 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-Matching Coresets for Rehearsal-Based Continual Learning
Paper and Code
Mar 28, 2022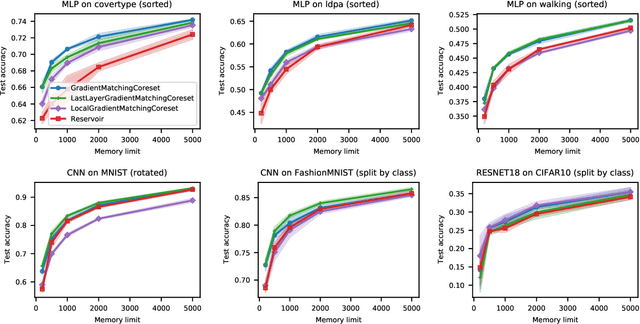
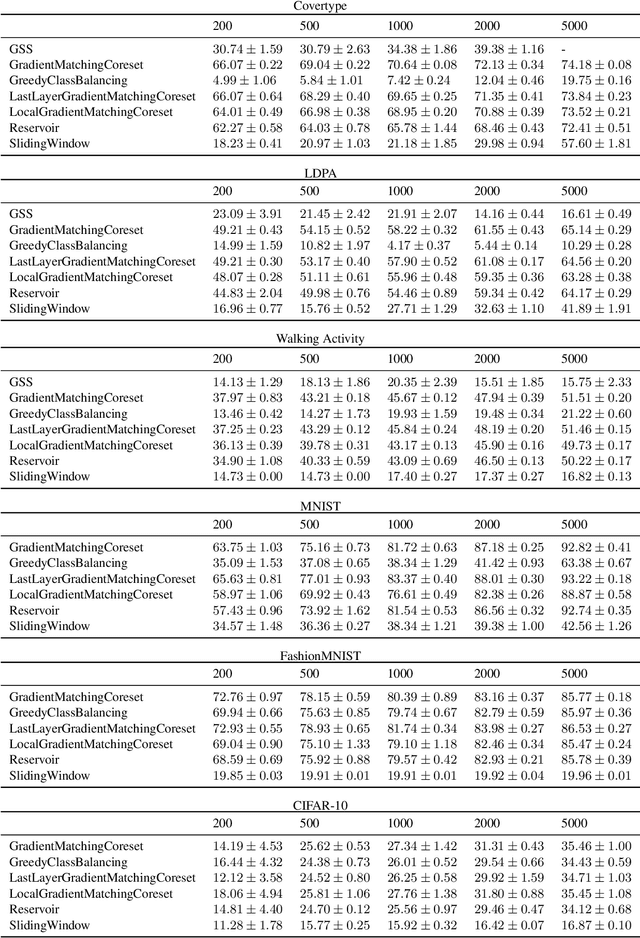
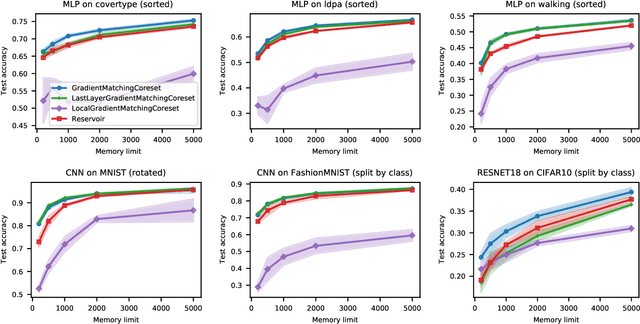
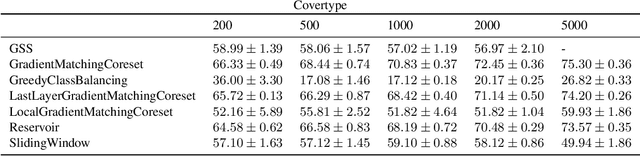
The goal of continual learning (CL) is to efficiently update a machine learning model with new data without forgetting previously-learned knowledge. Most widely-used CL methods rely on a rehearsal memory of data points to be reused while training on new data. Curating such a rehearsal memory to maintain a small, informative subset of all the data seen so far is crucial to the success of these methods. We devise a coreset selection method for rehearsal-based continual learning. Our method is based on the idea of gradient matching: The gradients induced by the coreset should match, as closely as possible, those induced by the original training dataset. Inspired by the neural tangent kernel theory, we perform this gradient matching across the model's initialization distribution, allowing us to extract a coreset without having to train the model first. We evaluate the method on a wide range of continual learning scenarios and demonstrate that it improves the performance of rehearsal-based CL methods compared to competing memory management strategies such as reservoir sampling.