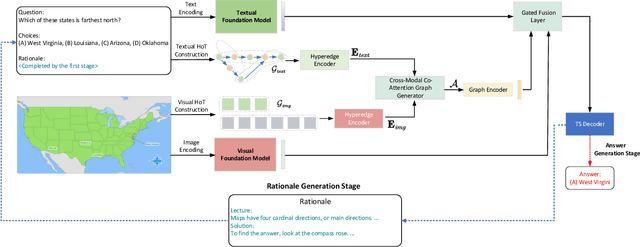

Reasoning ability is one of the most crucial capabilities of a foundation model, signifying its capacity to address complex reasoning tasks. Chain-of-Thought (CoT) technique is widely regarded as one of the effective methods for enhancing the reasoning ability of foundation models and has garnered significant attention. However, the reasoning process of CoT is linear, step-by-step, similar to personal logical reasoning, suitable for solving general and slightly complicated problems. On the contrary, the thinking pattern of an expert owns two prominent characteristics that cannot be handled appropriately in CoT, i.e., high-order multi-hop reasoning and multimodal comparative judgement. Therefore, the core motivation of this paper is transcending CoT to construct a reasoning paradigm that can think like an expert. The hyperedge of a hypergraph could connect various vertices, making it naturally suitable for modelling high-order relationships. Inspired by this, this paper innovatively proposes a multimodal Hypergraph-of-Thought (HoT) reasoning paradigm, which enables the foundation models to possess the expert-level ability of high-order multi-hop reasoning and multimodal comparative judgement. Specifically, a textual hypergraph-of-thought is constructed utilizing triple as the primary thought to model higher-order relationships, and a hyperedge-of-thought is generated through multi-hop walking paths to achieve multi-hop inference. Furthermore, we devise a visual hypergraph-of-thought to interact with the textual hypergraph-of-thought via Cross-modal Co-Attention Graph Learning for multimodal comparative verification. Experimentations on the ScienceQA benchmark demonstrate the proposed HoT-based T5 outperforms CoT-based GPT3.5 and chatGPT, which is on par with CoT-based GPT4 with a lower model size.
Remote Sensing Cross-Modal Text-Image Retrieval Based on Global and Local Information
Apr 21, 2022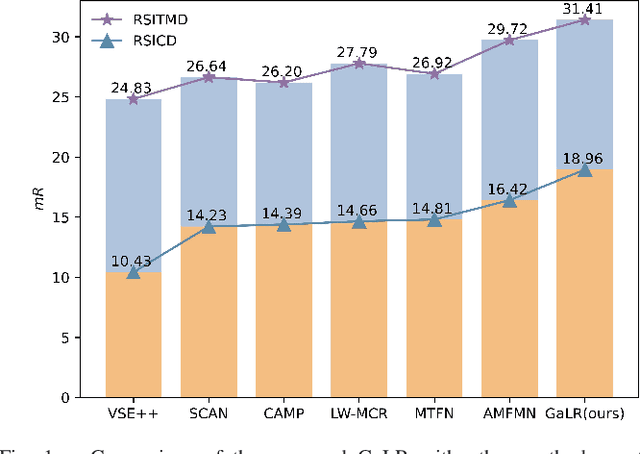
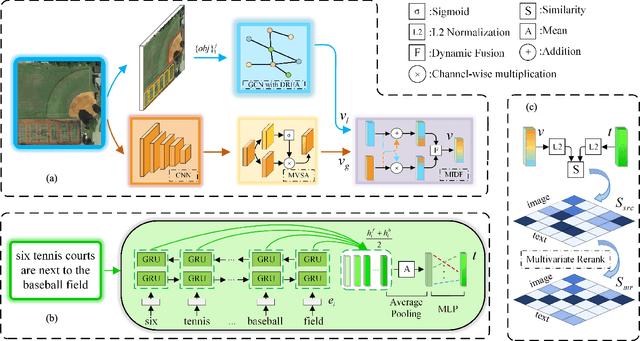
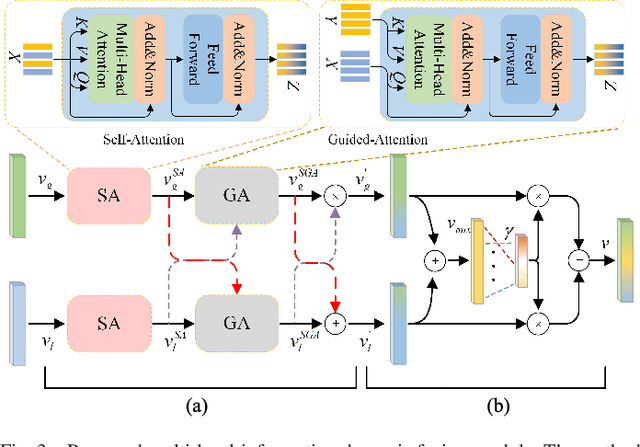
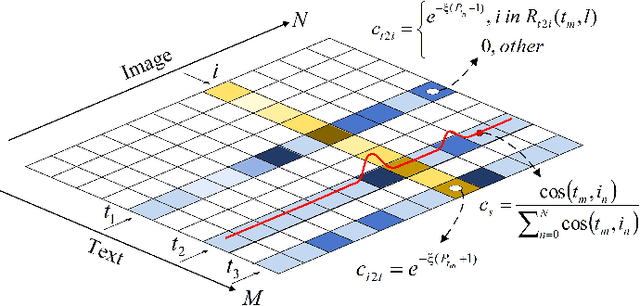
Cross-modal remote sensing text-image retrieval (RSCTIR) has recently become an urgent research hotspot due to its ability of enabling fast and flexible information extraction on remote sensing (RS) images. However, current RSCTIR methods mainly focus on global features of RS images, which leads to the neglect of local features that reflect target relationships and saliency. In this article, we first propose a novel RSCTIR framework based on global and local information (GaLR), and design a multi-level information dynamic fusion (MIDF) module to efficaciously integrate features of different levels. MIDF leverages local information to correct global information, utilizes global information to supplement local information, and uses the dynamic addition of the two to generate prominent visual representation. To alleviate the pressure of the redundant targets on the graph convolution network (GCN) and to improve the model s attention on salient instances during modeling local features, the de-noised representation matrix and the enhanced adjacency matrix (DREA) are devised to assist GCN in producing superior local representations. DREA not only filters out redundant features with high similarity, but also obtains more powerful local features by enhancing the features of prominent objects. Finally, to make full use of the information in the similarity matrix during inference, we come up with a plug-and-play multivariate rerank (MR) algorithm. The algorithm utilizes the k nearest neighbors of the retrieval results to perform a reverse search, and improves the performance by combining multiple components of bidirectional retrieval. Extensive experiments on public datasets strongly demonstrate the state-of-the-art performance of GaLR methods on the RSCTIR task. The code of GaLR method, MR algorithm, and corresponding files have been made available at https://github.com/xiaoyuan1996/GaLR .