 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
Ministral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
Voxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Magistral
Jun 12, 2025



We introduce Magistral, Mistral's first reasoning model and our own scalable reinforcement learning (RL) pipeline. Instead of relying on existing implementations and RL traces distilled from prior models, we follow a ground up approach, relying solely on our own models and infrastructure. Notably, we demonstrate a stack that enabled us to explore the limits of pure RL training of LLMs, present a simple method to force the reasoning language of the model, and show that RL on text data alone maintains most of the initial checkpoint's capabilities. We find that RL on text maintains or improves multimodal understanding, instruction following and function calling. We present Magistral Medium, trained for reasoning on top of Mistral Medium 3 with RL alone, and we open-source Magistral Small (Apache 2.0) which further includes cold-start data from Magistral Medium.
Large Language Model Critics for Execution-Free Evaluation of Code Changes
Jan 28, 2025



Large language models (LLMs) offer a promising way forward for automating software engineering tasks, such as bug fixes, feature additions, etc., via multi-step LLM-based agentic workflows. However, existing metrics for evaluating such workflows, mainly build status and occasionally log analysis, are too sparse and limited in providing the information needed to assess the quality of changes made. In this work, we designed LLM-based critics to derive well-structured and rigorous intermediate/step-level, execution-free evaluation proxies for repo-level code changes. Importantly, we assume access to the gold test patch for the problem (i.e., reference-aware) to assess both semantics and executability of generated patches. With the gold test patch as a reference, we predict executability of all editing locations with an F1 score of 91.6%, aggregating which, we can predict the build status in 84.8% of the instances in SWE-bench. In particular, such an execution-focused LLM critic outperforms other reference-free and reference-aware LLM critics by 38.9% to 72.5%. Moreover, we demonstrate the usefulness of such a reference-aware framework in comparing patches generated by different agentic workflows. Finally, we open-source the library developed for this project, which allows further usage for either other agentic workflows or other benchmarks. The source code is available at https://github.com/amazon-science/code-agent-eval.
Automated Evaluation of Retrieval-Augmented Language Models with Task-Specific Exam Generation
May 22, 2024



We propose a new method to measure the task-specific accuracy of Retrieval-Augmented Large Language Models (RAG). Evaluation is performed by scoring the RAG on an automatically-generated synthetic exam composed of multiple choice questions based on the corpus of documents associated with the task. Our method is an automated, cost-efficient, interpretable, and robust strategy to select the optimal components for a RAG system. We leverage Item Response Theory (IRT) to estimate the quality of an exam and its informativeness on task-specific accuracy. IRT also provides a natural way to iteratively improve the exam by eliminating the exam questions that are not sufficiently informative about a model's ability. We demonstrate our approach on four new open-ended Question-Answering tasks based on Arxiv abstracts, StackExchange questions, AWS DevOps troubleshooting guides, and SEC filings. In addition, our experiments reveal more general insights into factors impacting RAG performance like size, retrieval mechanism, prompting and fine-tuning. Most notably, our findings show that choosing the right retrieval algorithms often leads to bigger performance gains than simply using a larger language model.
Semi-Supervised Learning for Bilingual Lexicon Induction
Feb 10, 2024
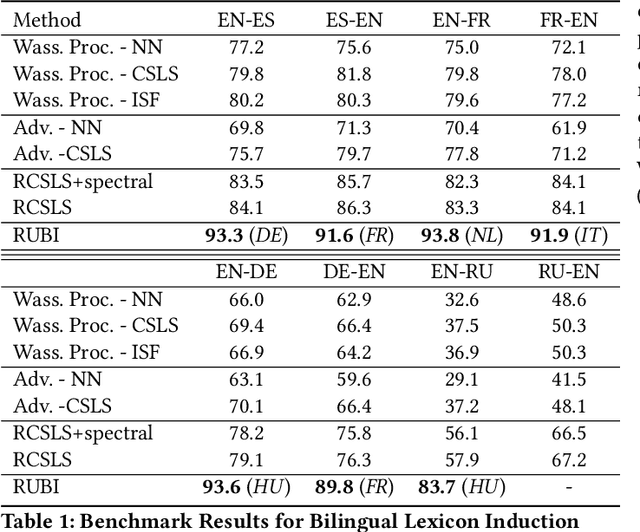

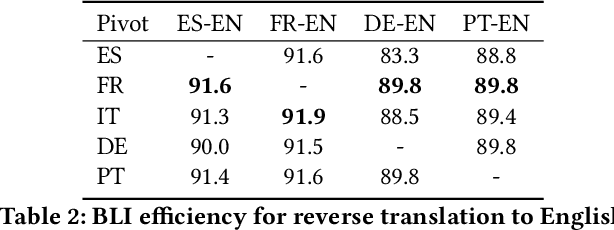
We consider the problem of aligning two sets of continuous word representations, corresponding to languages, to a common space in order to infer a bilingual lexicon. It was recently shown that it is possible to infer such lexicon, without using any parallel data, by aligning word embeddings trained on monolingual data. Such line of work is called unsupervised bilingual induction. By wondering whether it was possible to gain experience in the progressive learning of several languages, we asked ourselves to what extent we could integrate the knowledge of a given set of languages when learning a new one, without having parallel data for the latter. In other words, while keeping the core problem of unsupervised learning in the latest step, we allowed the access to other corpora of idioms, hence the name semi-supervised. This led us to propose a novel formulation, considering the lexicon induction as a ranking problem for which we used recent tools of this machine learning field. Our experiments on standard benchmarks, inferring dictionary from English to more than 20 languages, show that our approach consistently outperforms existing state of the art benchmark. In addition, we deduce from this new scenario several relevant conclusions allowing a better understanding of the alignment phenomenon.
MELODY: Robust Semi-Supervised Hybrid Model for Entity-Level Online Anomaly Detection with Multivariate Time Series
Jan 18, 2024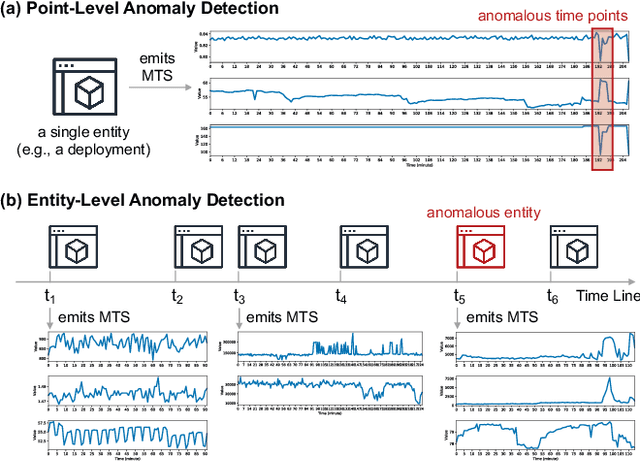

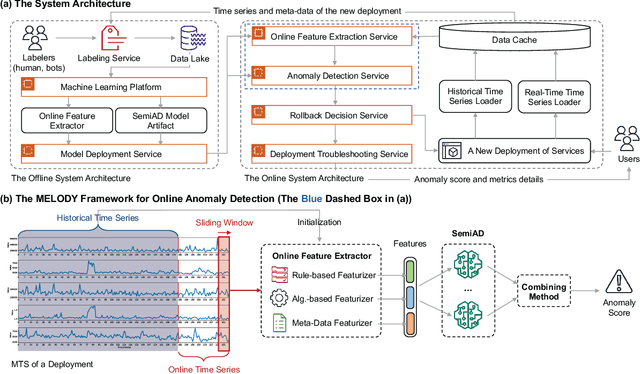
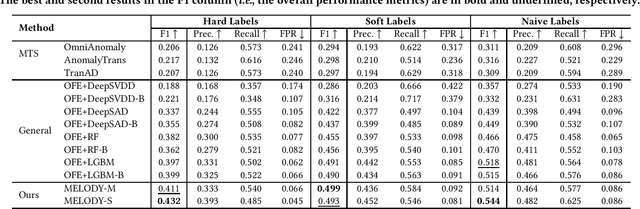
In large IT systems, software deployment is a crucial process in online services as their code is regularly updated. However, a faulty code change may degrade the target service's performance and cause cascading outages in downstream services. Thus, software deployments should be comprehensively monitored, and their anomalies should be detected timely. In this paper, we study the problem of anomaly detection for deployments. We begin by identifying the challenges unique to this anomaly detection problem, which is at entity-level (e.g., deployments), relative to the more typical problem of anomaly detection in multivariate time series (MTS). The unique challenges include the heterogeneity of deployments, the low latency tolerance, the ambiguous anomaly definition, and the limited supervision. To address them, we propose a novel framework, semi-supervised hybrid Model for Entity-Level Online Detection of anomalY (MELODY). MELODY first transforms the MTS of different entities to the same feature space by an online feature extractor, then uses a newly proposed semi-supervised deep one-class model for detecting anomalous entities. We evaluated MELODY on real data of cloud services with 1.2M+ time series. The relative F1 score improvement of MELODY over the state-of-the-art methods ranges from 7.6% to 56.5%. The user evaluation suggests MELODY is suitable for monitoring deployments in large online systems.
Effective Dimension in Bandit Problems under Censorship
Feb 14, 2023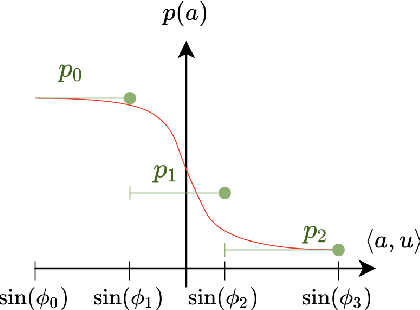



In this paper, we study both multi-armed and contextual bandit problems in censored environments. Our goal is to estimate the performance loss due to censorship in the context of classical algorithms designed for uncensored environments. Our main contributions include the introduction of a broad class of censorship models and their analysis in terms of the effective dimension of the problem -- a natural measure of its underlying statistical complexity and main driver of the regret bound. In particular, the effective dimension allows us to maintain the structure of the original problem at first order, while embedding it in a bigger space, and thus naturally leads to results analogous to uncensored settings. Our analysis involves a continuous generalization of the Elliptical Potential Inequality, which we believe is of independent interest. We also discover an interesting property of decision-making under censorship: a transient phase during which initial misspecification of censorship is self-corrected at an extra cost, followed by a stationary phase that reflects the inherent slowdown of learning governed by the effective dimension. Our results are useful for applications of sequential decision-making models where the feedback received depends on strategic uncertainty (e.g., agents' willingness to follow a recommendation) and/or random uncertainty (e.g., loss or delay in arrival of information).
* 45 pages, 5 figures, NeurIPS 2022