 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextual Gradients are a Flawed Metaphor for Automatic Prompt Optimization
Dec 15, 2025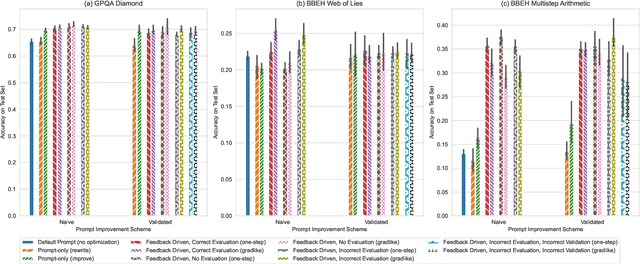
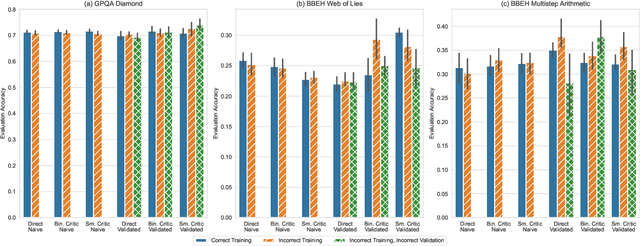
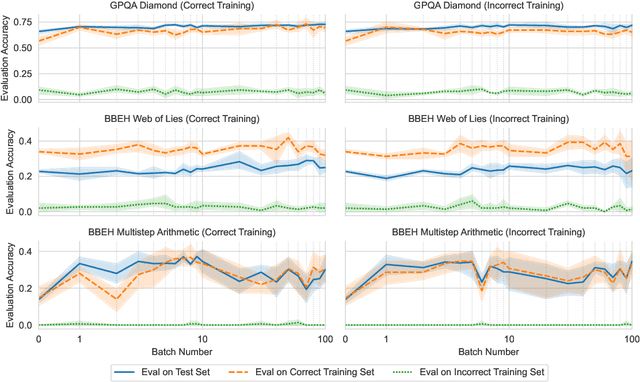
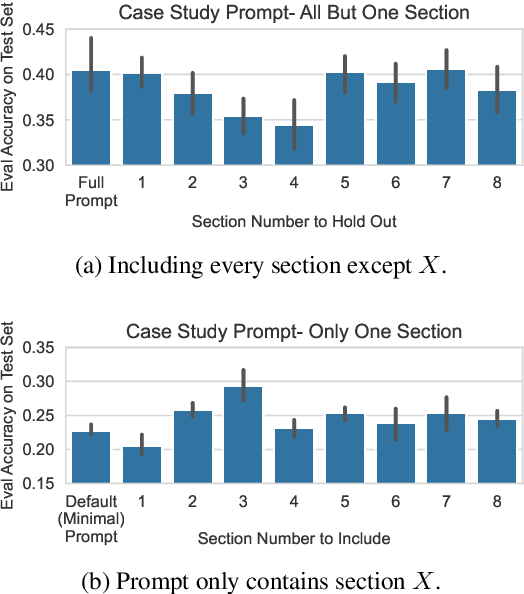
A well-engineered prompt can increase the performance of large language models; automatic prompt optimization techniques aim to increase performance without requiring human effort to tune the prompts. One leading class of prompt optimization techniques introduces the analogy of textual gradients. We investigate the behavior of these textual gradient methods through a series of experiments and case studies. While such methods often result in a performance improvement, our experiments suggest that the gradient analogy does not accurately explain their behavior. Our insights may inform the selection of prompt optimization strategies, and development of new approaches.
Approximately Aligned Decoding
Oct 01, 2024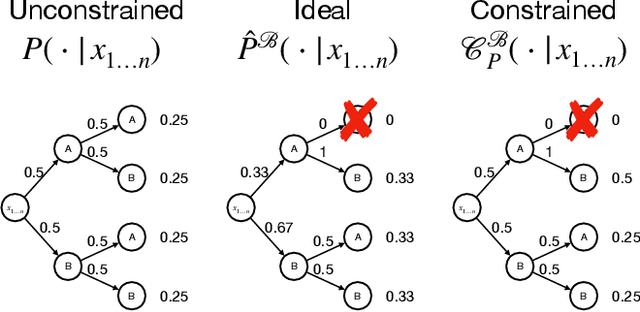
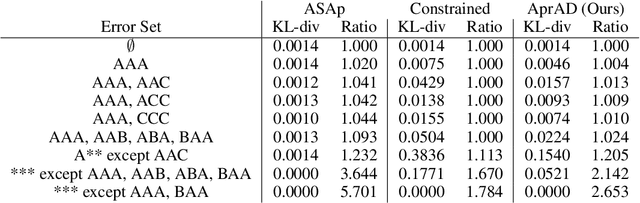

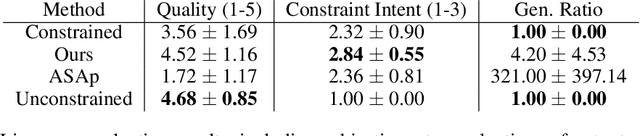
It is common to reject undesired outputs of Large Language Models (LLMs); however, current methods to do so require an excessive amount of computation, or severely distort the distribution of outputs. We present a method to balance the distortion of the output distribution with computational efficiency, allowing for the generation of long sequences of text with difficult-to-satisfy constraints, with less amplification of low probability outputs compared to existing methods. We show through a series of experiments that the task-specific performance of our method is comparable to methods that do not distort the output distribution, while being much more computationally efficient.
Example-based Synthesis of Static Analysis Rules
Apr 19, 2022
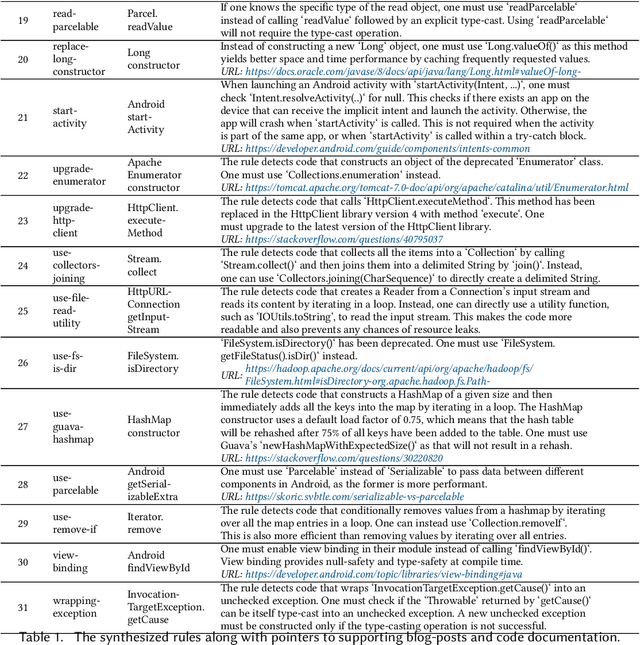
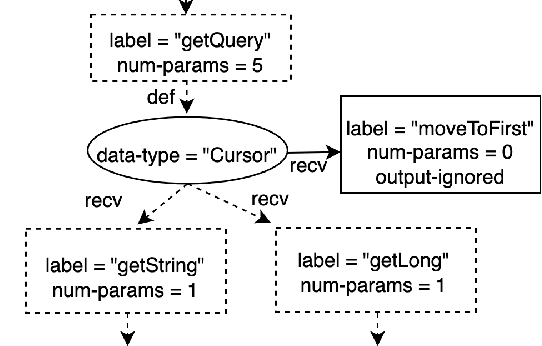
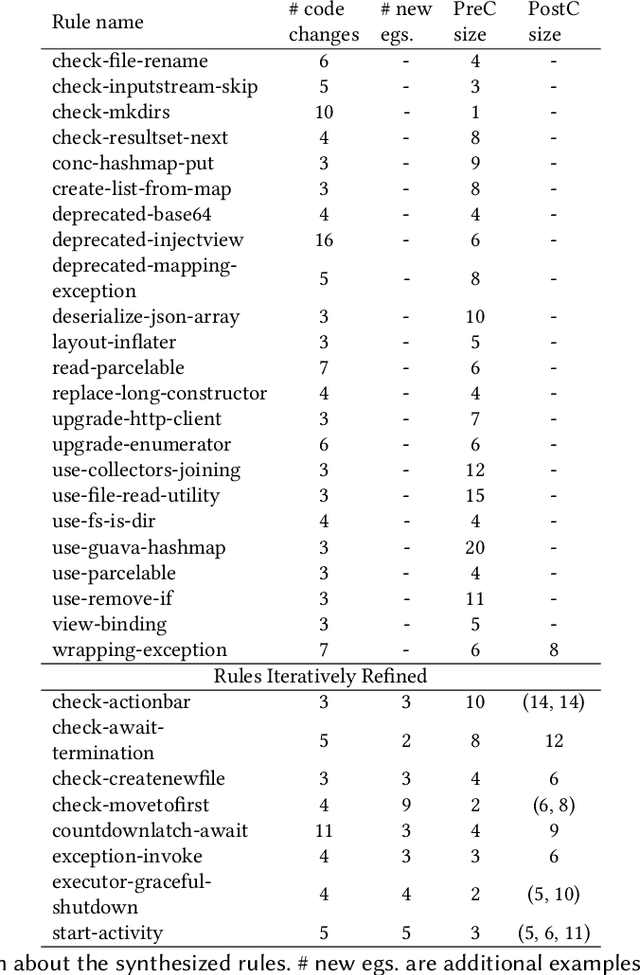
Static Analysis tools have rules for several code quality issues and these rules are created by experts manually. In this paper, we address the problem of automatic synthesis of code quality rules from examples. We formulate the rule synthesis problem as synthesizing first order logic formulas over graph representations of code. We present a new synthesis algorithm RhoSynth that is based on Integer Linear Programming-based graph alignment for identifying code elements of interest to the rule. We bootstrap RhoSynth by leveraging code changes made by developers as the source of positive and negative examples. We also address rule refinement in which the rules are incrementally improved with additional user-provided examples. We validate RhoSynth by synthesizing more than 30 Java code quality rules. These rules have been deployed as part of a code review system in a company and their precision exceeds 75% based on developer feedback collected during live code-reviews. Through comparisons with recent baselines, we show that current state-of-the-art program synthesis approaches are unable to synthesize most of these rules.
Invariant Synthesis for Incomplete Verification Engines
Jan 12, 2018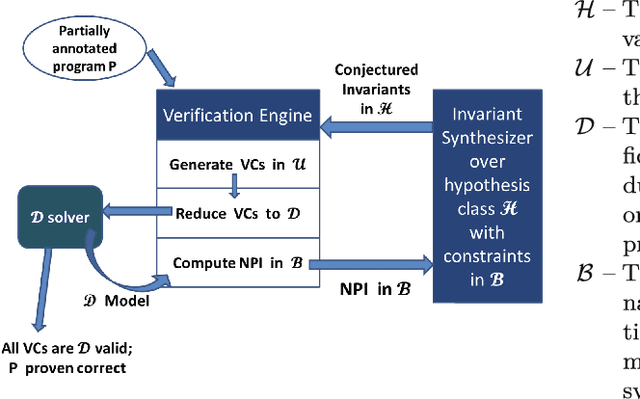
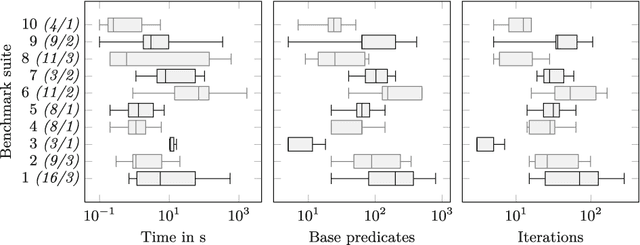
We propose a framework for synthesizing inductive invariants for incomplete verification engines, which soundly reduce logical problems in undecidable theories to decidable theories. Our framework is based on the counter-example guided inductive synthesis principle (CEGIS) and allows verification engines to communicate non-provability information to guide invariant synthesis. We show precisely how the verification engine can compute such non-provability information and how to build effective learning algorithms when invariants are expressed as Boolean combinations of a fixed set of predicates. Moreover, we evaluate our framework in two verification settings, one in which verification engines need to handle quantified formulas and one in which verification engines have to reason about heap properties expressed in an expressive but undecidable separation logic. Our experiments show that our invariant synthesis framework based on non-provability information can both effectively synthesize inductive invariants and adequately strengthen contracts across a large suite of programs.
Horn-ICE Learning for Synthesizing Invariants and Contracts
Dec 26, 2017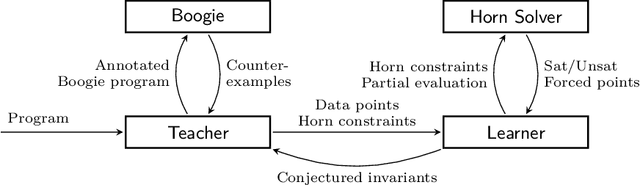
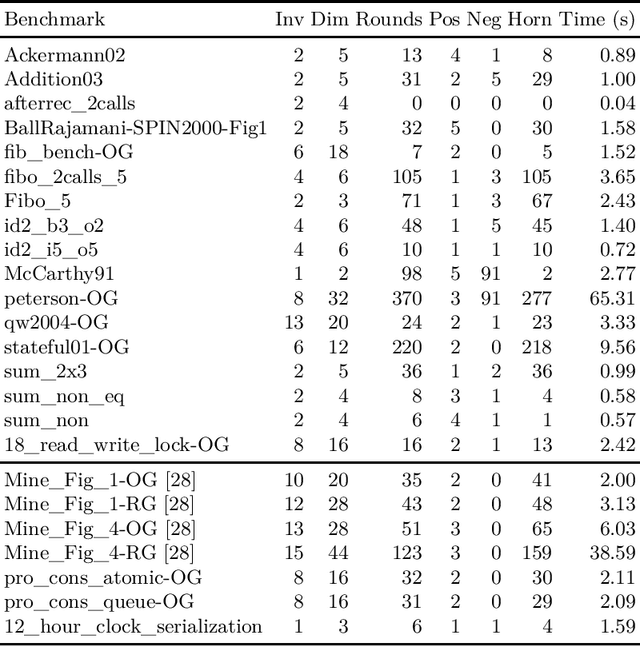
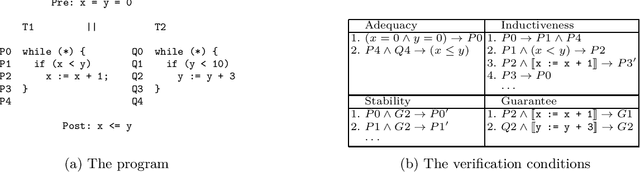
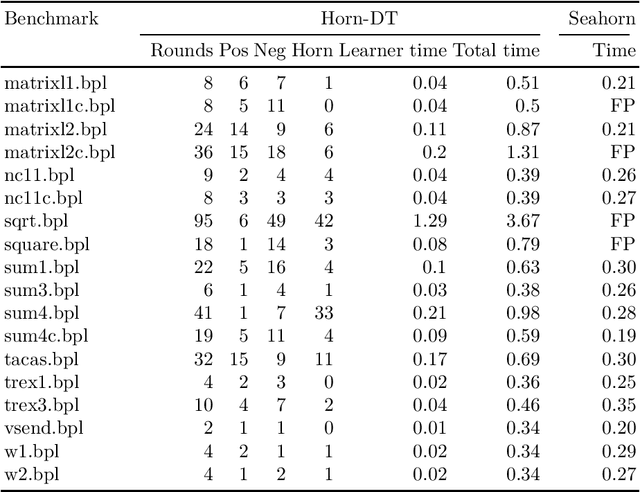
We design learning algorithms for synthesizing invariants using Horn implication counterexamples (Horn-ICE), extending the ICE-learning model. In particular, we describe a decision-tree learning algorithm that learns from Horn-ICE samples, works in polynomial time, and uses statistical heuristics to learn small trees that satisfy the samples. Since most verification proofs can be modeled using Horn clauses, Horn-ICE learning is a more robust technique to learn inductive annotations that prove programs correct. Our experiments show that an implementation of our algorithm is able to learn adequate inductive invariants and contracts efficiently for a variety of sequential and concurrent programs.
Learning Universally Quantified Invariants of Linear Data Structures
Feb 09, 2013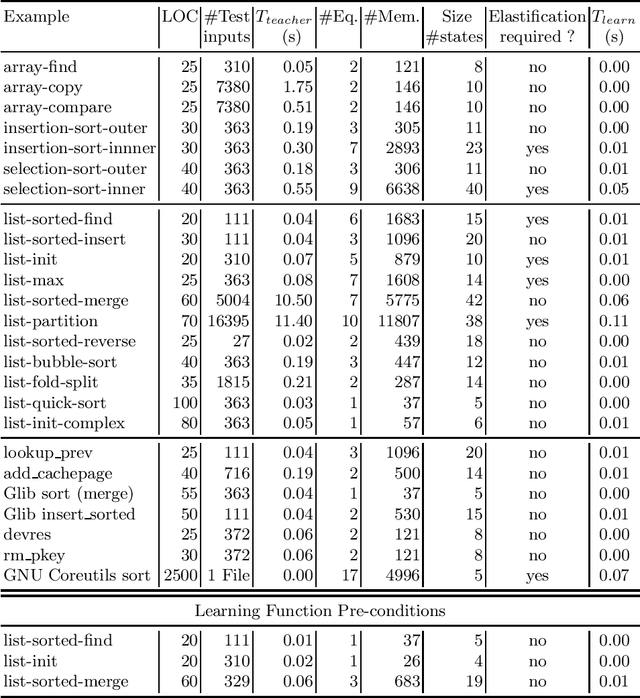
We propose a new automaton model, called quantified data automata over words, that can model quantified invariants over linear data structures, and build poly-time active learning algorithms for them, where the learner is allowed to query the teacher with membership and equivalence queries. In order to express invariants in decidable logics, we invent a decidable subclass of QDAs, called elastic QDAs, and prove that every QDA has a unique minimally-over-approximating elastic QDA. We then give an application of these theoretically sound and efficient active learning algorithms in a passive learning framework and show that we can efficiently learn quantified linear data structure invariants from samples obtained from dynamic runs for a large class of programs.