 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo SMOTE, or not to SMOTE?
Jan 24, 2022
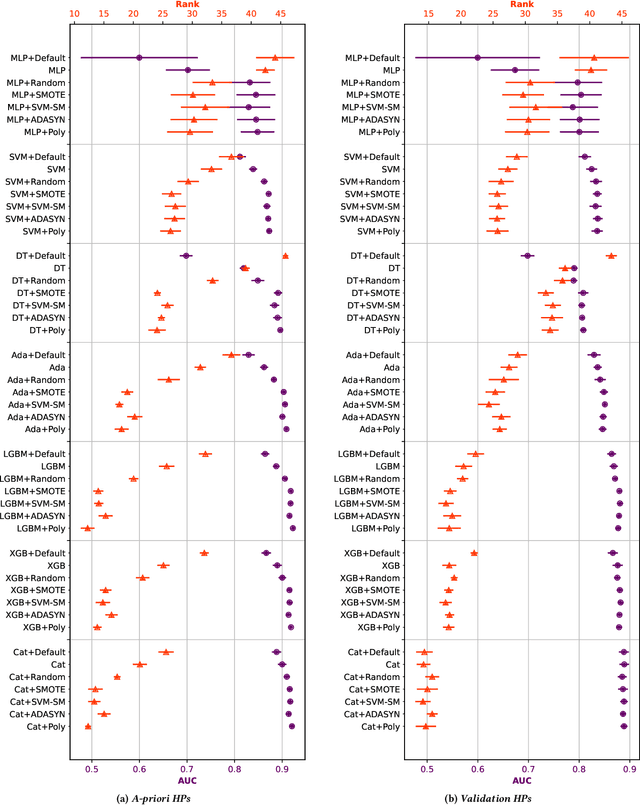

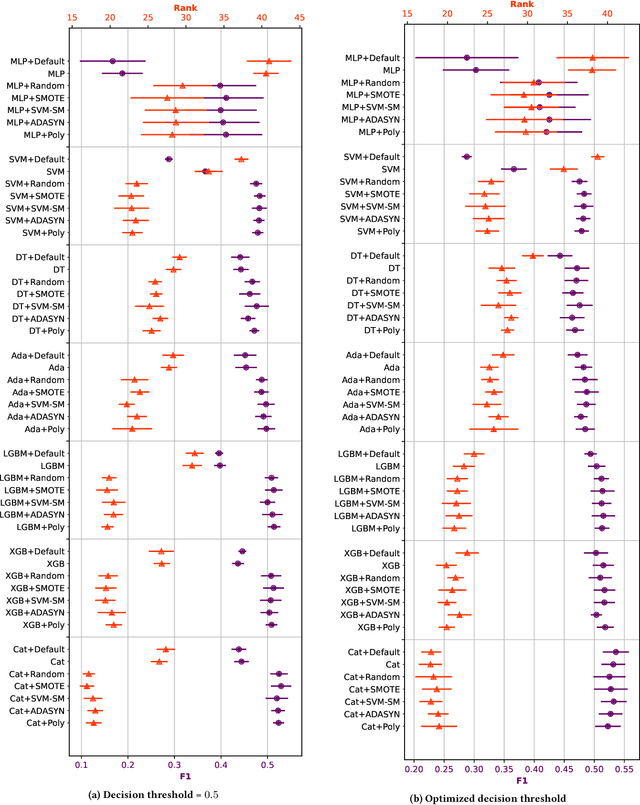
In imbalanced binary classification problems the objective metric is often non-symmetric and associates a higher penalty with the minority samples. On the other hand, the loss function used for training is usually symmetric - equally penalizing majority and minority samples. Balancing schemes, that augment the data to be more balanced before training the model, were proposed to address this discrepancy and were shown to improve prediction performance empirically on tabular data. However, recent studies of consistent classifiers suggest that the metric discrepancy might not hinder prediction performance. In light of these recent theoretical results, we carefully revisit the empirical study of balancing tabular data. Our extensive experiments, on 73 datasets, show that generally, in accordance with theory, best prediction is achieved by using a strong consistent classifier and balancing is not beneficial. We further identity several scenarios for which balancing is effective and observe that prior studies mainly focus on these settings.
Synthesising Multi-Modal Minority Samples for Tabular Data
May 17, 2021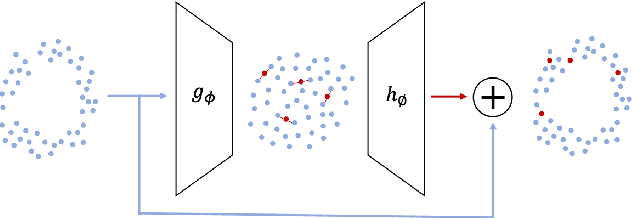
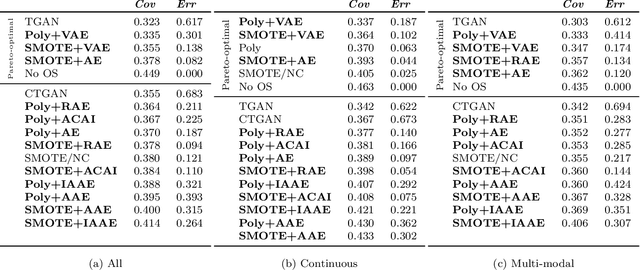
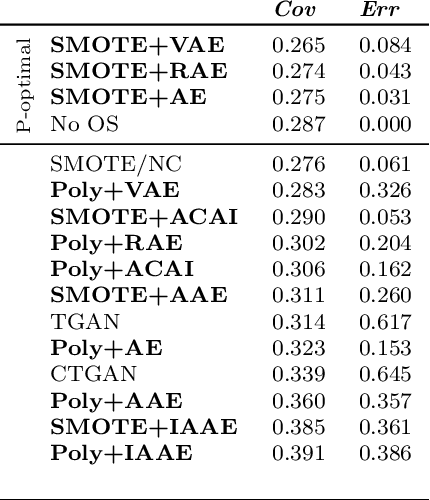
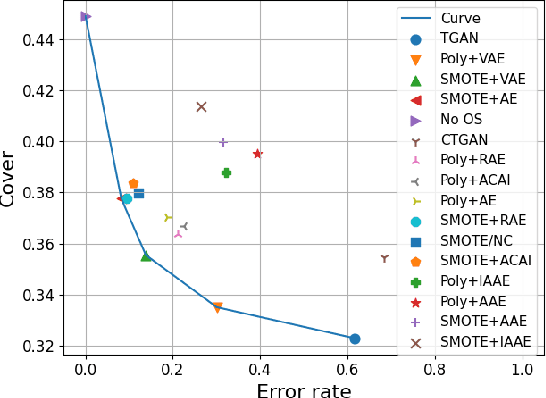
Real-world binary classification tasks are in many cases imbalanced, where the minority class is much smaller than the majority class. This skewness is challenging for machine learning algorithms as they tend to focus on the majority and greatly misclassify the minority. Adding synthetic minority samples to the dataset before training the model is a popular technique to address this difficulty and is commonly achieved by interpolating minority samples. Tabular datasets are often multi-modal and contain discrete (categorical) features in addition to continuous ones which makes interpolation of samples non-trivial. To address this, we propose a latent space interpolation framework which (1) maps the multi-modal samples to a dense continuous latent space using an autoencoder; (2) applies oversampling by interpolation in the latent space; and (3) maps the synthetic samples back to the original feature space. We defined metrics to directly evaluate the quality of the minority data generated and showed that our framework generates better synthetic data than the existing methods. Furthermore, the superior synthetic data yields better prediction quality in downstream binary classification tasks, as was demonstrated in extensive experiments with 27 publicly available real-world datasets
Amazon SageMaker Autopilot: a white box AutoML solution at scale
Dec 16, 2020
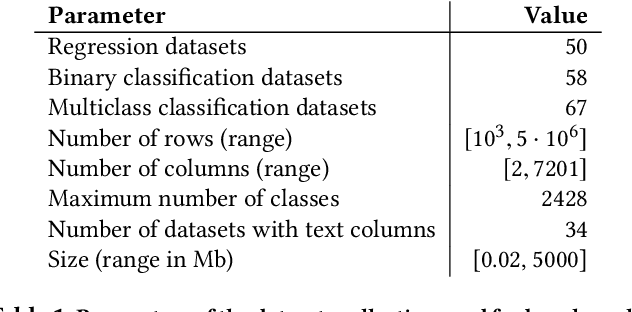
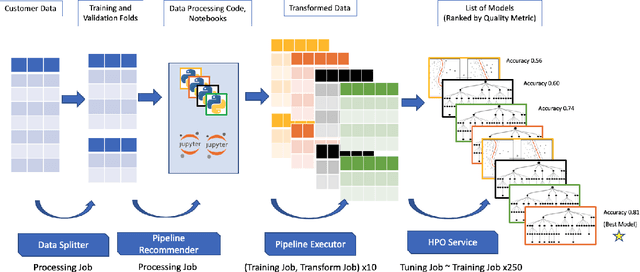
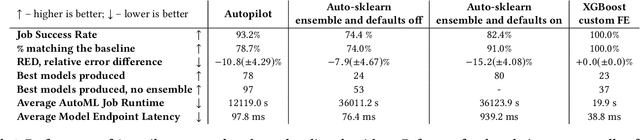
AutoML systems provide a black-box solution to machine learning problems by selecting the right way of processing features, choosing an algorithm and tuning the hyperparameters of the entire pipeline. Although these systems perform well on many datasets, there is still a non-negligible number of datasets for which the one-shot solution produced by each particular system would provide sub-par performance. In this paper, we present Amazon SageMaker Autopilot: a fully managed system providing an automated ML solution that can be modified when needed. Given a tabular dataset and the target column name, Autopilot identifies the problem type, analyzes the data and produces a diverse set of complete ML pipelines including feature preprocessing and ML algorithms, which are tuned to generate a leaderboard of candidate models. In the scenario where the performance is not satisfactory, a data scientist is able to view and edit the proposed ML pipelines in order to infuse their expertise and business knowledge without having to revert to a fully manual solution. This paper describes the different components of Autopilot, emphasizing the infrastructure choices that allow scalability, high quality models, editable ML pipelines, consumption of artifacts of offline meta-learning, and a convenient integration with the entire SageMaker suite allowing these trained models to be used in a production setting.