 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Staged Deep Learning Approach to Spatial Refinement in 3D Temporal Atmospheric Transport
Dec 14, 2024High-resolution spatiotemporal simulations effectively capture the complexities of atmospheric plume dispersion in complex terrain. However, their high computational cost makes them impractical for applications requiring rapid responses or iterative processes, such as optimization, uncertainty quantification, or inverse modeling. To address this challenge, this work introduces the Dual-Stage Temporal Three-dimensional UNet Super-resolution (DST3D-UNet-SR) model, a highly efficient deep learning model for plume dispersion prediction. DST3D-UNet-SR is composed of two sequential modules: the temporal module (TM), which predicts the transient evolution of a plume in complex terrain from low-resolution temporal data, and the spatial refinement module (SRM), which subsequently enhances the spatial resolution of the TM predictions. We train DST3DUNet- SR using a comprehensive dataset derived from high-resolution large eddy simulations (LES) of plume transport. We propose the DST3D-UNet-SR model to significantly accelerate LES simulations of three-dimensional plume dispersion by three orders of magnitude. Additionally, the model demonstrates the ability to dynamically adapt to evolving conditions through the incorporation of new observational data, substantially improving prediction accuracy in high-concentration regions near the source. Keywords: Atmospheric sciences, Geosciences, Plume transport,3D temporal sequences, Artificial intelligence, CNN, LSTM, Autoencoder, Autoregressive model, U-Net, Super-resolution, Spatial Refinement.
Multi-fidelity Fourier Neural Operator for Fast Modeling of Large-Scale Geological Carbon Storage
Aug 23, 2023



Deep learning-based surrogate models have been widely applied in geological carbon storage (GCS) problems to accelerate the prediction of reservoir pressure and CO2 plume migration. Large amounts of data from physics-based numerical simulators are required to train a model to accurately predict the complex physical behaviors associated with this process. In practice, the available training data are always limited in large-scale 3D problems due to the high computational cost. Therefore, we propose to use a multi-fidelity Fourier Neural Operator to solve large-scale GCS problems with more affordable multi-fidelity training datasets. The Fourier Neural Operator has a desirable grid-invariant property, which simplifies the transfer learning procedure between datasets with different discretization. We first test the model efficacy on a GCS reservoir model being discretized into 110k grid cells. The multi-fidelity model can predict with accuracy comparable to a high-fidelity model trained with the same amount of high-fidelity data with 81% less data generation costs. We further test the generalizability of the multi-fidelity model on a same reservoir model with a finer discretization of 1 million grid cells. This case was made more challenging by employing high-fidelity and low-fidelity datasets generated by different geostatistical models and reservoir simulators. We observe that the multi-fidelity FNO model can predict pressure fields with reasonable accuracy even when the high-fidelity data are extremely limited.
Combining Deep Learning with Physics Based Features in Explosion-Earthquake Discrimination
Mar 12, 2022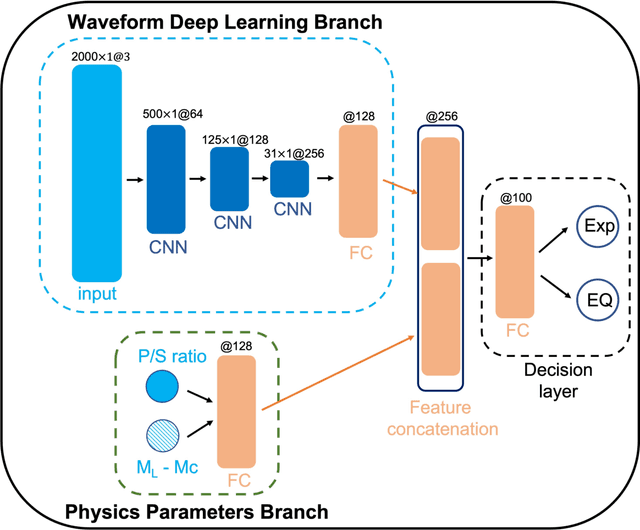
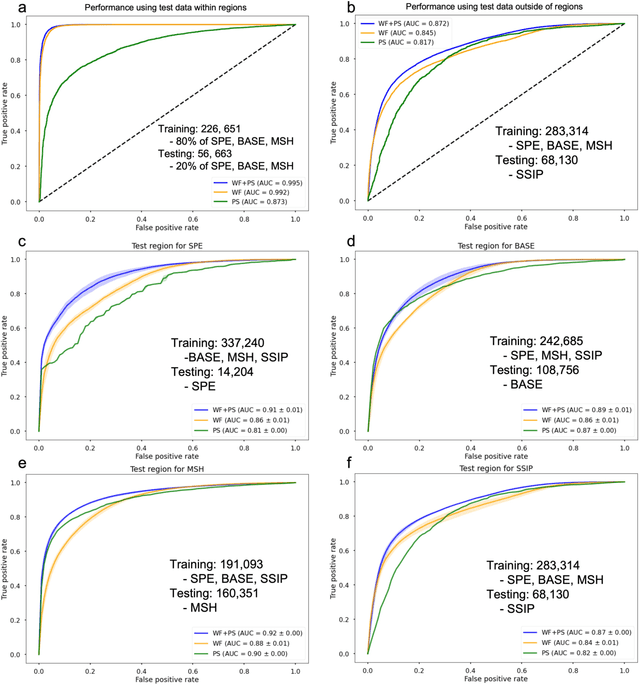
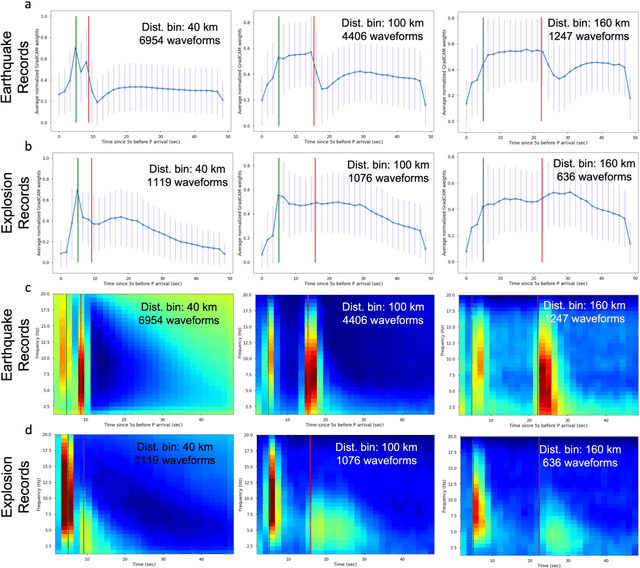
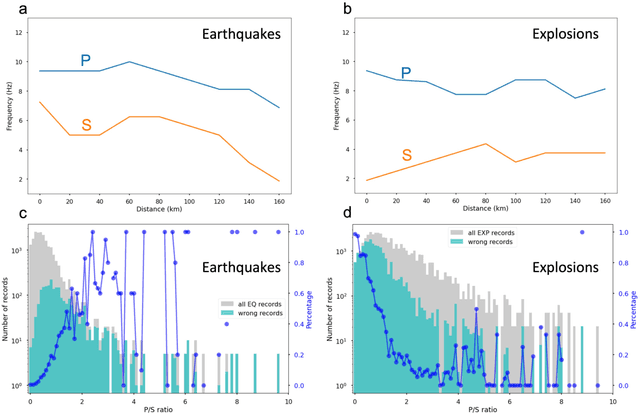
This paper combines the power of deep-learning with the generalizability of physics-based features, to present an advanced method for seismic discrimination between earthquakes and explosions. The proposed method contains two branches: a deep learning branch operating directly on seismic waveforms or spectrograms, and a second branch operating on physics-based parametric features. These features are high-frequency P/S amplitude ratios and the difference between local magnitude (ML) and coda duration magnitude (MC). The combination achieves better generalization performance when applied to new regions than models that are developed solely with deep learning. We also examined which parts of the waveform data dominate deep learning decisions (i.e., via Grad-CAM). Such visualization provides a window into the black-box nature of the machine-learning models and offers new insight into how the deep learning derived models use data to make the decisions.
Learning Physics through Images: An Application to Wind-Driven Spatial Patterns
Feb 03, 2022
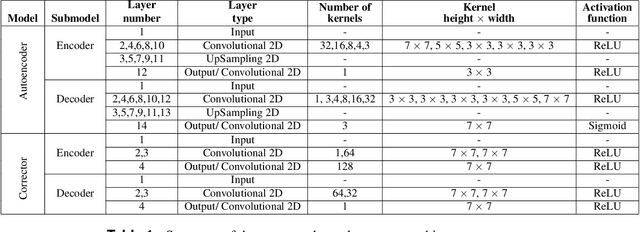
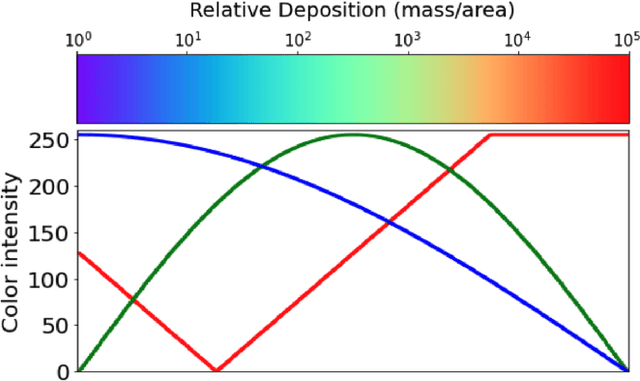
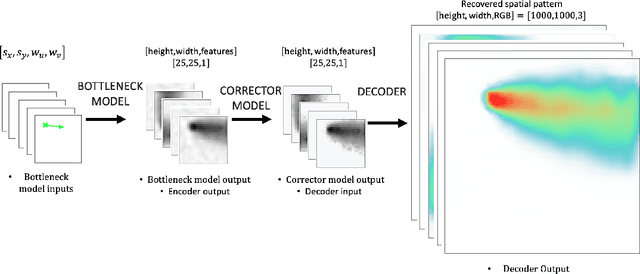
For centuries, scientists have observed nature to understand the laws that govern the physical world. The traditional process of turning observations into physical understanding is slow. Imperfect models are constructed and tested to explain relationships in data. Powerful new algorithms are available that can enable computers to learn physics by observing images and videos. Inspired by this idea, instead of training machine learning models using physical quantities, we trained them using images, that is, pixel information. For this work, and as a proof of concept, the physics of interest are wind-driven spatial patterns. Examples of these phenomena include features in Aeolian dunes and the deposition of volcanic ash, wildfire smoke, and air pollution plumes. We assume that the spatial patterns were collected by an imaging device that records the magnitude of the logarithm of deposition as a red, green, blue (RGB) color image with channels containing values ranging from 0 to 255. In this paper, we explore deep convolutional neural network-based autoencoders to exploit relationships in wind-driven spatial patterns, which commonly occur in geosciences, and reduce their dimensionality. Reducing the data dimension size with an encoder allows us to train regression models linking geographic and meteorological scalar input quantities to the encoded space. Once this is achieved, full predictive spatial patterns are reconstructed using the decoder. We demonstrate this approach on images of spatial deposition from a pollution source, where the encoder compresses the dimensionality to 0.02% of the original size and the full predictive model performance on test data achieves an accuracy of 92%.
Deep Convolutional Autoencoders as Generic Feature Extractors in Seismological Applications
Oct 22, 2021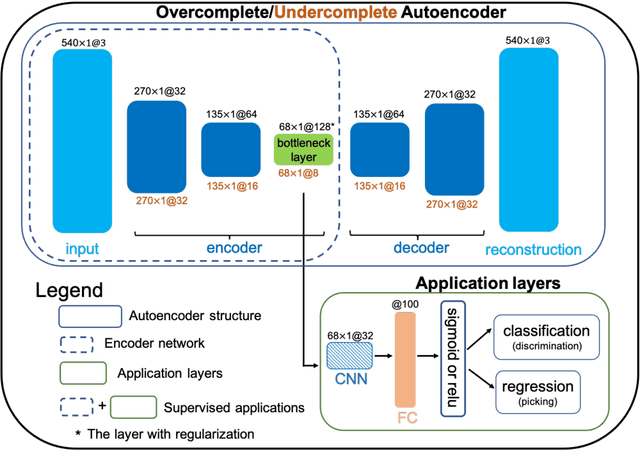
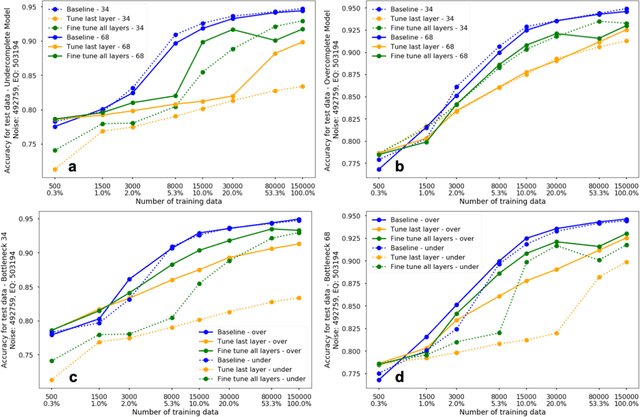
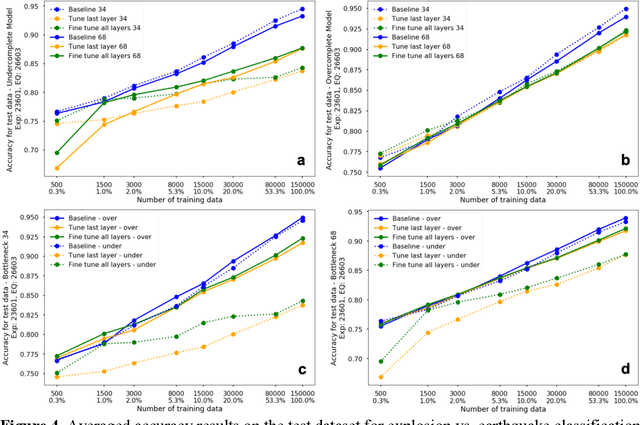
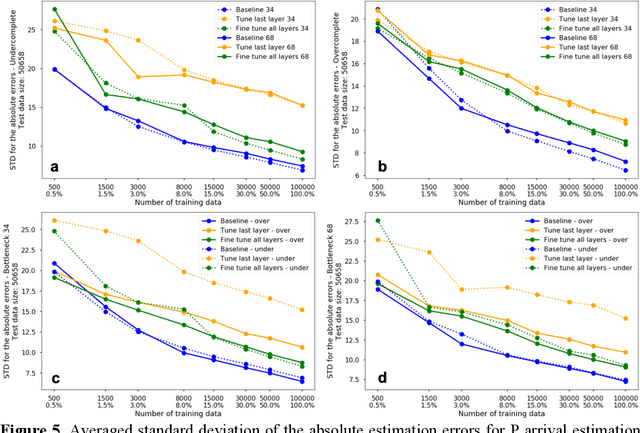
The idea of using a deep autoencoder to encode seismic waveform features and then use them in different seismological applications is appealing. In this paper, we designed tests to evaluate this idea of using autoencoders as feature extractors for different seismological applications, such as event discrimination (i.e., earthquake vs. noise waveforms, earthquake vs. explosion waveforms, and phase picking). These tests involve training an autoencoder, either undercomplete or overcomplete, on a large amount of earthquake waveforms, and then using the trained encoder as a feature extractor with subsequent application layers (either a fully connected layer, or a convolutional layer plus a fully connected layer) to make the decision. By comparing the performance of these newly designed models against the baseline models trained from scratch, we conclude that the autoencoder feature extractor approach may only perform well under certain conditions such as when the target problems require features to be similar to the autoencoder encoded features, when a relatively small amount of training data is available, and when certain model structures and training strategies are utilized. The model structure that works best in all these tests is an overcomplete autoencoder with a convolutional layer and a fully connected layer to make the estimation.
Detecting Damage Building Using Real-time Crowdsourced Images and Transfer Learning
Oct 12, 2021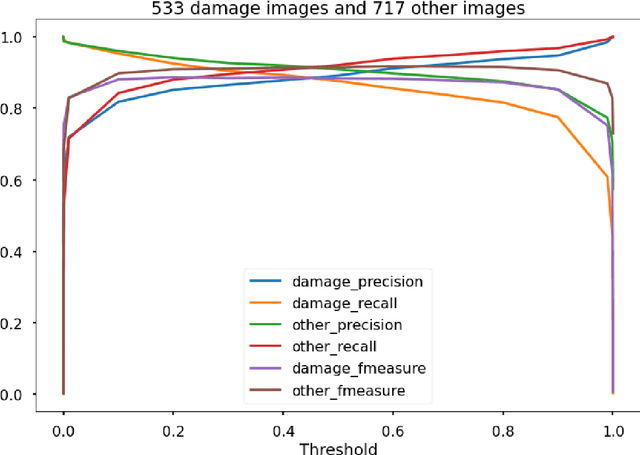


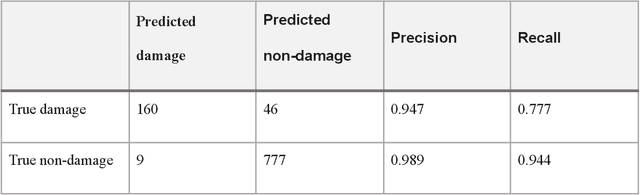
After significant earthquakes, we can see images posted on social media platforms by individuals and media agencies owing to the mass usage of smartphones these days. These images can be utilized to provide information about the shaking damage in the earthquake region both to the public and research community, and potentially to guide rescue work. This paper presents an automated way to extract the damaged building images after earthquakes from social media platforms such as Twitter and thus identify the particular user posts containing such images. Using transfer learning and ~6500 manually labelled images, we trained a deep learning model to recognize images with damaged buildings in the scene. The trained model achieved good performance when tested on newly acquired images of earthquakes at different locations and ran in near real-time on Twitter feed after the 2020 M7.0 earthquake in Turkey. Furthermore, to better understand how the model makes decisions, we also implemented the Grad-CAM method to visualize the important locations on the images that facilitate the decision.