 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Staged Deep Learning Approach to Spatial Refinement in 3D Temporal Atmospheric Transport
Dec 14, 2024High-resolution spatiotemporal simulations effectively capture the complexities of atmospheric plume dispersion in complex terrain. However, their high computational cost makes them impractical for applications requiring rapid responses or iterative processes, such as optimization, uncertainty quantification, or inverse modeling. To address this challenge, this work introduces the Dual-Stage Temporal Three-dimensional UNet Super-resolution (DST3D-UNet-SR) model, a highly efficient deep learning model for plume dispersion prediction. DST3D-UNet-SR is composed of two sequential modules: the temporal module (TM), which predicts the transient evolution of a plume in complex terrain from low-resolution temporal data, and the spatial refinement module (SRM), which subsequently enhances the spatial resolution of the TM predictions. We train DST3DUNet- SR using a comprehensive dataset derived from high-resolution large eddy simulations (LES) of plume transport. We propose the DST3D-UNet-SR model to significantly accelerate LES simulations of three-dimensional plume dispersion by three orders of magnitude. Additionally, the model demonstrates the ability to dynamically adapt to evolving conditions through the incorporation of new observational data, substantially improving prediction accuracy in high-concentration regions near the source. Keywords: Atmospheric sciences, Geosciences, Plume transport,3D temporal sequences, Artificial intelligence, CNN, LSTM, Autoencoder, Autoregressive model, U-Net, Super-resolution, Spatial Refinement.
Deep Convolutional Autoencoders as Generic Feature Extractors in Seismological Applications
Oct 22, 2021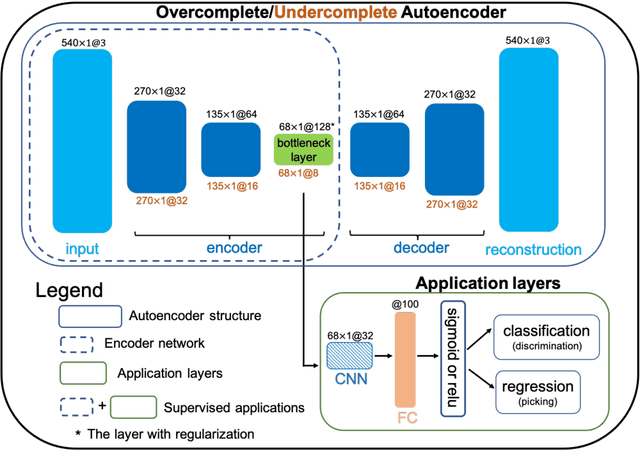
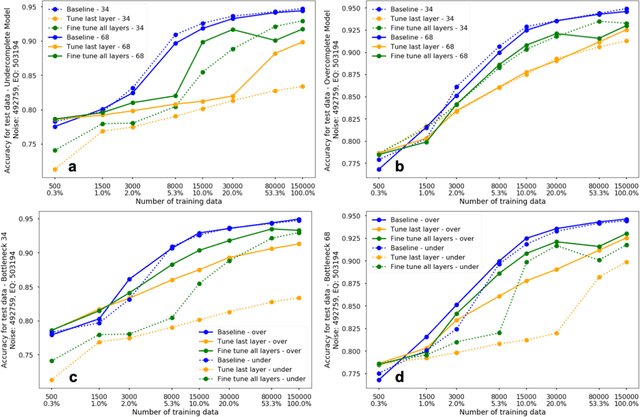
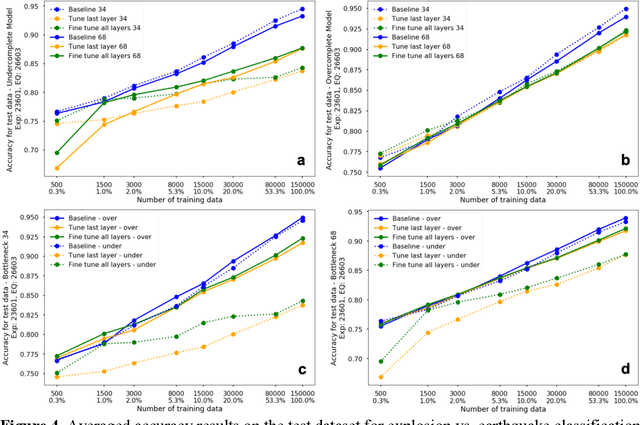
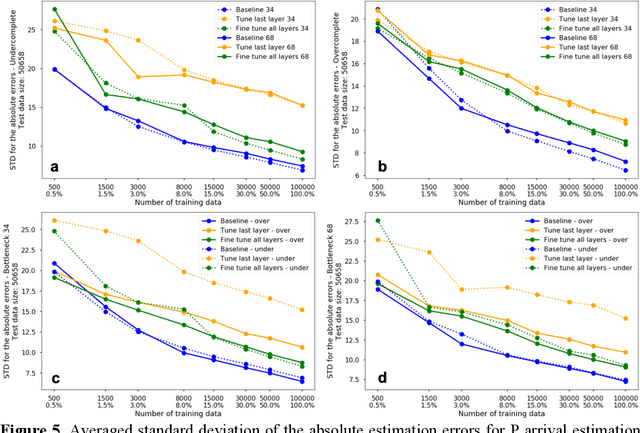
The idea of using a deep autoencoder to encode seismic waveform features and then use them in different seismological applications is appealing. In this paper, we designed tests to evaluate this idea of using autoencoders as feature extractors for different seismological applications, such as event discrimination (i.e., earthquake vs. noise waveforms, earthquake vs. explosion waveforms, and phase picking). These tests involve training an autoencoder, either undercomplete or overcomplete, on a large amount of earthquake waveforms, and then using the trained encoder as a feature extractor with subsequent application layers (either a fully connected layer, or a convolutional layer plus a fully connected layer) to make the decision. By comparing the performance of these newly designed models against the baseline models trained from scratch, we conclude that the autoencoder feature extractor approach may only perform well under certain conditions such as when the target problems require features to be similar to the autoencoder encoded features, when a relatively small amount of training data is available, and when certain model structures and training strategies are utilized. The model structure that works best in all these tests is an overcomplete autoencoder with a convolutional layer and a fully connected layer to make the estimation.