 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextual Gradients are a Flawed Metaphor for Automatic Prompt Optimization
Dec 15, 2025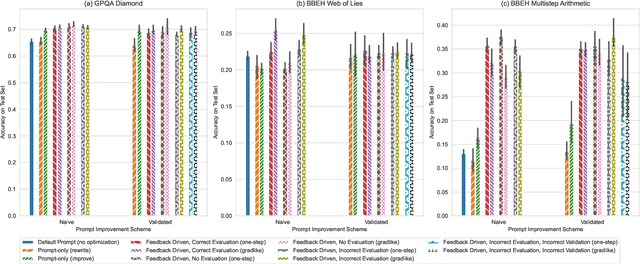
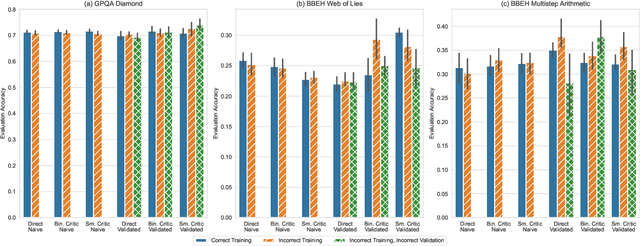
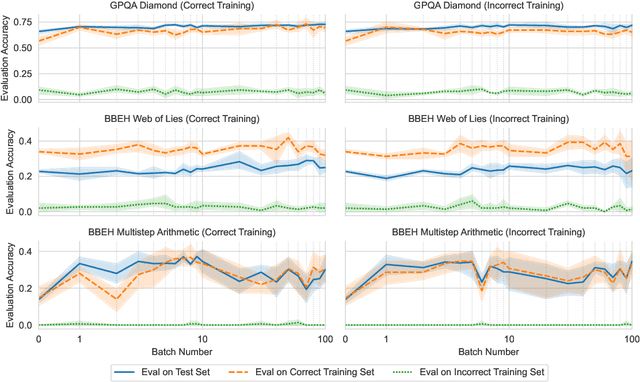
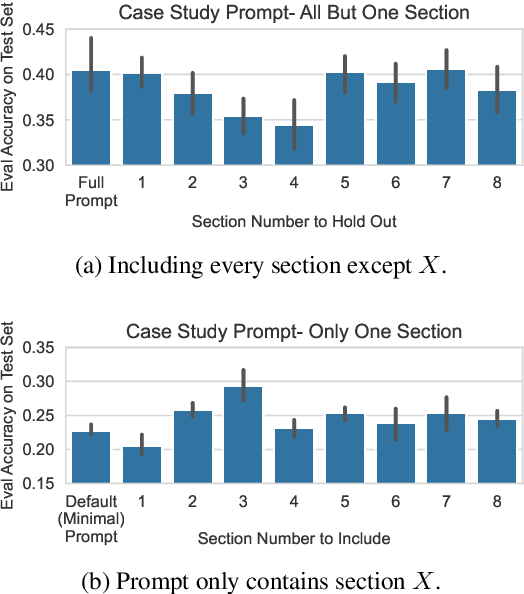
A well-engineered prompt can increase the performance of large language models; automatic prompt optimization techniques aim to increase performance without requiring human effort to tune the prompts. One leading class of prompt optimization techniques introduces the analogy of textual gradients. We investigate the behavior of these textual gradient methods through a series of experiments and case studies. While such methods often result in a performance improvement, our experiments suggest that the gradient analogy does not accurately explain their behavior. Our insights may inform the selection of prompt optimization strategies, and development of new approaches.
Approximately Aligned Decoding
Oct 01, 2024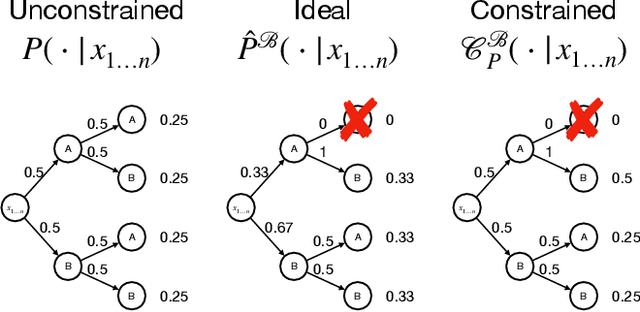
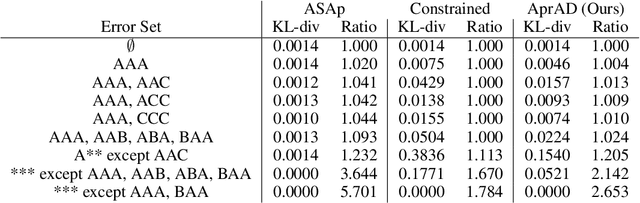

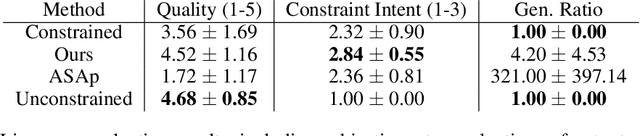
It is common to reject undesired outputs of Large Language Models (LLMs); however, current methods to do so require an excessive amount of computation, or severely distort the distribution of outputs. We present a method to balance the distortion of the output distribution with computational efficiency, allowing for the generation of long sequences of text with difficult-to-satisfy constraints, with less amplification of low probability outputs compared to existing methods. We show through a series of experiments that the task-specific performance of our method is comparable to methods that do not distort the output distribution, while being much more computationally efficient.
Constrained Decoding for Code Language Models via Efficient Left and Right Quotienting of Context-Sensitive Grammars
Feb 28, 2024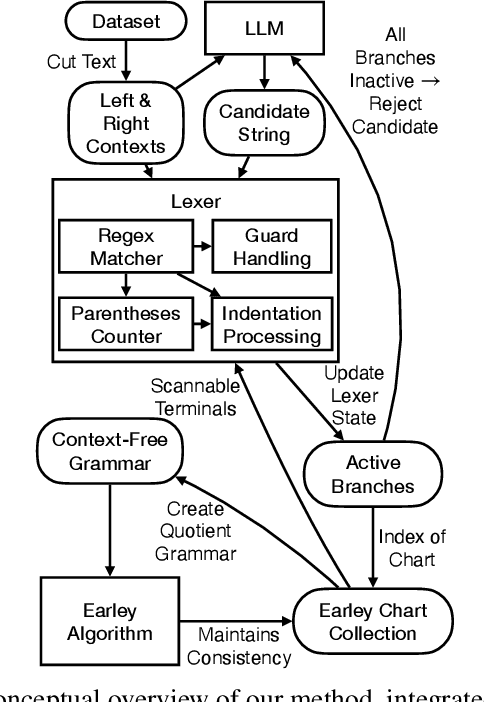

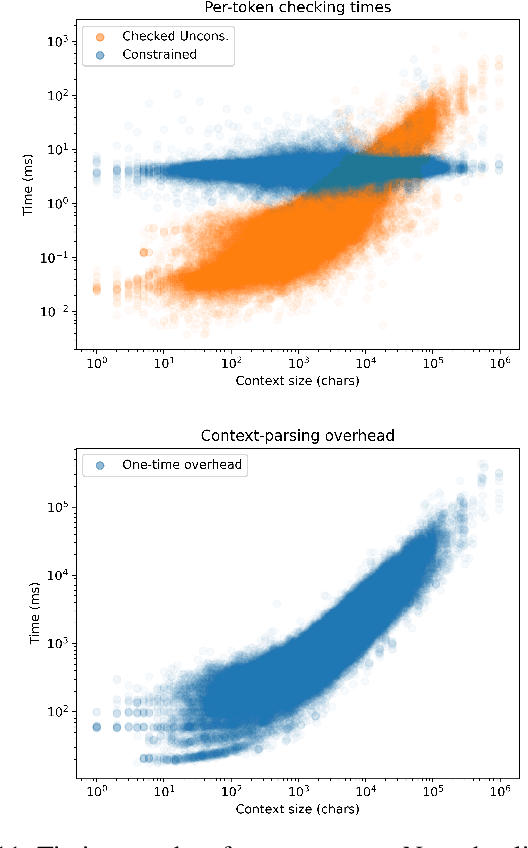
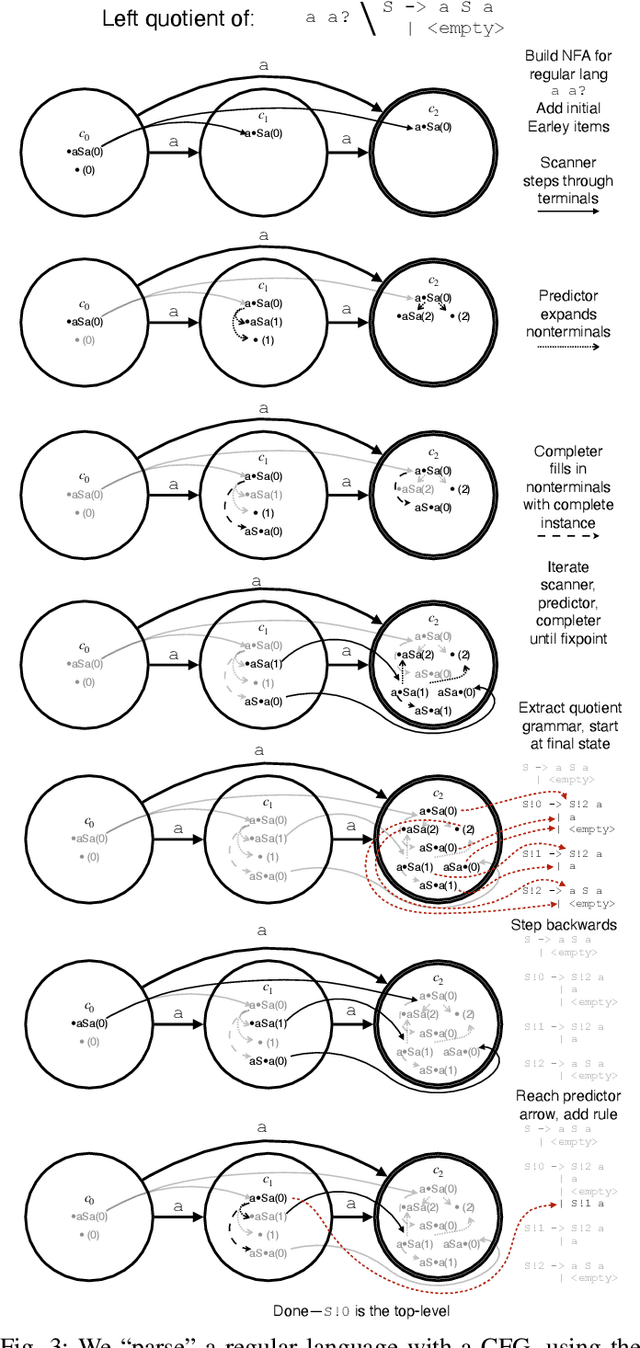
Large Language Models are powerful tools for program synthesis and advanced auto-completion, but come with no guarantee that their output code is syntactically correct. This paper contributes an incremental parser that allows early rejection of syntactically incorrect code, as well as efficient detection of complete programs for fill-in-the-middle (FItM) tasks. We develop Earley-style parsers that operate over left and right quotients of arbitrary context-free grammars, and we extend our incremental parsing and quotient operations to several context-sensitive features present in the grammars of many common programming languages. The result of these contributions is an efficient, general, and well-grounded method for left and right quotient parsing. To validate our theoretical contributions -- and the practical effectiveness of certain design decisions -- we evaluate our method on the particularly difficult case of FItM completion for Python 3. Our results demonstrate that constrained generation can significantly reduce the incidence of syntax errors in recommended code.