 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Pruning of Pre-trained Language Models via Neural Architecture Search
May 03, 2024



Pre-trained language models (PLM), for example BERT or RoBERTa, mark the state-of-the-art for natural language understanding task when fine-tuned on labeled data. However, their large size poses challenges in deploying them for inference in real-world applications, due to significant GPU memory requirements and high inference latency. This paper explores neural architecture search (NAS) for structural pruning to find sub-parts of the fine-tuned network that optimally trade-off efficiency, for example in terms of model size or latency, and generalization performance. We also show how we can utilize more recently developed two-stage weight-sharing NAS approaches in this setting to accelerate the search process. Unlike traditional pruning methods with fixed thresholds, we propose to adopt a multi-objective approach that identifies the Pareto optimal set of sub-networks, allowing for a more flexible and automated compression process.
A Corrected Expected Improvement Acquisition Function Under Noisy Observations
Oct 08, 2023



Sequential maximization of expected improvement (EI) is one of the most widely used policies in Bayesian optimization because of its simplicity and ability to handle noisy observations. In particular, the improvement function often uses the best posterior mean as the best incumbent in noisy settings. However, the uncertainty associated with the incumbent solution is often neglected in many analytic EI-type methods: a closed-form acquisition function is derived in the noise-free setting, but then applied to the setting with noisy observations. To address this limitation, we propose a modification of EI that corrects its closed-form expression by incorporating the covariance information provided by the Gaussian Process (GP) model. This acquisition function specializes to the classical noise-free result, and we argue should replace that formula in Bayesian optimization software packages, tutorials, and textbooks. This enhanced acquisition provides good generality for noisy and noiseless settings. We show that our method achieves a sublinear convergence rate on the cumulative regret bound under heteroscedastic observation noise. Our empirical results demonstrate that our proposed acquisition function can outperform EI in the presence of noisy observations on benchmark functions for black-box optimization, as well as on parameter search for neural network model compression.
Confidence-aware Personalized Federated Learning via Variational Expectation Maximization
May 21, 2023



Federated Learning (FL) is a distributed learning scheme to train a shared model across clients. One common and fundamental challenge in FL is that the sets of data across clients could be non-identically distributed and have different sizes. Personalized Federated Learning (PFL) attempts to solve this challenge via locally adapted models. In this work, we present a novel framework for PFL based on hierarchical Bayesian modeling and variational inference. A global model is introduced as a latent variable to augment the joint distribution of clients' parameters and capture the common trends of different clients, optimization is derived based on the principle of maximizing the marginal likelihood and conducted using variational expectation maximization. Our algorithm gives rise to a closed-form estimation of a confidence value which comprises the uncertainty of clients' parameters and local model deviations from the global model. The confidence value is used to weigh clients' parameters in the aggregation stage and adjust the regularization effect of the global model. We evaluate our method through extensive empirical studies on multiple datasets. Experimental results show that our approach obtains competitive results under mild heterogeneous circumstances while significantly outperforming state-of-the-art PFL frameworks in highly heterogeneous settings. Our code is available at https://github.com/JunyiZhu-AI/confidence_aware_PFL.
Meta-Cal: Well-controlled Post-hoc Calibration by Ranking
May 10, 2021


In many applications, it is desirable that a classifier not only makes accurate predictions, but also outputs calibrated probabilities. However, many existing classifiers, especially deep neural network classifiers, tend not to be calibrated. Post-hoc calibration is a technique to recalibrate a model, and its goal is to learn a calibration map. Existing approaches mostly focus on constructing calibration maps with low calibration errors. Contrary to these methods, we study post-hoc calibration for multi-class classification under constraints, as a calibrator with a low calibration error does not necessarily mean it is useful in practice. In this paper, we introduce two practical constraints to be taken into consideration. We then present Meta-Cal, which is built from a base calibrator and a ranking model. Under some mild assumptions, two high-probability bounds are given with respect to these constraints. Empirical results on CIFAR-10, CIFAR-100 and ImageNet and a range of popular network architectures show our proposed method significantly outperforms the current state of the art for post-hoc multi-class classification calibration.
Additive Tree-Structured Conditional Parameter Spaces in Bayesian Optimization: A Novel Covariance Function and a Fast Implementation
Oct 06, 2020



Bayesian optimization (BO) is a sample-efficient global optimization algorithm for black-box functions which are expensive to evaluate. Existing literature on model based optimization in conditional parameter spaces are usually built on trees. In this work, we generalize the additive assumption to tree-structured functions and propose an additive tree-structured covariance function, showing improved sample-efficiency, wider applicability and greater flexibility. Furthermore, by incorporating the structure information of parameter spaces and the additive assumption in the BO loop, we develop a parallel algorithm to optimize the acquisition function and this optimization can be performed in a low dimensional space. We demonstrate our method on an optimization benchmark function, on a neural network compression problem, on pruning pre-trained VGG16 and ResNet50 models as well as on searching activation functions of ResNet20. Experimental results show our approach significantly outperforms the current state of the art for conditional parameter optimization including SMAC, TPE and Jenatton et al. (2017).
Additive Tree-Structured Covariance Function for Conditional Parameter Spaces in Bayesian Optimization
Jun 21, 2020
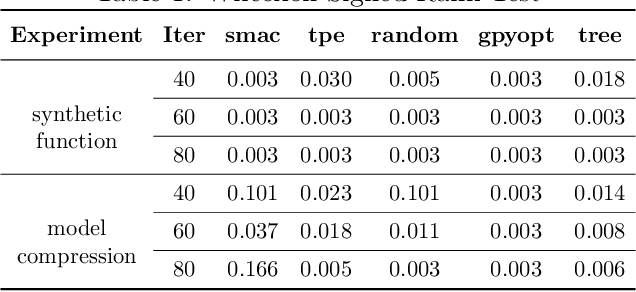


Bayesian optimization (BO) is a sample-efficient global optimization algorithm for black-box functions which are expensive to evaluate. Existing literature on model based optimization in conditional parameter spaces are usually built on trees. In this work, we generalize the additive assumption to tree-structured functions and propose an additive tree-structured covariance function, showing improved sample-efficiency, wider applicability and greater flexibility. Furthermore, by incorporating the structure information of parameter spaces and the additive assumption in the BO loop, we develop a parallel algorithm to optimize the acquisition function and this optimization can be performed in a low dimensional space. We demonstrate our method on an optimization benchmark function, as well as on a neural network model compression problem, and experimental results show our approach significantly outperforms the current state of the art for conditional parameter optimization including SMAC, TPE and Jenatton et al. (2017).
* AISTATS2020. Code link: https://github.com/maxc01/addtree