 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards High-Fidelity CAD Generation via LLM-Driven Program Generation and Text-Based B-Rep Primitive Grounding
Mar 12, 2026The field of Computer-Aided Design (CAD) generation has made significant progress in recent years. Existing methods typically fall into two separate categorie: parametric CAD modeling and direct boundary representation (B-Rep) synthesis. In modern feature-based CAD systems, parametric modeling and B-Rep are inherently intertwined, as advanced parametric operations (e.g., fillet and chamfer) require explicit selection of B-Rep geometric primitives, and the B-Rep itself is derived from parametric operations. Consequently, this paradigm gap remains a critical factor limiting AI-driven CAD modeling for complex industrial product design. This paper present FutureCAD, a novel text-to-CAD framework that leverages large language models (LLMs) and a B-Rep grounding transformer (BRepGround) for high-fidelity CAD generation. Our method generates executable CadQuery scripts, and introduces a text-based query mechanism that enables the LLM to specify geometric selections via natural language, which BRepGround then grounds to the target primitives. To train our framework, we construct a new dataset comprising real-world CAD models. For the LLM, we apply supervised fine-tuning (SFT) to establish fundamental CAD generation capabilities, followed by reinforcement learning (RL) to improve generalization. Experiments show that FutureCAD achieves state-of-the-art CAD generation performance.
CHARM: Considering Human Attributes for Reinforcement Modeling
Jun 16, 2025
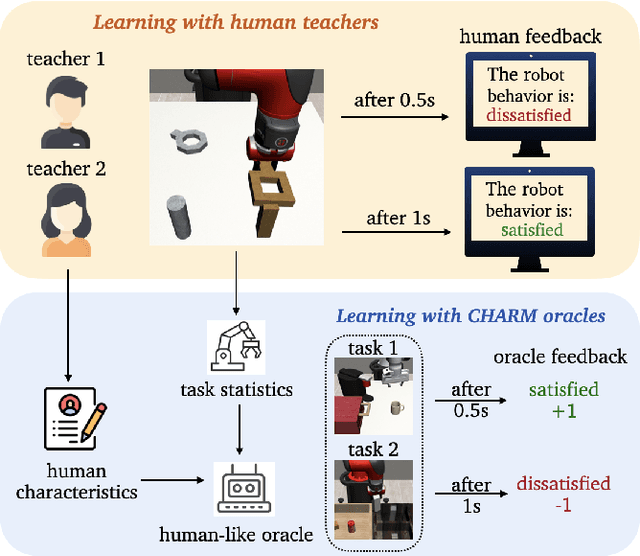


Reinforcement Learning from Human Feedback has recently achieved significant success in various fields, and its performance is highly related to feedback quality. While much prior work acknowledged that human teachers' characteristics would affect human feedback patterns, there is little work that has closely investigated the actual effects. In this work, we designed an exploratory study investigating how human feedback patterns are associated with human characteristics. We conducted a public space study with two long horizon tasks and 46 participants. We found that feedback patterns are not only correlated with task statistics, such as rewards, but also correlated with participants' characteristics, especially robot experience and educational background. Additionally, we demonstrated that human feedback value can be more accurately predicted with human characteristics compared to only using task statistics. All human feedback and characteristics we collected, and codes for our data collection and predicting more accurate human feedback are available at https://github.com/AABL-Lab/CHARM
Graph-based Unsupervised Disentangled Representation Learning via Multimodal Large Language Models
Jul 26, 2024
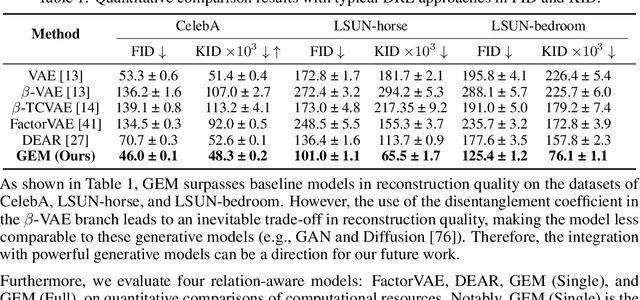
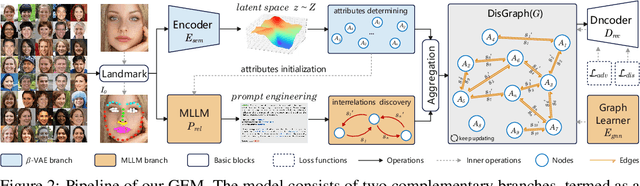
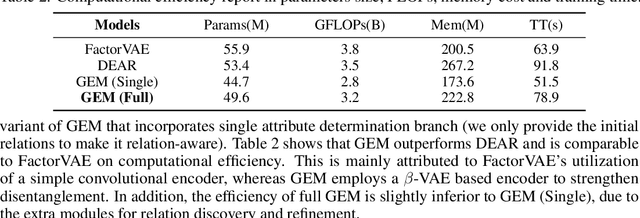
Disentangled representation learning (DRL) aims to identify and decompose underlying factors behind observations, thus facilitating data perception and generation. However, current DRL approaches often rely on the unrealistic assumption that semantic factors are statistically independent. In reality, these factors may exhibit correlations, which off-the-shelf solutions have yet to properly address. To tackle this challenge, we introduce a bidirectional weighted graph-based framework, to learn factorized attributes and their interrelations within complex data. Specifically, we propose a $\beta$-VAE based module to extract factors as the initial nodes of the graph, and leverage the multimodal large language model (MLLM) to discover and rank latent correlations, thereby updating the weighted edges. By integrating these complementary modules, our model successfully achieves fine-grained, practical and unsupervised disentanglement. Experiments demonstrate our method's superior performance in disentanglement and reconstruction. Furthermore, the model inherits enhanced interpretability and generalizability from MLLMs.
Rate-Distortion-Cognition Controllable Versatile Neural Image Compression
Jul 16, 2024Recently, the field of Image Coding for Machines (ICM) has garnered heightened interest and significant advances thanks to the rapid progress of learning-based techniques for image compression and analysis. Previous studies often require training separate codecs to support various bitrate levels, machine tasks, and networks, thus lacking both flexibility and practicality. To address these challenges, we propose a rate-distortion-cognition controllable versatile image compression, which method allows the users to adjust the bitrate (i.e., Rate), image reconstruction quality (i.e., Distortion), and machine task accuracy (i.e., Cognition) with a single neural model, achieving ultra-controllability. Specifically, we first introduce a cognition-oriented loss in the primary compression branch to train a codec for diverse machine tasks. This branch attains variable bitrate by regulating quantization degree through the latent code channels. To further enhance the quality of the reconstructed images, we employ an auxiliary branch to supplement residual information with a scalable bitstream. Ultimately, two branches use a `$\beta x + (1 - \beta) y$' interpolation strategy to achieve a balanced cognition-distortion trade-off. Extensive experiments demonstrate that our method yields satisfactory ICM performance and flexible Rate-Distortion-Cognition controlling.
FairRAG: Fair Human Generation via Fair Retrieval Augmentation
Apr 05, 2024



Existing text-to-image generative models reflect or even amplify societal biases ingrained in their training data. This is especially concerning for human image generation where models are biased against certain demographic groups. Existing attempts to rectify this issue are hindered by the inherent limitations of the pre-trained models and fail to substantially improve demographic diversity. In this work, we introduce Fair Retrieval Augmented Generation (FairRAG), a novel framework that conditions pre-trained generative models on reference images retrieved from an external image database to improve fairness in human generation. FairRAG enables conditioning through a lightweight linear module that projects reference images into the textual space. To enhance fairness, FairRAG applies simple-yet-effective debiasing strategies, providing images from diverse demographic groups during the generative process. Extensive experiments demonstrate that FairRAG outperforms existing methods in terms of demographic diversity, image-text alignment, and image fidelity while incurring minimal computational overhead during inference.
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
Semi-Supervised Learning for Anomaly Traffic Detection via Bidirectional Normalizing Flows
Mar 13, 2024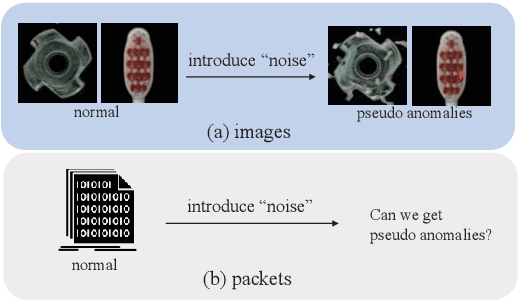
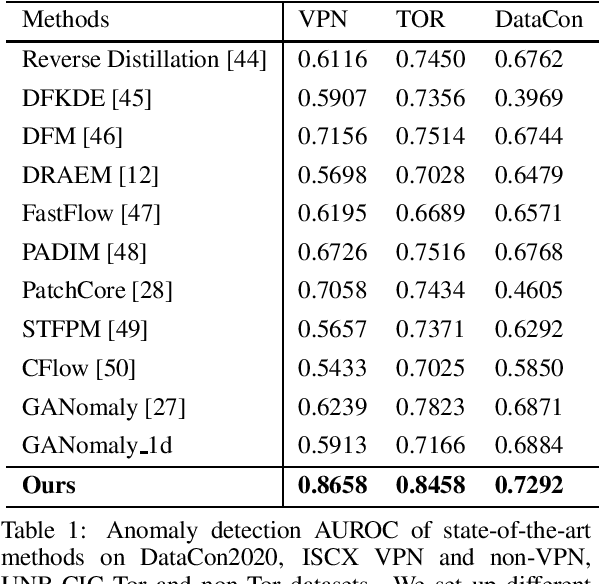
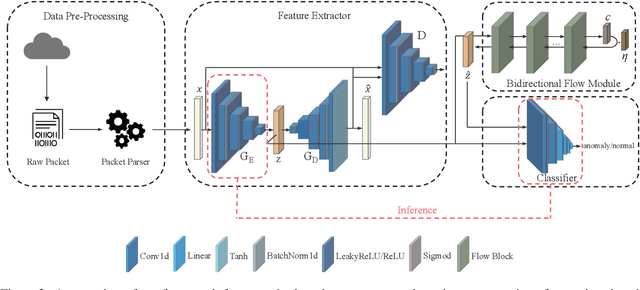
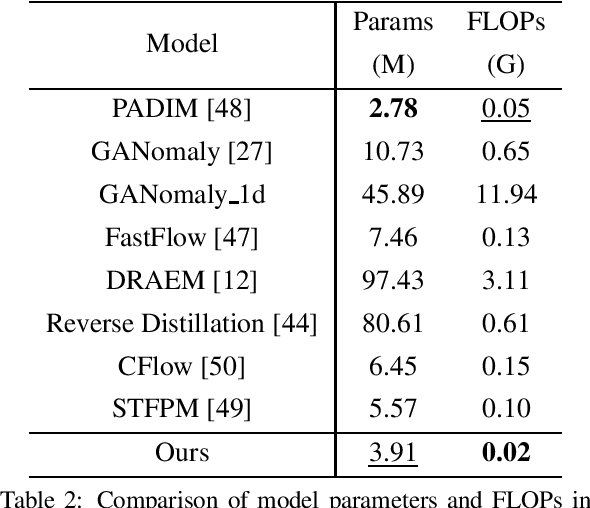
With the rapid development of the Internet, various types of anomaly traffic are threatening network security. We consider the problem of anomaly network traffic detection and propose a three-stage anomaly detection framework using only normal traffic. Our framework can generate pseudo anomaly samples without prior knowledge of anomalies to achieve the detection of anomaly data. Firstly, we employ a reconstruction method to learn the deep representation of normal samples. Secondly, these representations are normalized to a standard normal distribution using a bidirectional flow module. To simulate anomaly samples, we add noises to the normalized representations which are then passed through the generation direction of the bidirectional flow module. Finally, a simple classifier is trained to differentiate the normal samples and pseudo anomaly samples in the latent space. During inference, our framework requires only two modules to detect anomalous samples, leading to a considerable reduction in model size. According to the experiments, our method achieves the state of-the-art results on the common benchmarking datasets of anomaly network traffic detection. The code is given in the https://github.com/ZxuanDang/ATD-via-Flows.git
Cluster-level Feature Alignment for Person Re-identification
Aug 15, 2020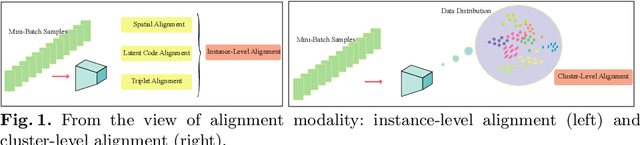

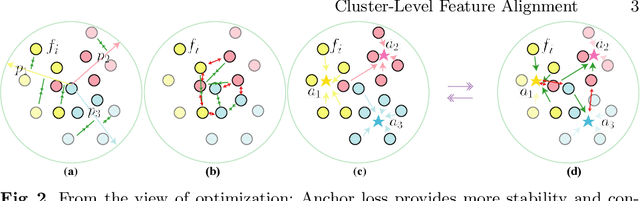

Instance-level alignment is widely exploited for person re-identification, e.g. spatial alignment, latent semantic alignment and triplet alignment. This paper probes another feature alignment modality, namely cluster-level feature alignment across whole dataset, where the model can see not only the sampled images in local mini-batch but the global feature distribution of the whole dataset from distilled anchors. Towards this aim, we propose anchor loss and investigate many variants of cluster-level feature alignment, which consists of iterative aggregation and alignment from the overview of dataset. Our extensive experiments have demonstrated that our methods can provide consistent and significant performance improvement with small training efforts after the saturation of traditional training. In both theoretical and experimental aspects, our proposed methods can result in more stable and guided optimization towards better representation and generalization for well-aligned embedding.
Adaptive Fractional Dilated Convolution Network for Image Aesthetics Assessment
Apr 06, 2020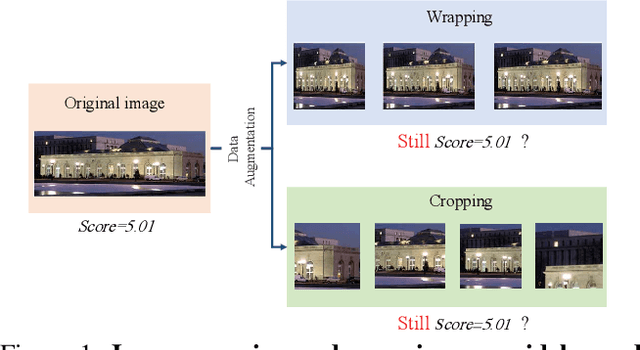
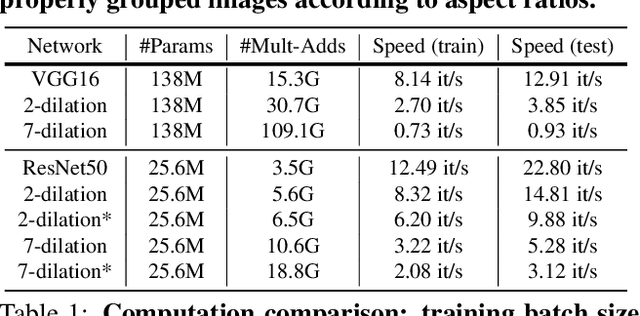
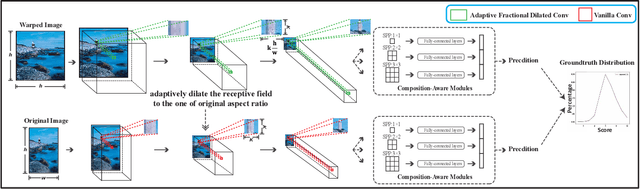
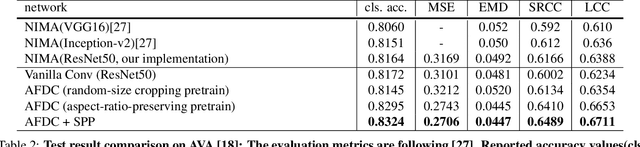
To leverage deep learning for image aesthetics assessment, one critical but unsolved issue is how to seamlessly incorporate the information of image aspect ratios to learn more robust models. In this paper, an adaptive fractional dilated convolution (AFDC), which is aspect-ratio-embedded, composition-preserving and parameter-free, is developed to tackle this issue natively in convolutional kernel level. Specifically, the fractional dilated kernel is adaptively constructed according to the image aspect ratios, where the interpolation of nearest two integers dilated kernels is used to cope with the misalignment of fractional sampling. Moreover, we provide a concise formulation for mini-batch training and utilize a grouping strategy to reduce computational overhead. As a result, it can be easily implemented by common deep learning libraries and plugged into popular CNN architectures in a computation-efficient manner. Our experimental results demonstrate that our proposed method achieves state-of-the-art performance on image aesthetics assessment over the AVA dataset.
Virtual Blood Vessels in Complex Background using Stereo X-ray Images
Sep 22, 2017

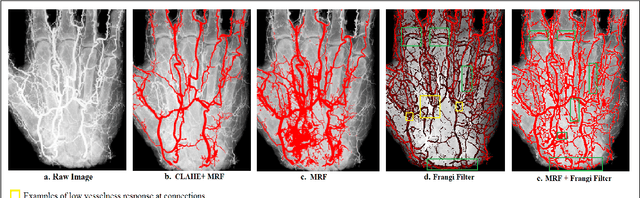

We propose a fully automatic system to reconstruct and visualize 3D blood vessels in Augmented Reality (AR) system from stereo X-ray images with bones and body fat. Currently, typical 3D imaging technologies are expensive and carrying the risk of irradiation exposure. To reduce the potential harm, we only need to take two X-ray images before visualizing the vessels. Our system can effectively reconstruct and visualize vessels in following steps. We first conduct initial segmentation using Markov Random Field and then refine segmentation in an entropy based post-process. We parse the segmented vessels by extracting their centerlines and generating trees. We propose a coarse-to-fine scheme for stereo matching, including initial matching using affine transform and dense matching using Hungarian algorithm guided by Gaussian regression. Finally, we render and visualize the reconstructed model in a HoloLens based AR system, which can essentially change the way of visualizing medical data. We have evaluated its performance by using synthetic and real stereo X-ray images, and achieved satisfactory quantitative and qualitative results.