 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperparameter Optimization in Machine Learning
Oct 30, 2024



Hyperparameters are configuration variables controlling the behavior of machine learning algorithms. They are ubiquitous in machine learning and artificial intelligence and the choice of their values determine the effectiveness of systems based on these technologies. Manual hyperparameter search is often unsatisfactory and becomes unfeasible when the number of hyperparameters is large. Automating the search is an important step towards automating machine learning, freeing researchers and practitioners alike from the burden of finding a good set of hyperparameters by trial and error. In this survey, we present a unified treatment of hyperparameter optimization, providing the reader with examples and insights into the state-of-the-art. We cover the main families of techniques to automate hyperparameter search, often referred to as hyperparameter optimization or tuning, including random and quasi-random search, bandit-, model- and gradient- based approaches. We further discuss extensions, including online, constrained, and multi-objective formulations, touch upon connections with other fields such as meta-learning and neural architecture search, and conclude with open questions and future research directions.
Structural Pruning of Pre-trained Language Models via Neural Architecture Search
May 03, 2024



Pre-trained language models (PLM), for example BERT or RoBERTa, mark the state-of-the-art for natural language understanding task when fine-tuned on labeled data. However, their large size poses challenges in deploying them for inference in real-world applications, due to significant GPU memory requirements and high inference latency. This paper explores neural architecture search (NAS) for structural pruning to find sub-parts of the fine-tuned network that optimally trade-off efficiency, for example in terms of model size or latency, and generalization performance. We also show how we can utilize more recently developed two-stage weight-sharing NAS approaches in this setting to accelerate the search process. Unlike traditional pruning methods with fixed thresholds, we propose to adopt a multi-objective approach that identifies the Pareto optimal set of sub-networks, allowing for a more flexible and automated compression process.
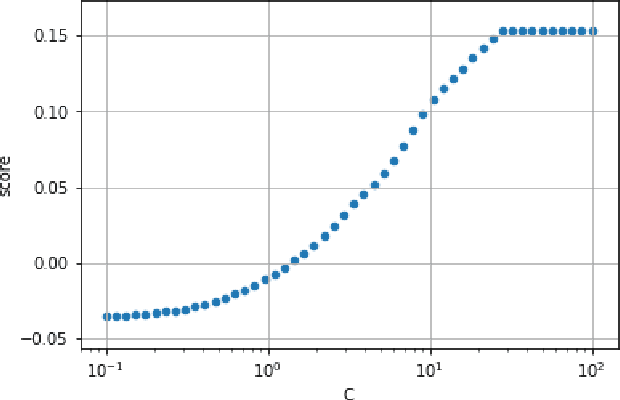
A Simple and Fast Baseline for Tuning Large XGBoost Models
Nov 12, 2021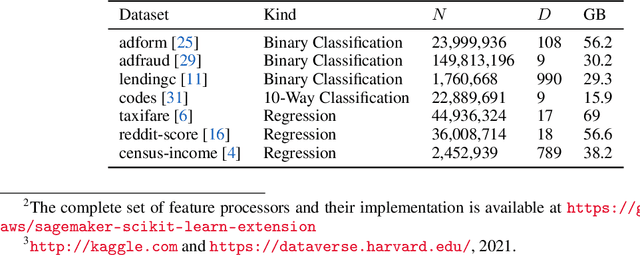
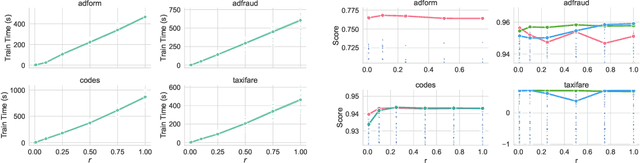
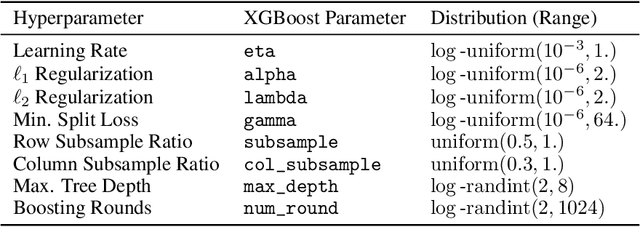
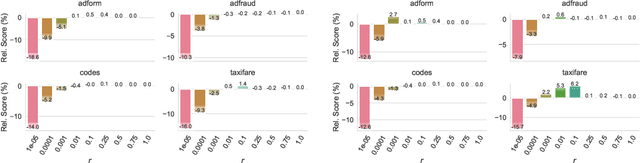
XGBoost, a scalable tree boosting algorithm, has proven effective for many prediction tasks of practical interest, especially using tabular datasets. Hyperparameter tuning can further improve the predictive performance, but unlike neural networks, full-batch training of many models on large datasets can be time consuming. Owing to the discovery that (i) there is a strong linear relation between dataset size & training time, (ii) XGBoost models satisfy the ranking hypothesis, and (iii) lower-fidelity models can discover promising hyperparameter configurations, we show that uniform subsampling makes for a simple yet fast baseline to speed up the tuning of large XGBoost models using multi-fidelity hyperparameter optimization with data subsets as the fidelity dimension. We demonstrate the effectiveness of this baseline on large-scale tabular datasets ranging from $15-70\mathrm{GB}$ in size.
A Nonmyopic Approach to Cost-Constrained Bayesian Optimization
Jun 10, 2021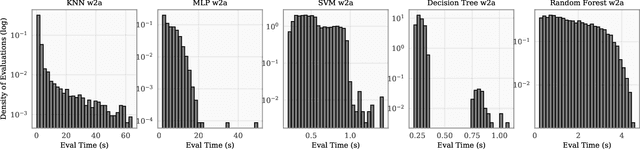



Bayesian optimization (BO) is a popular method for optimizing expensive-to-evaluate black-box functions. BO budgets are typically given in iterations, which implicitly assumes each evaluation has the same cost. In fact, in many BO applications, evaluation costs vary significantly in different regions of the search space. In hyperparameter optimization, the time spent on neural network training increases with layer size; in clinical trials, the monetary cost of drug compounds vary; and in optimal control, control actions have differing complexities. Cost-constrained BO measures convergence with alternative cost metrics such as time, money, or energy, for which the sample efficiency of standard BO methods is ill-suited. For cost-constrained BO, cost efficiency is far more important than sample efficiency. In this paper, we formulate cost-constrained BO as a constrained Markov decision process (CMDP), and develop an efficient rollout approximation to the optimal CMDP policy that takes both the cost and future iterations into account. We validate our method on a collection of hyperparameter optimization problems as well as a sensor set selection application.
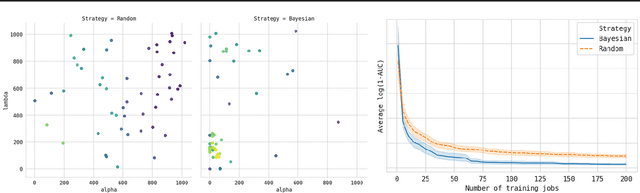
A multi-objective perspective on jointly tuning hardware and hyperparameters
Jun 10, 2021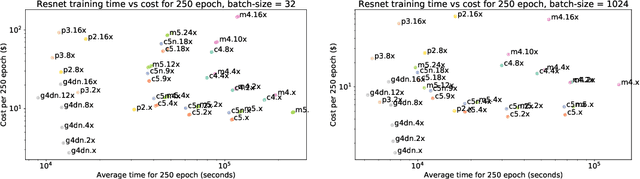
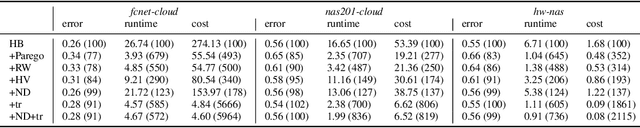

In addition to the best model architecture and hyperparameters, a full AutoML solution requires selecting appropriate hardware automatically. This can be framed as a multi-objective optimization problem: there is not a single best hardware configuration but a set of optimal ones achieving different trade-offs between cost and runtime. In practice, some choices may be overly costly or take days to train. To lift this burden, we adopt a multi-objective approach that selects and adapts the hardware configuration automatically alongside neural architectures and their hyperparameters. Our method builds on Hyperband and extends it in two ways. First, we replace the stopping rule used in Hyperband by a non-dominated sorting rule to preemptively stop unpromising configurations. Second, we leverage hyperparameter evaluations from related tasks via transfer learning by building a probabilistic estimate of the Pareto front that finds promising configurations more efficiently than random search. We show in extensive NAS and HPO experiments that both ingredients bring significant speed-ups and cost savings, with little to no impact on accuracy. In three benchmarks where hardware is selected in addition to hyperparameters, we obtain runtime and cost reductions of at least 5.8x and 8.8x, respectively. Furthermore, when applying our multi-objective method to the tuning of hyperparameters only, we obtain a 10\% improvement in runtime while maintaining the same accuracy on two popular NAS benchmarks.
Overfitting in Bayesian Optimization: an empirical study and early-stopping solution
Apr 16, 2021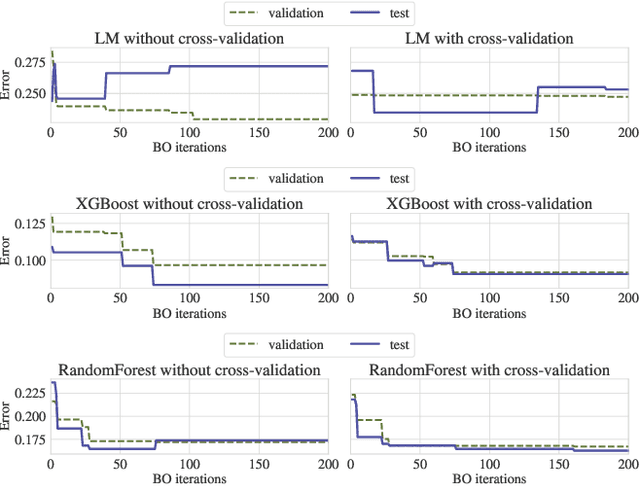
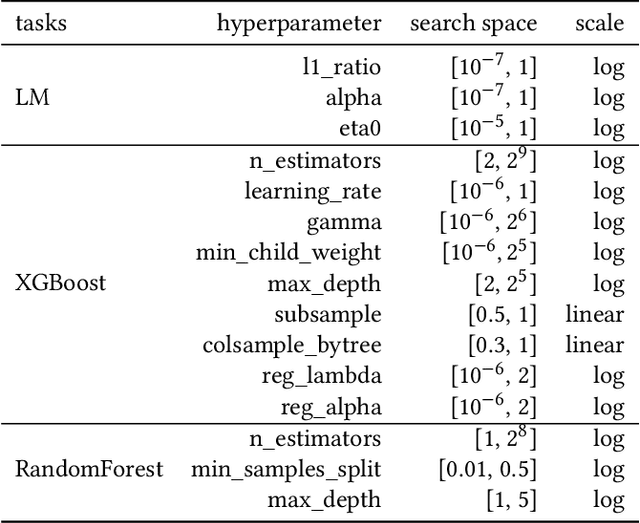
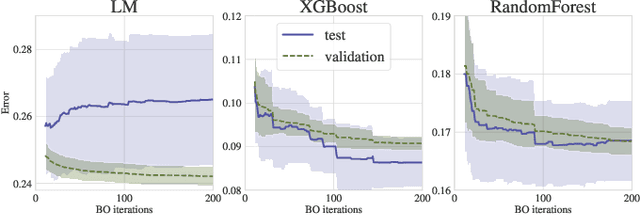
Bayesian Optimization (BO) is a successful methodology to tune the hyperparameters of machine learning algorithms. The user defines a metric of interest, such as the validation error, and BO finds the optimal hyperparameters that minimize it. However, the metric improvements on the validation set may not translate to the test set, especially on small datasets. In other words, BO can overfit. While cross-validation mitigates this, it comes with high computational cost. In this paper, we carry out the first systematic investigation of overfitting in BO and demonstrate that this is a serious yet often overlooked concern in practice. We propose the first problem-adaptive and interpretable criterion to early stop BO, reducing overfitting while mitigating the cost of cross-validation. Experimental results on real-world hyperparameter optimization tasks show that our approach can substantially reduce compute time with little to no loss of test accuracy,demonstrating a clear practical advantage over existing techniques.
Lexical semantic change for Ancient Greek and Latin
Jan 22, 2021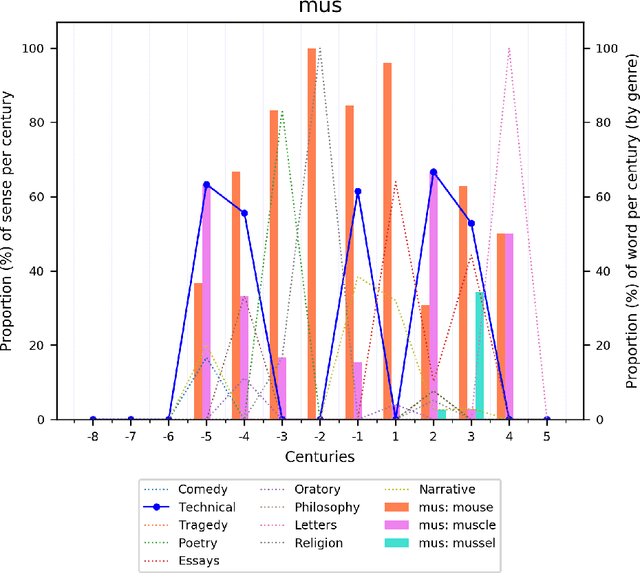
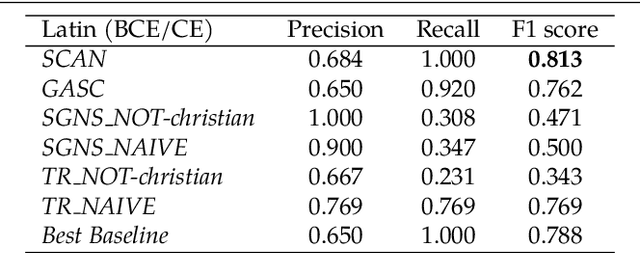
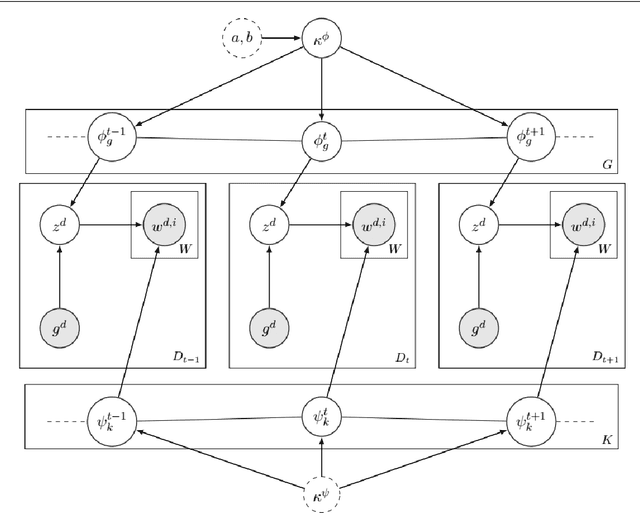
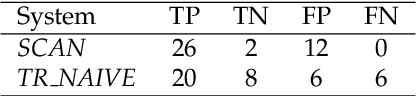
Change and its precondition, variation, are inherent in languages. Over time, new words enter the lexicon, others become obsolete, and existing words acquire new senses. Associating a word's correct meaning in its historical context is a central challenge in diachronic research. Historical corpora of classical languages, such as Ancient Greek and Latin, typically come with rich metadata, and existing models are limited by their inability to exploit contextual information beyond the document timestamp. While embedding-based methods feature among the current state of the art systems, they are lacking in the interpretative power. In contrast, Bayesian models provide explicit and interpretable representations of semantic change phenomena. In this chapter we build on GASC, a recent computational approach to semantic change based on a dynamic Bayesian mixture model. In this model, the evolution of word senses over time is based not only on distributional information of lexical nature, but also on text genres. We provide a systematic comparison of dynamic Bayesian mixture models for semantic change with state-of-the-art embedding-based models. On top of providing a full description of meaning change over time, we show that Bayesian mixture models are highly competitive approaches to detect binary semantic change in both Ancient Greek and Latin.
Amazon SageMaker Autopilot: a white box AutoML solution at scale
Dec 16, 2020
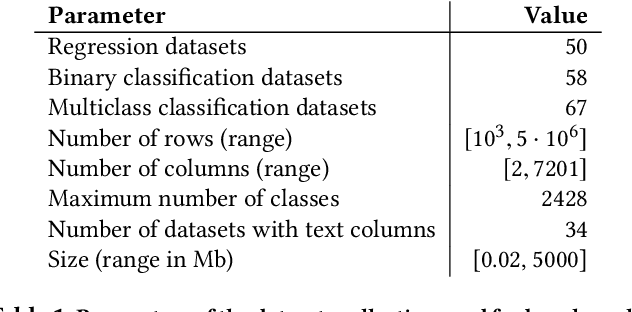
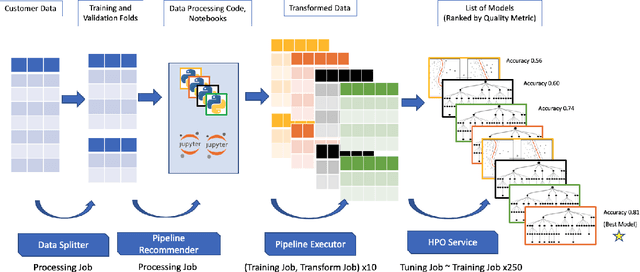
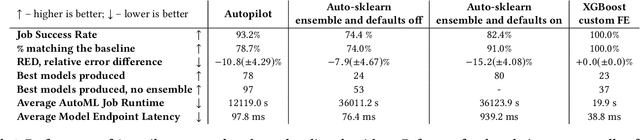
AutoML systems provide a black-box solution to machine learning problems by selecting the right way of processing features, choosing an algorithm and tuning the hyperparameters of the entire pipeline. Although these systems perform well on many datasets, there is still a non-negligible number of datasets for which the one-shot solution produced by each particular system would provide sub-par performance. In this paper, we present Amazon SageMaker Autopilot: a fully managed system providing an automated ML solution that can be modified when needed. Given a tabular dataset and the target column name, Autopilot identifies the problem type, analyzes the data and produces a diverse set of complete ML pipelines including feature preprocessing and ML algorithms, which are tuned to generate a leaderboard of candidate models. In the scenario where the performance is not satisfactory, a data scientist is able to view and edit the proposed ML pipelines in order to infuse their expertise and business knowledge without having to revert to a fully manual solution. This paper describes the different components of Autopilot, emphasizing the infrastructure choices that allow scalability, high quality models, editable ML pipelines, consumption of artifacts of offline meta-learning, and a convenient integration with the entire SageMaker suite allowing these trained models to be used in a production setting.
Amazon SageMaker Automatic Model Tuning: Scalable Black-box Optimization
Dec 15, 2020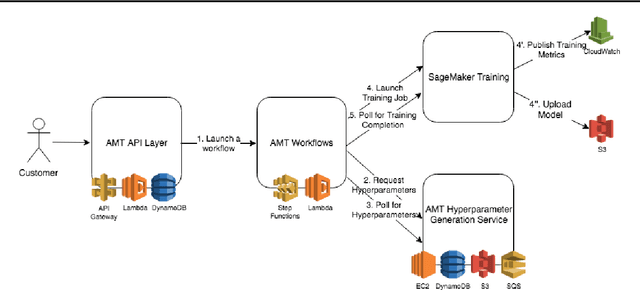
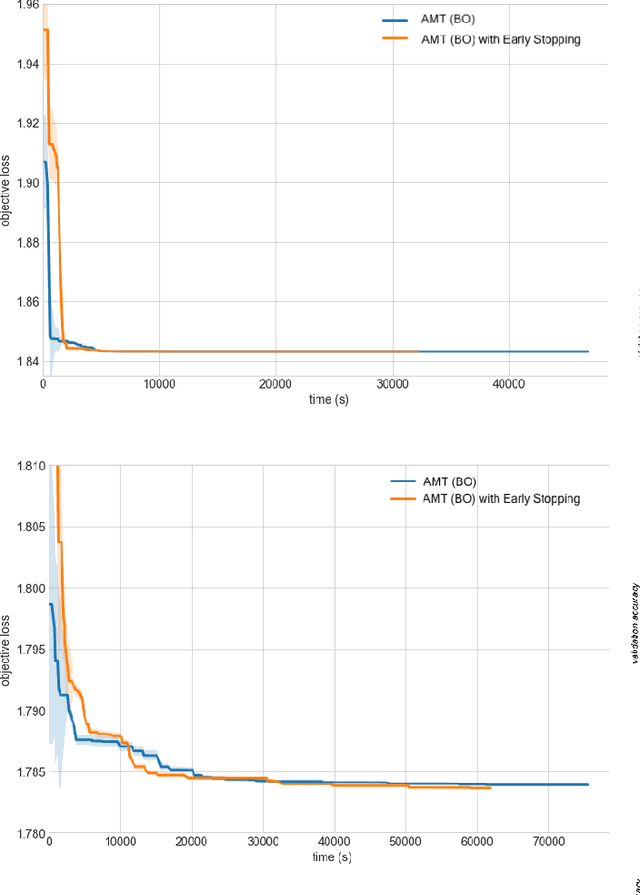
Tuning complex machine learning systems is challenging. Machine learning models typically expose a set of hyperparameters, be it regularization, architecture, or optimization parameters, whose careful tuning is critical to achieve good performance. To democratize access to such systems, it is essential to automate this tuning process. This paper presents Amazon SageMaker Automatic Model Tuning (AMT), a fully managed system for black-box optimization at scale. AMT finds the best version of a machine learning model by repeatedly training it with different hyperparameter configurations. It leverages either random search or Bayesian optimization to choose the hyperparameter values resulting in the best-performing model, as measured by the metric chosen by the user. AMT can be used with built-in algorithms, custom algorithms, and Amazon SageMaker pre-built containers for machine learning frameworks. We discuss the core functionality, system architecture and our design principles. We also describe some more advanced features provided by AMT, such as automated early stopping and warm-starting, demonstrating their benefits in experiments.
Pareto-efficient Acquisition Functions for Cost-Aware Bayesian Optimization
Nov 24, 2020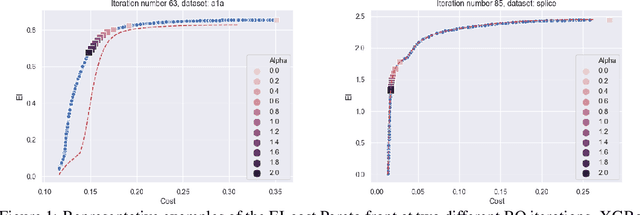

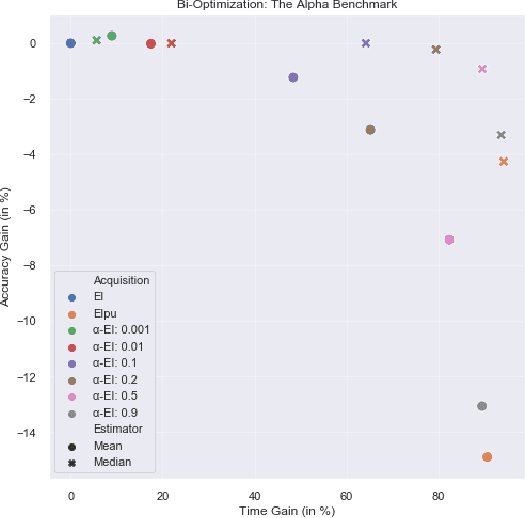
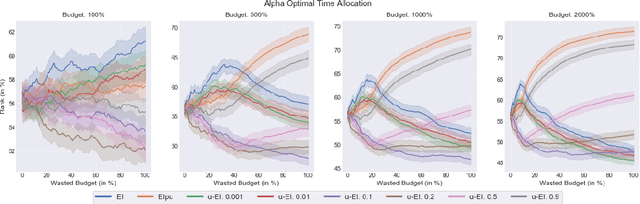
Bayesian optimization (BO) is a popular method to optimize expensive black-box functions. It efficiently tunes machine learning algorithms under the implicit assumption that hyperparameter evaluations cost approximately the same. In reality, the cost of evaluating different hyperparameters, be it in terms of time, dollars or energy, can span several orders of magnitude of difference. While a number of heuristics have been proposed to make BO cost-aware, none of these have been proven to work robustly. In this work, we reformulate cost-aware BO in terms of Pareto efficiency and introduce the cost Pareto Front, a mathematical object allowing us to highlight the shortcomings of commonly used acquisition functions. Based on this, we propose a novel Pareto-efficient adaptation of the expected improvement. On 144 real-world black-box function optimization problems we show that our Pareto-efficient acquisition functions significantly outperform previous solutions, bringing up to 50% speed-ups while providing finer control over the cost-accuracy trade-off. We also revisit the common choice of Gaussian process cost models, showing that simple, low-variance cost models predict training times effectively.