 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRubric-Based Benchmarking and Reinforcement Learning for Advancing LLM Instruction Following
Nov 13, 2025Recent progress in large language models (LLMs) has led to impressive performance on a range of tasks, yet advanced instruction following (IF)-especially for complex, multi-turn, and system-prompted instructions-remains a significant challenge. Rigorous evaluation and effective training for such capabilities are hindered by the lack of high-quality, human-annotated benchmarks and reliable, interpretable reward signals. In this work, we introduce AdvancedIF (we will release this benchmark soon), a comprehensive benchmark featuring over 1,600 prompts and expert-curated rubrics that assess LLMs ability to follow complex, multi-turn, and system-level instructions. We further propose RIFL (Rubric-based Instruction-Following Learning), a novel post-training pipeline that leverages rubric generation, a finetuned rubric verifier, and reward shaping to enable effective reinforcement learning for instruction following. Extensive experiments demonstrate that RIFL substantially improves the instruction-following abilities of LLMs, achieving a 6.7% absolute gain on AdvancedIF and strong results on public benchmarks. Our ablation studies confirm the effectiveness of each component in RIFL. This work establishes rubrics as a powerful tool for both training and evaluating advanced IF in LLMs, paving the way for more capable and reliable AI systems.
Approximately Aligned Decoding
Oct 01, 2024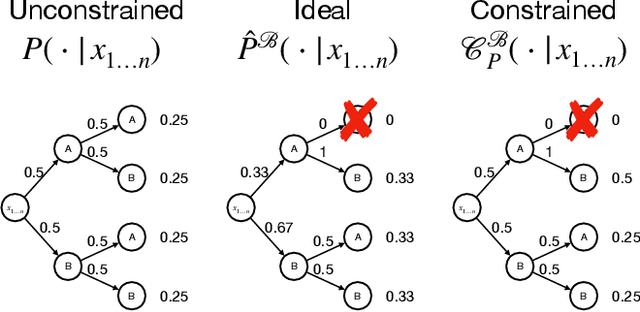
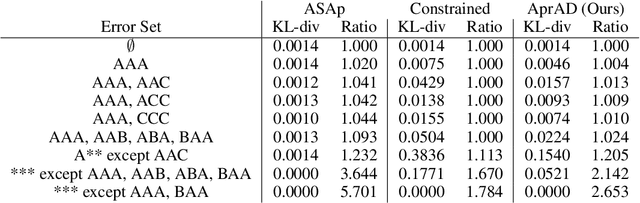

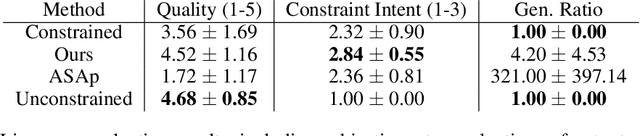
It is common to reject undesired outputs of Large Language Models (LLMs); however, current methods to do so require an excessive amount of computation, or severely distort the distribution of outputs. We present a method to balance the distortion of the output distribution with computational efficiency, allowing for the generation of long sequences of text with difficult-to-satisfy constraints, with less amplification of low probability outputs compared to existing methods. We show through a series of experiments that the task-specific performance of our method is comparable to methods that do not distort the output distribution, while being much more computationally efficient.
Greener yet Powerful: Taming Large Code Generation Models with Quantization
Mar 09, 2023
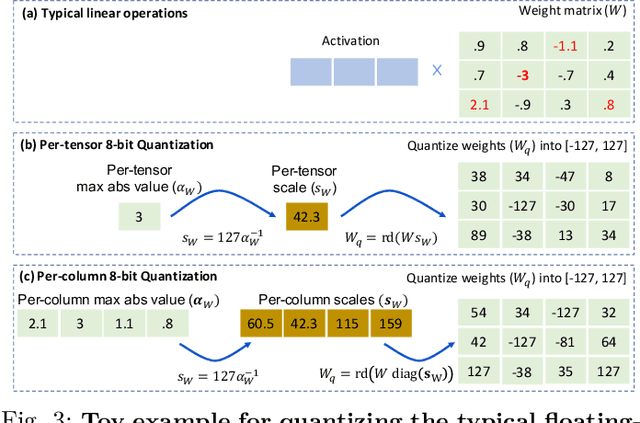
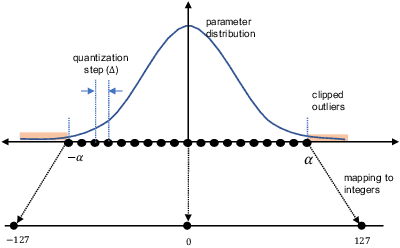
ML-powered code generation aims to assist developers to write code in a more productive manner, by intelligently generating code blocks based on natural language prompts. Recently, large pretrained deep learning models have substantially pushed the boundary of code generation and achieved impressive performance. Despite their great power, the huge number of model parameters poses a significant threat to adapting them in a regular software development environment, where a developer might use a standard laptop or mid-size server to develop her code. Such large models incur significant resource usage (in terms of memory, latency, and dollars) as well as carbon footprint. Model compression is a promising approach to address these challenges. Several techniques are proposed to compress large pretrained models typically used for vision or textual data. Out of many available compression techniques, we identified that quantization is mostly applicable for code generation task as it does not require significant retraining cost. As quantization represents model parameters with lower-bit integer (e.g., int8), the model size and runtime latency would both benefit from such int representation. We extensively study the impact of quantized model on code generation tasks across different dimension: (i) resource usage and carbon footprint, (ii) accuracy, and (iii) robustness. To this end, through systematic experiments we find a recipe of quantization technique that could run even a $6$B model in a regular laptop without significant accuracy or robustness degradation. We further found the recipe is readily applicable to code summarization task as well.