 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlend the Separated: Mixture of Synergistic Experts for Data-Scarcity Drug-Target Interaction Prediction
Mar 20, 2025Drug-target interaction prediction (DTI) is essential in various applications including drug discovery and clinical application. There are two perspectives of input data widely used in DTI prediction: Intrinsic data represents how drugs or targets are constructed, and extrinsic data represents how drugs or targets are related to other biological entities. However, any of the two perspectives of input data can be scarce for some drugs or targets, especially for those unpopular or newly discovered. Furthermore, ground-truth labels for specific interaction types can also be scarce. Therefore, we propose the first method to tackle DTI prediction under input data and/or label scarcity. To make our model functional when only one perspective of input data is available, we design two separate experts to process intrinsic and extrinsic data respectively and fuse them adaptively according to different samples. Furthermore, to make the two perspectives complement each other and remedy label scarcity, two experts synergize with each other in a mutually supervised way to exploit the enormous unlabeled data. Extensive experiments on 3 real-world datasets under different extents of input data scarcity and/or label scarcity demonstrate our model outperforms states of the art significantly and steadily, with a maximum improvement of 53.53%. We also test our model without any data scarcity and it still outperforms current methods.
Graph Fairness Learning under Distribution Shifts
Jan 30, 2024



Graph neural networks (GNNs) have achieved remarkable performance on graph-structured data. However, GNNs may inherit prejudice from the training data and make discriminatory predictions based on sensitive attributes, such as gender and race. Recently, there has been an increasing interest in ensuring fairness on GNNs, but all of them are under the assumption that the training and testing data are under the same distribution, i.e., training data and testing data are from the same graph. Will graph fairness performance decrease under distribution shifts? How does distribution shifts affect graph fairness learning? All these open questions are largely unexplored from a theoretical perspective. To answer these questions, we first theoretically identify the factors that determine bias on a graph. Subsequently, we explore the factors influencing fairness on testing graphs, with a noteworthy factor being the representation distances of certain groups between the training and testing graph. Motivated by our theoretical analysis, we propose our framework FatraGNN. Specifically, to guarantee fairness performance on unknown testing graphs, we propose a graph generator to produce numerous graphs with significant bias and under different distributions. Then we minimize the representation distances for each certain group between the training graph and generated graphs. This empowers our model to achieve high classification and fairness performance even on generated graphs with significant bias, thereby effectively handling unknown testing graphs. Experiments on real-world and semi-synthetic datasets demonstrate the effectiveness of our model in terms of both accuracy and fairness.
Uncovering the Structural Fairness in Graph Contrastive Learning
Oct 06, 2022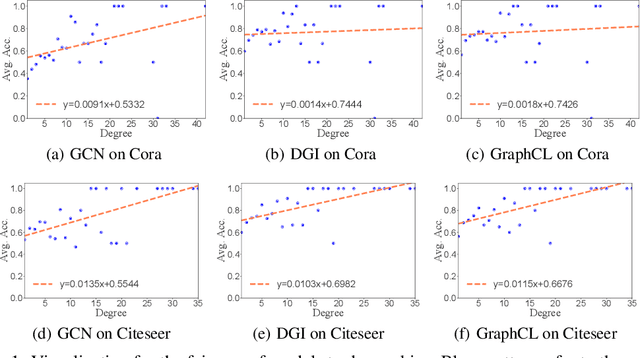
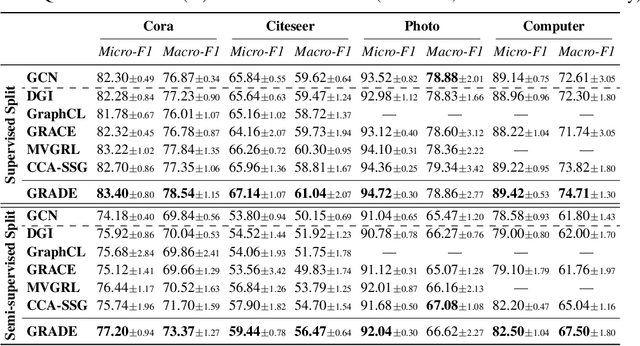
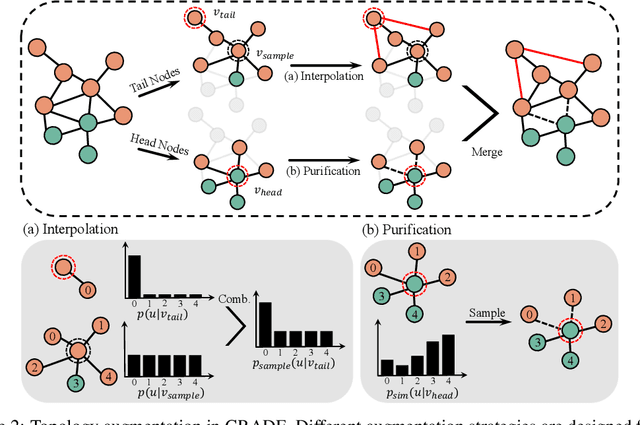
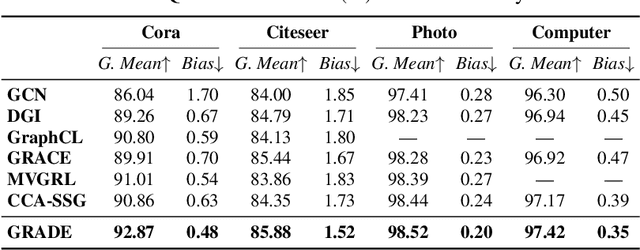
Recent studies show that graph convolutional network (GCN) often performs worse for low-degree nodes, exhibiting the so-called structural unfairness for graphs with long-tailed degree distributions prevalent in the real world. Graph contrastive learning (GCL), which marries the power of GCN and contrastive learning, has emerged as a promising self-supervised approach for learning node representations. How does GCL behave in terms of structural fairness? Surprisingly, we find that representations obtained by GCL methods are already fairer to degree bias than those learned by GCN. We theoretically show that this fairness stems from intra-community concentration and inter-community scatter properties of GCL, resulting in a much clear community structure to drive low-degree nodes away from the community boundary. Based on our theoretical analysis, we further devise a novel graph augmentation method, called GRAph contrastive learning for DEgree bias (GRADE), which applies different strategies to low- and high-degree nodes. Extensive experiments on various benchmarks and evaluation protocols validate the effectiveness of the proposed method.
Combining Deep Learning with Physics Based Features in Explosion-Earthquake Discrimination
Mar 12, 2022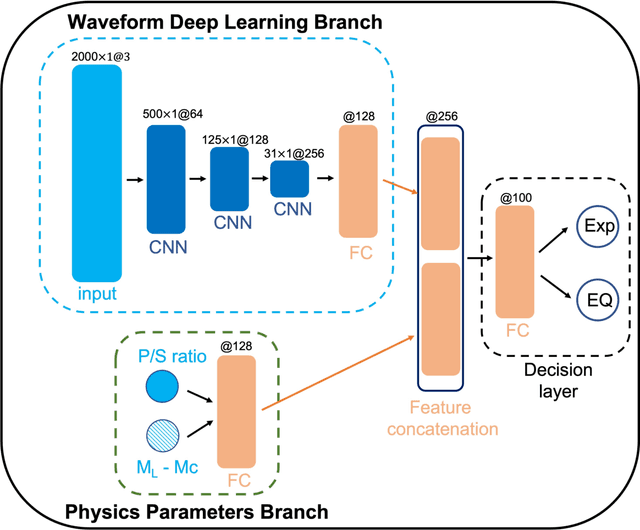
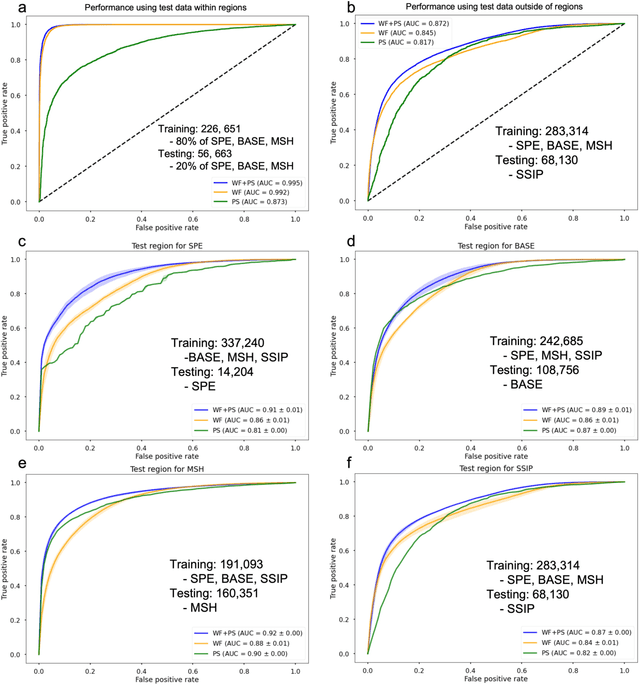
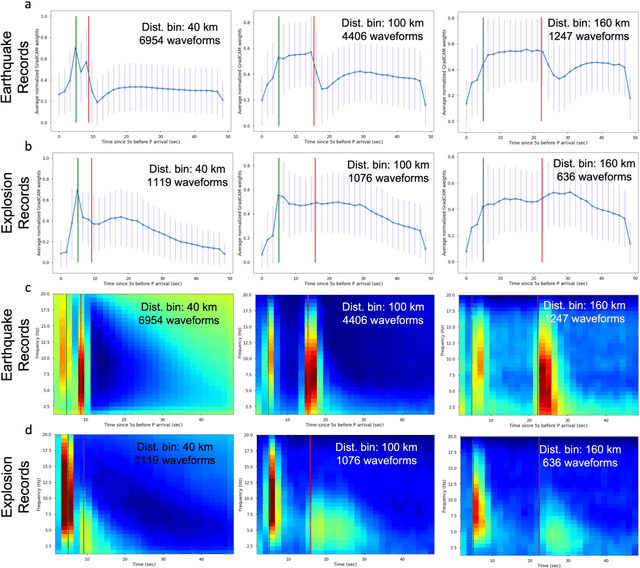
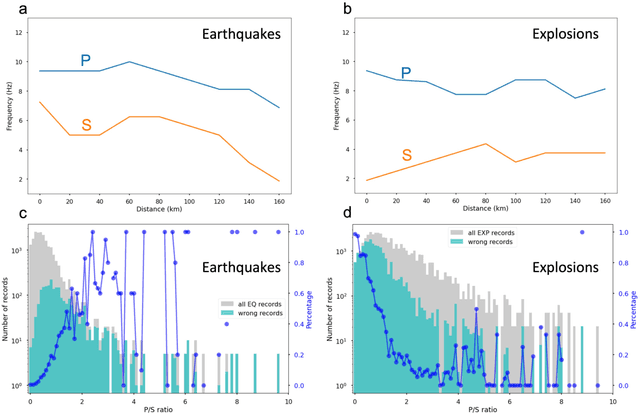
This paper combines the power of deep-learning with the generalizability of physics-based features, to present an advanced method for seismic discrimination between earthquakes and explosions. The proposed method contains two branches: a deep learning branch operating directly on seismic waveforms or spectrograms, and a second branch operating on physics-based parametric features. These features are high-frequency P/S amplitude ratios and the difference between local magnitude (ML) and coda duration magnitude (MC). The combination achieves better generalization performance when applied to new regions than models that are developed solely with deep learning. We also examined which parts of the waveform data dominate deep learning decisions (i.e., via Grad-CAM). Such visualization provides a window into the black-box nature of the machine-learning models and offers new insight into how the deep learning derived models use data to make the decisions.
BOND: BERT-Assisted Open-Domain Named Entity Recognition with Distant Supervision
Jun 28, 2020
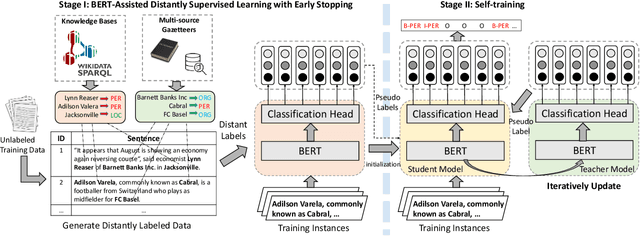
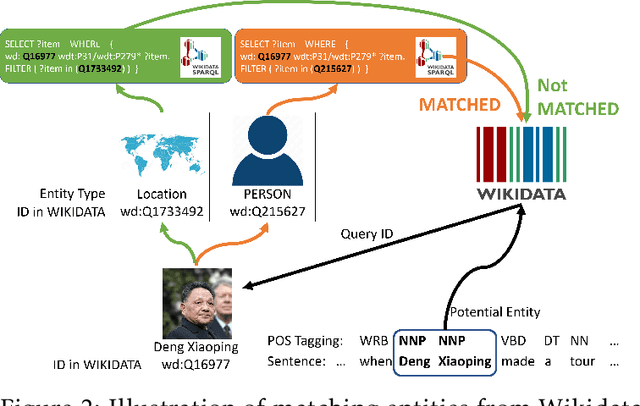

We study the open-domain named entity recognition (NER) problem under distant supervision. The distant supervision, though does not require large amounts of manual annotations, yields highly incomplete and noisy distant labels via external knowledge bases. To address this challenge, we propose a new computational framework -- BOND, which leverages the power of pre-trained language models (e.g., BERT and RoBERTa) to improve the prediction performance of NER models. Specifically, we propose a two-stage training algorithm: In the first stage, we adapt the pre-trained language model to the NER tasks using the distant labels, which can significantly improve the recall and precision; In the second stage, we drop the distant labels, and propose a self-training approach to further improve the model performance. Thorough experiments on 5 benchmark datasets demonstrate the superiority of BOND over existing distantly supervised NER methods. The code and distantly labeled data have been released in https://github.com/cliang1453/BOND.
Multi-Component Graph Convolutional Collaborative Filtering
Nov 25, 2019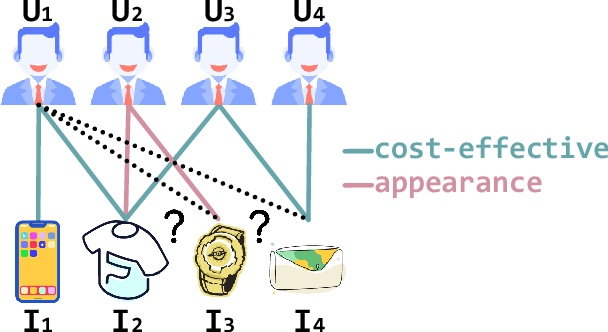

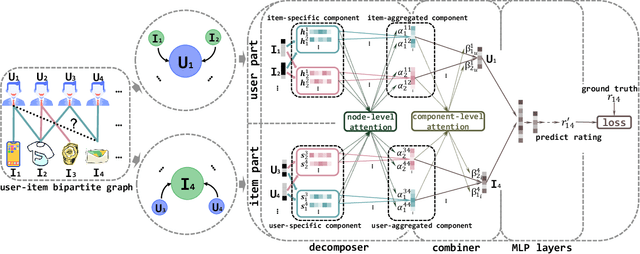
The interactions of users and items in recommender system could be naturally modeled as a user-item bipartite graph. In recent years, we have witnessed an emerging research effort in exploring user-item graph for collaborative filtering methods. Nevertheless, the formation of user-item interactions typically arises from highly complex latent purchasing motivations, such as high cost performance or eye-catching appearance, which are indistinguishably represented by the edges. The existing approaches still remain the differences between various purchasing motivations unexplored, rendering the inability to capture fine-grained user preference. Therefore, in this paper we propose a novel Multi-Component graph convolutional Collaborative Filtering (MCCF) approach to distinguish the latent purchasing motivations underneath the observed explicit user-item interactions. Specifically, there are two elaborately designed modules, decomposer and combiner, inside MCCF. The former first decomposes the edges in user-item graph to identify the latent components that may cause the purchasing relationship; the latter then recombines these latent components automatically to obtain unified embeddings for prediction. Furthermore, the sparse regularizer and weighted random sample strategy are utilized to alleviate the overfitting problem and accelerate the optimization. Empirical results on three real datasets and a synthetic dataset not only show the significant performance gains of MCCF, but also well demonstrate the necessity of considering multiple components.
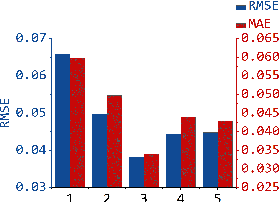
A Fast Proximal Point Method for Computing Wasserstein Distance
Jun 14, 2018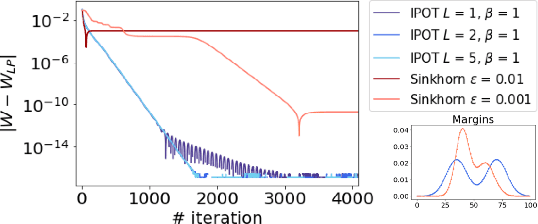
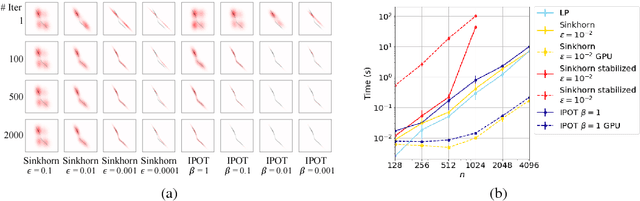
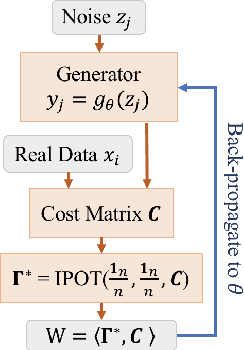

Wasserstein distance plays increasingly important roles in machine learning, stochastic programming and image processing. Major efforts have been under way to address its high computational complexity, some leading to approximate or regularized variations such as Sinkhorn distance. However, as we will demonstrate, regularized variations with large regularization parameter will degradate the performance in several important machine learning applications, and small regularization parameter will fail due to numerical stability issues with existing algorithms. We address this challenge by developing an Inexact Proximal point method for Optimal Transport (IPOT) with the proximal operator approximately evaluated at each iteration using projections to the probability simplex. We prove the algorithm has linear convergence rate. We also apply IPOT to learning generative models, and generalize the idea of IPOT to a new method for computing Wasserstein barycenter.