 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesising Multi-Modal Minority Samples for Tabular Data
Paper and Code
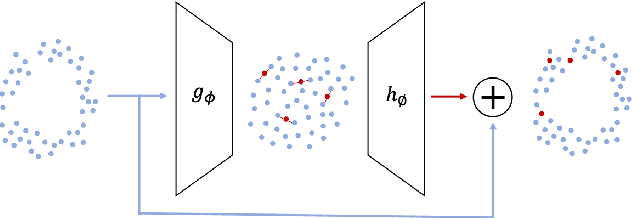
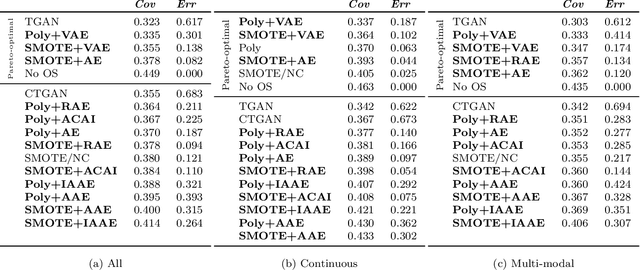
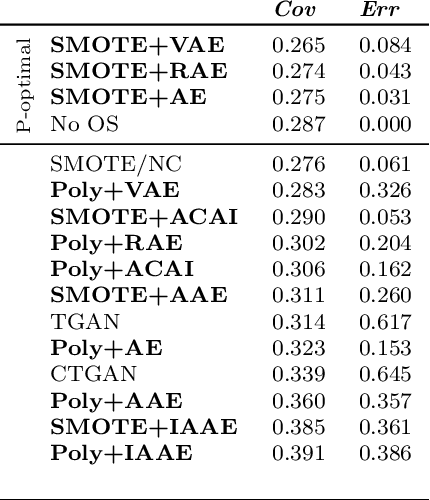
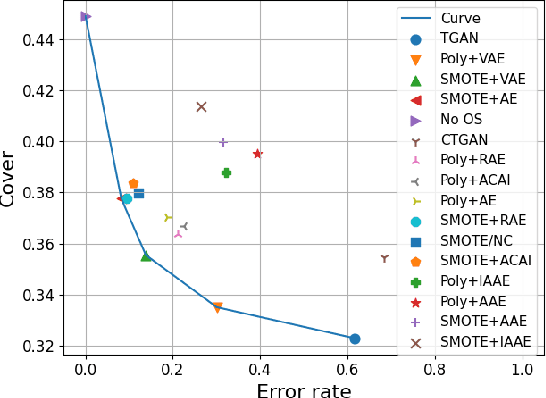
Real-world binary classification tasks are in many cases imbalanced, where the minority class is much smaller than the majority class. This skewness is challenging for machine learning algorithms as they tend to focus on the majority and greatly misclassify the minority. Adding synthetic minority samples to the dataset before training the model is a popular technique to address this difficulty and is commonly achieved by interpolating minority samples. Tabular datasets are often multi-modal and contain discrete (categorical) features in addition to continuous ones which makes interpolation of samples non-trivial. To address this, we propose a latent space interpolation framework which (1) maps the multi-modal samples to a dense continuous latent space using an autoencoder; (2) applies oversampling by interpolation in the latent space; and (3) maps the synthetic samples back to the original feature space. We defined metrics to directly evaluate the quality of the minority data generated and showed that our framework generates better synthetic data than the existing methods. Furthermore, the superior synthetic data yields better prediction quality in downstream binary classification tasks, as was demonstrated in extensive experiments with 27 publicly available real-world datasets