 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreener yet Powerful: Taming Large Code Generation Models with Quantization
Paper and Code
Mar 09, 2023
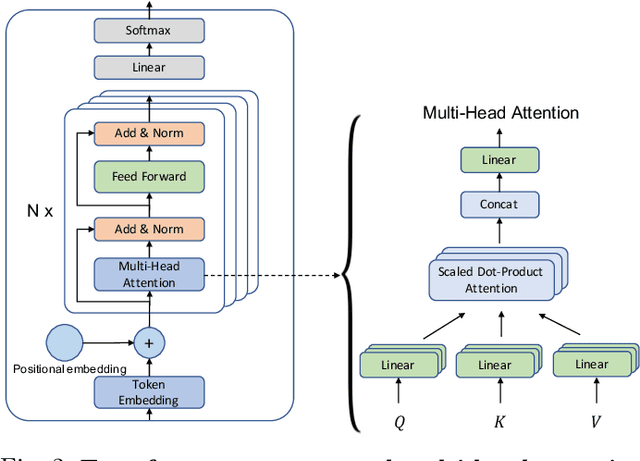
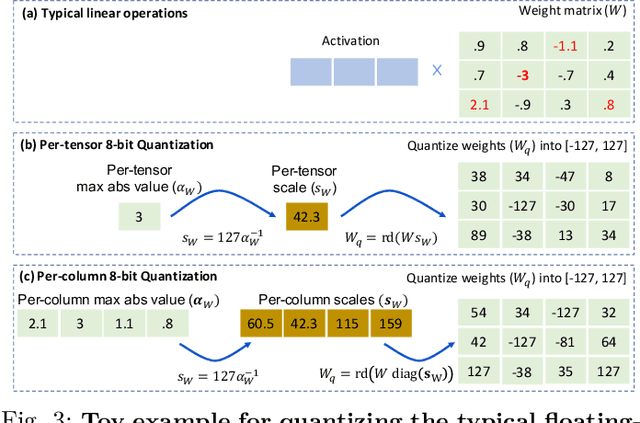
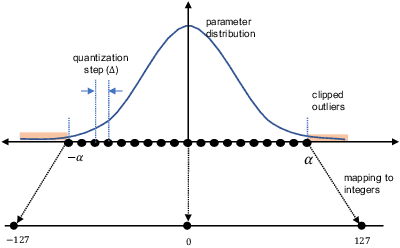
ML-powered code generation aims to assist developers to write code in a more productive manner, by intelligently generating code blocks based on natural language prompts. Recently, large pretrained deep learning models have substantially pushed the boundary of code generation and achieved impressive performance. Despite their great power, the huge number of model parameters poses a significant threat to adapting them in a regular software development environment, where a developer might use a standard laptop or mid-size server to develop her code. Such large models incur significant resource usage (in terms of memory, latency, and dollars) as well as carbon footprint. Model compression is a promising approach to address these challenges. Several techniques are proposed to compress large pretrained models typically used for vision or textual data. Out of many available compression techniques, we identified that quantization is mostly applicable for code generation task as it does not require significant retraining cost. As quantization represents model parameters with lower-bit integer (e.g., int8), the model size and runtime latency would both benefit from such int representation. We extensively study the impact of quantized model on code generation tasks across different dimension: (i) resource usage and carbon footprint, (ii) accuracy, and (iii) robustness. To this end, through systematic experiments we find a recipe of quantization technique that could run even a $6$B model in a regular laptop without significant accuracy or robustness degradation. We further found the recipe is readily applicable to code summarization task as well.