 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfinity-MM: Scaling Multimodal Performance with Large-Scale and High-Quality Instruction Data
Oct 24, 2024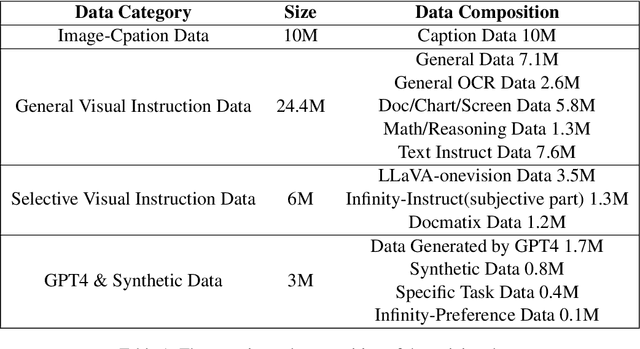
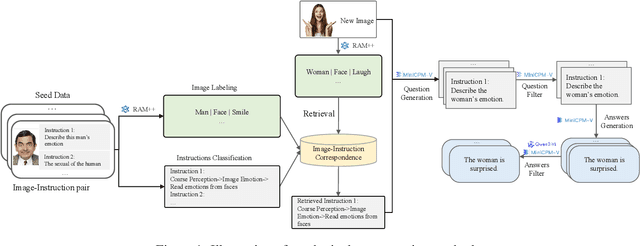
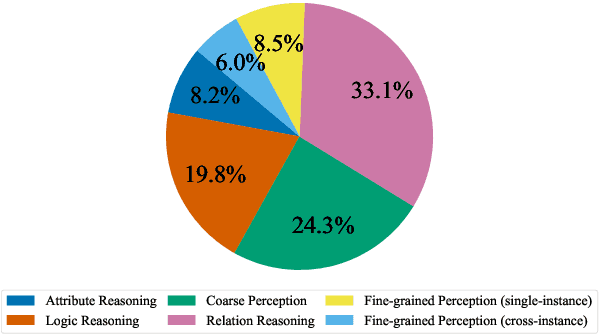
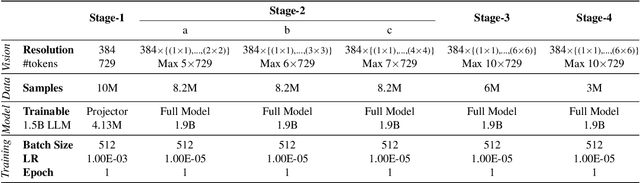
Vision-Language Models (VLMs) have recently made significant progress, but the limited scale and quality of open-source instruction data hinder their performance compared to closed-source models. In this work, we address this limitation by introducing Infinity-MM, a large-scale multimodal instruction dataset with 40 million samples, enhanced through rigorous quality filtering and deduplication. We also propose a synthetic instruction generation method based on open-source VLMs, using detailed image annotations and diverse question generation. Using this data, we trained a 2-billion-parameter VLM, Aquila-VL-2B, achieving state-of-the-art (SOTA) performance for models of similar scale. This demonstrates that expanding instruction data and generating synthetic data can significantly improve the performance of open-source models.
GraphTeam: Facilitating Large Language Model-based Graph Analysis via Multi-Agent Collaboration
Oct 23, 2024



Graphs are widely used for modeling relational data in real-world scenarios, such as social networks and urban computing. Existing LLM-based graph analysis approaches either integrate graph neural networks (GNNs) for specific machine learning tasks, limiting their transferability, or rely solely on LLMs' internal reasoning ability, resulting in suboptimal performance. To address these limitations, we take advantage of recent advances in LLM-based agents, which have shown capabilities of utilizing external knowledge or tools for problem solving. By simulating human problem-solving strategies such as analogy and collaboration, we propose a multi-agent system based on LLMs named GraphTeam, for graph analysis. GraphTeam consists of five LLM-based agents from three modules, and the agents with different specialities can collaborate with each other to address complex problems. Specifically, (1) input-output normalization module: the question agent extracts and refines four key arguments from the original question, facilitating the problem understanding, and the answer agent organizes the results to meet the output requirement; (2) external knowledge retrieval module: we first build a knowledge base consisting of relevant documentation and experience information, and then the search agent retrieves the most relevant entries for each question. (3) problem-solving module: given the retrieved information from search agent, the coding agent uses established algorithms via programming to generate solutions, and in case the coding agent does not work, the reasoning agent will directly compute the results without programming. Extensive experiments on six graph analysis benchmarks demonstrate that GraphTeam achieves state-of-the-art performance with an average 25.85% improvement over the best baseline in terms of accuracy. The code and data are available at https://github.com/BUPT-GAMMA/GraphTeam.
Graph Fairness Learning under Distribution Shifts
Jan 30, 2024



Graph neural networks (GNNs) have achieved remarkable performance on graph-structured data. However, GNNs may inherit prejudice from the training data and make discriminatory predictions based on sensitive attributes, such as gender and race. Recently, there has been an increasing interest in ensuring fairness on GNNs, but all of them are under the assumption that the training and testing data are under the same distribution, i.e., training data and testing data are from the same graph. Will graph fairness performance decrease under distribution shifts? How does distribution shifts affect graph fairness learning? All these open questions are largely unexplored from a theoretical perspective. To answer these questions, we first theoretically identify the factors that determine bias on a graph. Subsequently, we explore the factors influencing fairness on testing graphs, with a noteworthy factor being the representation distances of certain groups between the training and testing graph. Motivated by our theoretical analysis, we propose our framework FatraGNN. Specifically, to guarantee fairness performance on unknown testing graphs, we propose a graph generator to produce numerous graphs with significant bias and under different distributions. Then we minimize the representation distances for each certain group between the training graph and generated graphs. This empowers our model to achieve high classification and fairness performance even on generated graphs with significant bias, thereby effectively handling unknown testing graphs. Experiments on real-world and semi-synthetic datasets demonstrate the effectiveness of our model in terms of both accuracy and fairness.
Seismogram Transformer: A generic deep learning backbone network for multiple earthquake monitoring tasks
Oct 02, 2023



Seismic records, known as seismograms, are crucial records of ground motion resulting from seismic events, constituting the backbone of earthquake research and monitoring. The latest advancements in deep learning have significantly facilitated various seismic signal processing tasks. This paper introduces a novel backbone neural network model designed for various seismic monitoring tasks, named Seismogram Transformer (SeisT). Thanks to its efficient network architecture, SeisT matches or even outperforms the state-of-the-art models in earthquake detection, seismic phase picking, first-motion polarity classification, magnitude estimation, and azimuth estimation tasks, particularly in terms of out-of-distribution generalization performance. SeisT consists of multiple network layers composed of different foundational blocks, which help the model understand multi-level feature representations of seismograms from low-level to high-level complex features, effectively extracting features such as frequency, phase, and time-frequency relationships from input seismograms. Three different-sized models were customized based on these diverse foundational modules. Through extensive experiments and performance evaluations, this study showcases the capabilities and potential of SeisT in advancing seismic signal processing and earthquake research.