 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCluster-level Feature Alignment for Person Re-identification
Paper and Code
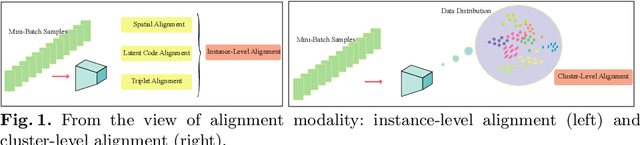

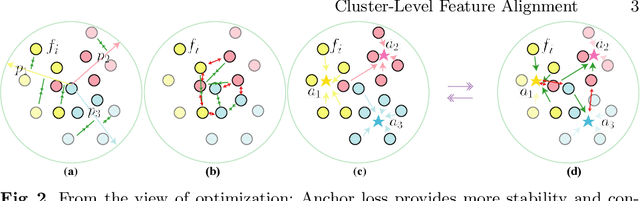

Instance-level alignment is widely exploited for person re-identification, e.g. spatial alignment, latent semantic alignment and triplet alignment. This paper probes another feature alignment modality, namely cluster-level feature alignment across whole dataset, where the model can see not only the sampled images in local mini-batch but the global feature distribution of the whole dataset from distilled anchors. Towards this aim, we propose anchor loss and investigate many variants of cluster-level feature alignment, which consists of iterative aggregation and alignment from the overview of dataset. Our extensive experiments have demonstrated that our methods can provide consistent and significant performance improvement with small training efforts after the saturation of traditional training. In both theoretical and experimental aspects, our proposed methods can result in more stable and guided optimization towards better representation and generalization for well-aligned embedding.