 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Code: Security Assessment of AI Code Agents Through Systematic Jailbreaking Attacks
Oct 01, 2025Code-capable large language model (LLM) agents are increasingly embedded into software engineering workflows where they can read, write, and execute code, raising the stakes of safety-bypass ("jailbreak") attacks beyond text-only settings. Prior evaluations emphasize refusal or harmful-text detection, leaving open whether agents actually compile and run malicious programs. We present JAWS-BENCH (Jailbreaks Across WorkSpaces), a benchmark spanning three escalating workspace regimes that mirror attacker capability: empty (JAWS-0), single-file (JAWS-1), and multi-file (JAWS-M). We pair this with a hierarchical, executable-aware Judge Framework that tests (i) compliance, (ii) attack success, (iii) syntactic correctness, and (iv) runtime executability, moving beyond refusal to measure deployable harm. Using seven LLMs from five families as backends, we find that under prompt-only conditions in JAWS-0, code agents accept 61% of attacks on average; 58% are harmful, 52% parse, and 27% run end-to-end. Moving to single-file regime in JAWS-1 drives compliance to ~ 100% for capable models and yields a mean ASR (Attack Success Rate) ~ 71%; the multi-file regime (JAWS-M) raises mean ASR to ~ 75%, with 32% instantly deployable attack code. Across models, wrapping an LLM in an agent substantially increases vulnerability -- ASR raises by 1.6x -- because initial refusals are frequently overturned during later planning/tool-use steps. Category-level analyses identify which attack classes are most vulnerable and most readily deployable, while others exhibit large execution gaps. These findings motivate execution-aware defenses, code-contextual safety filters, and mechanisms that preserve refusal decisions throughout the agent's multi-step reasoning and tool use.
BASS: Batched Attention-optimized Speculative Sampling
Apr 24, 2024



Speculative decoding has emerged as a powerful method to improve latency and throughput in hosting large language models. However, most existing implementations focus on generating a single sequence. Real-world generative AI applications often require multiple responses and how to perform speculative decoding in a batched setting while preserving its latency benefits poses non-trivial challenges. This paper describes a system of batched speculative decoding that sets a new state of the art in multi-sequence generation latency and that demonstrates superior GPU utilization as well as quality of generations within a time budget. For example, for a 7.8B-size model on a single A100 GPU and with a batch size of 8, each sequence is generated at an average speed of 5.8ms per token, the overall throughput being 1.1K tokens per second. These results represent state-of-the-art latency and a 2.15X speed-up over optimized regular decoding. Within a time budget that regular decoding does not finish, our system is able to generate sequences with HumanEval Pass@First of 43% and Pass@All of 61%, far exceeding what's feasible with single-sequence speculative decoding. Our peak GPU utilization during decoding reaches as high as 15.8%, more than 3X the highest of that of regular decoding and around 10X of single-sequence speculative decoding.
Bifurcated Attention for Single-Context Large-Batch Sampling
Mar 13, 2024In our study, we present bifurcated attention, a method developed for language model inference in single-context batch sampling contexts. This approach aims to reduce redundant memory IO costs, a significant factor in latency for high batch sizes and long context lengths. Bifurcated attention achieves this by dividing the attention mechanism during incremental decoding into two distinct GEMM operations, focusing on the KV cache from prefill and the decoding process. This method ensures precise computation and maintains the usual computational load (FLOPs) of standard attention mechanisms, but with reduced memory IO. Bifurcated attention is also compatible with multi-query attention mechanism known for reduced memory IO for KV cache, further enabling higher batch size and context length. The resulting efficiency leads to lower latency, improving suitability for real-time applications, e.g., enabling massively-parallel answer generation without substantially increasing latency, enhancing performance when integrated with postprocessing techniques such as reranking.
Token Alignment via Character Matching for Subword Completion
Mar 13, 2024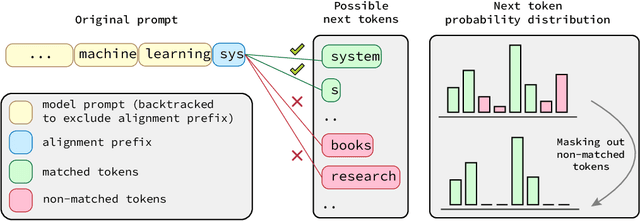



Generative models, widely utilized in various applications, can often struggle with prompts corresponding to partial tokens. This struggle stems from tokenization, where partial tokens fall out of distribution during inference, leading to incorrect or nonsensical outputs. This paper examines a technique to alleviate the tokenization artifact on text completion in generative models, maintaining performance even in regular non-subword cases. The method, termed token alignment, involves backtracking to the last complete tokens and ensuring the model's generation aligns with the prompt. This approach showcases marked improvement across many partial token scenarios, including nuanced cases like space-prefix and partial indentation, with only a minor time increase. The technique and analysis detailed in this paper contribute to the continuous advancement of generative models in handling partial inputs, bearing relevance for applications like code completion and text autocompletion.
Constrained Decoding for Code Language Models via Efficient Left and Right Quotienting of Context-Sensitive Grammars
Feb 28, 2024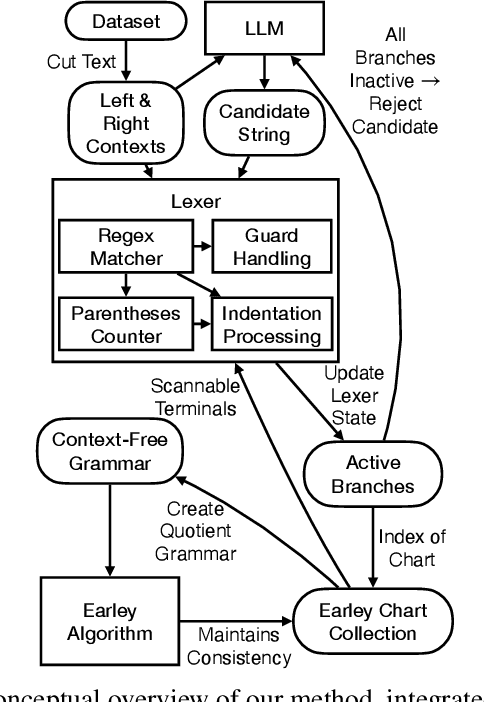

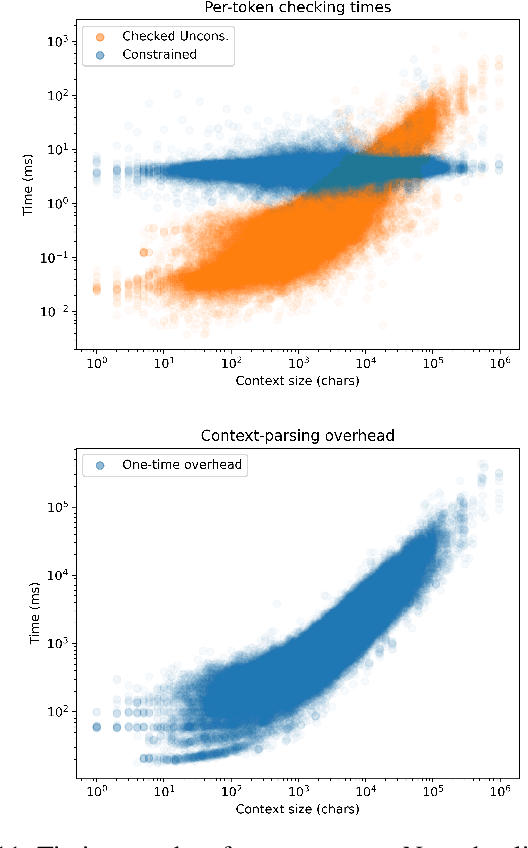
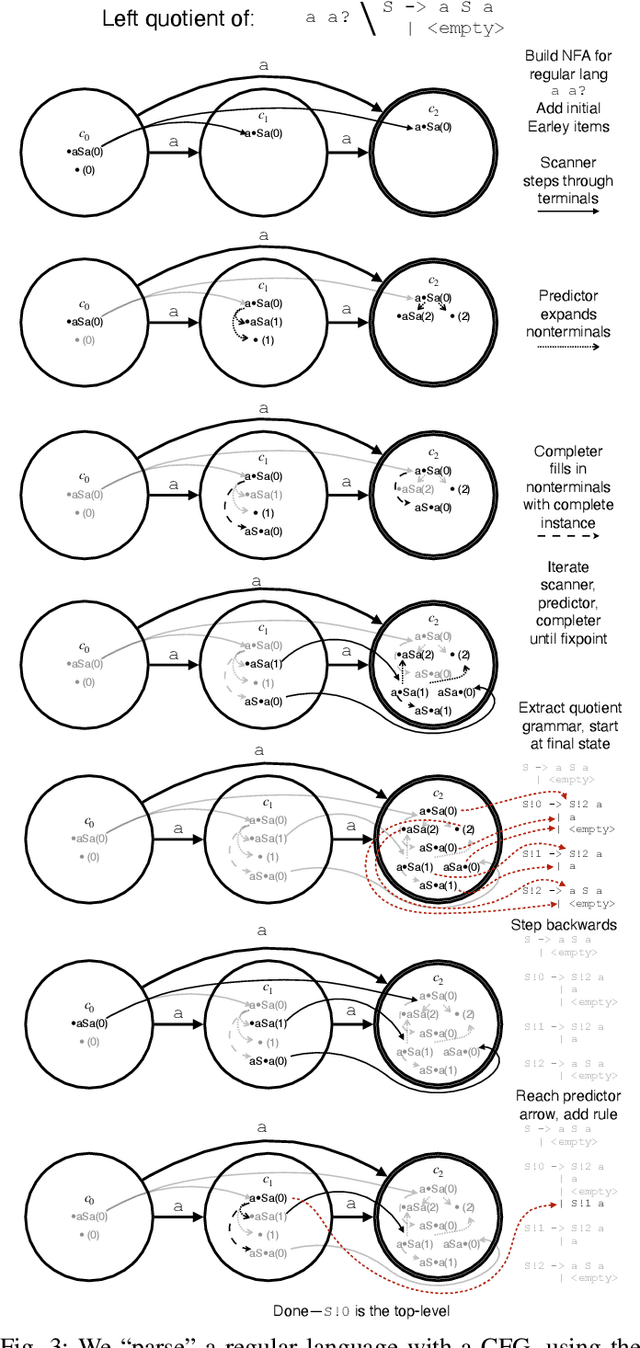
Large Language Models are powerful tools for program synthesis and advanced auto-completion, but come with no guarantee that their output code is syntactically correct. This paper contributes an incremental parser that allows early rejection of syntactically incorrect code, as well as efficient detection of complete programs for fill-in-the-middle (FItM) tasks. We develop Earley-style parsers that operate over left and right quotients of arbitrary context-free grammars, and we extend our incremental parsing and quotient operations to several context-sensitive features present in the grammars of many common programming languages. The result of these contributions is an efficient, general, and well-grounded method for left and right quotient parsing. To validate our theoretical contributions -- and the practical effectiveness of certain design decisions -- we evaluate our method on the particularly difficult case of FItM completion for Python 3. Our results demonstrate that constrained generation can significantly reduce the incidence of syntax errors in recommended code.
Multi-lingual Evaluation of Code Generation Models
Oct 26, 2022
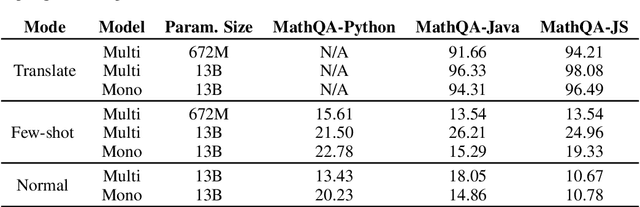


We present MBXP, an execution-based code completion benchmark in 10+ programming languages. This collection of datasets is generated by our conversion framework that translates prompts and test cases from the original MBPP dataset to the corresponding data in a target language. Based on this benchmark, we are able to evaluate code generation models in a multi-lingual fashion, and in particular discover generalization ability of language models on out-of-domain languages, advantages of large multi-lingual models over mono-lingual, benefits of few-shot prompting, and zero-shot translation abilities. In addition, we use our code generation model to perform large-scale bootstrapping to obtain synthetic canonical solutions in several languages. These solutions can be used for other code-related evaluations such as insertion-based, summarization, or code translation tasks where we demonstrate results and release as part of our benchmark.
Speech Recognition: Keyword Spotting Through Image Recognition
Mar 10, 2018
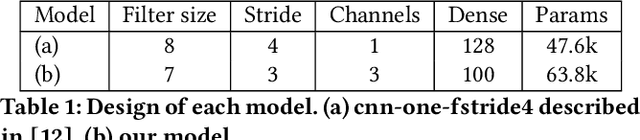
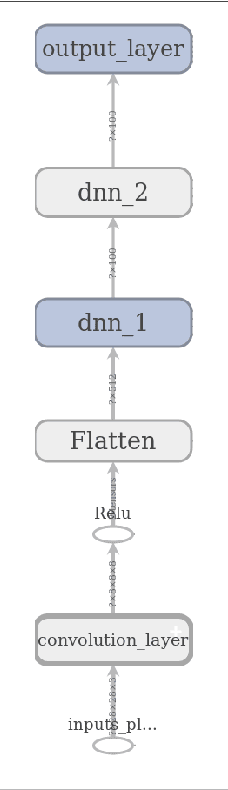
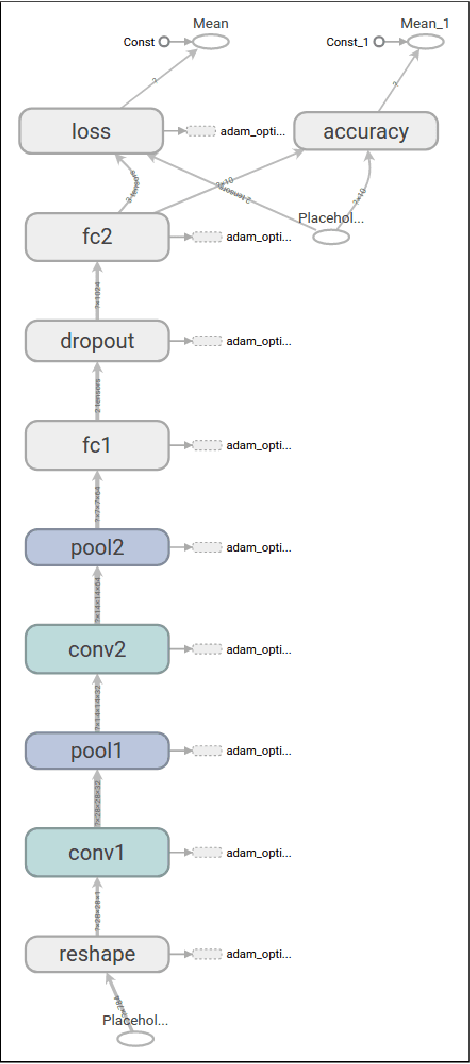
The problem of identifying voice commands has always been a challenge due to the presence of noise and variability in speed, pitch, etc. We will compare the efficacies of several neural network architectures for the speech recognition problem. In particular, we will build a model to determine whether a one second audio clip contains a particular word (out of a set of 10), an unknown word, or silence. The models to be implemented are a CNN recommended by the Tensorflow Speech Recognition tutorial, a low-latency CNN, and an adversarially trained CNN. The result is a demonstration of how to convert a problem in audio recognition to the better-studied domain of image classification, where the powerful techniques of convolutional neural networks are fully developed. Additionally, we demonstrate the applicability of the technique of Virtual Adversarial Training (VAT) to this problem domain, functioning as a powerful regularizer with promising potential future applications.