 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenefits of Overparameterized Convolutional Residual Networks: Function Approximation under Smoothness Constraint
Jun 09, 2022
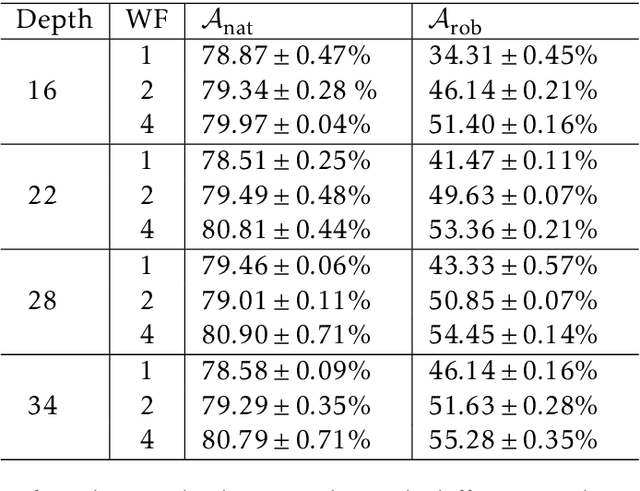
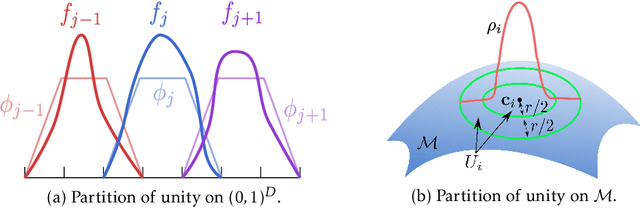
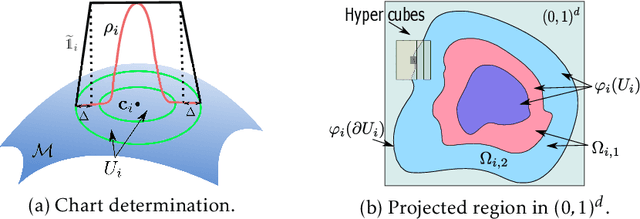
Overparameterized neural networks enjoy great representation power on complex data, and more importantly yield sufficiently smooth output, which is crucial to their generalization and robustness. Most existing function approximation theories suggest that with sufficiently many parameters, neural networks can well approximate certain classes of functions in terms of the function value. The neural network themselves, however, can be highly nonsmooth. To bridge this gap, we take convolutional residual networks (ConvResNets) as an example, and prove that large ConvResNets can not only approximate a target function in terms of function value, but also exhibit sufficient first-order smoothness. Moreover, we extend our theory to approximating functions supported on a low-dimensional manifold. Our theory partially justifies the benefits of using deep and wide networks in practice. Numerical experiments on adversarial robust image classification are provided to support our theory.
Deep Learning Assisted End-to-End Synthesis of mm-Wave Passive Networks with 3D EM Structures: A Study on A Transformer-Based Matching Network
Jan 06, 2022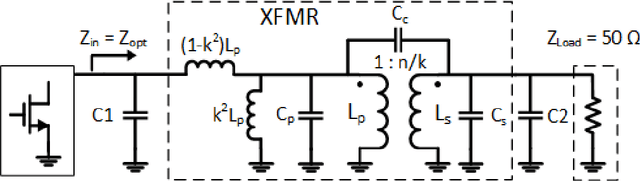


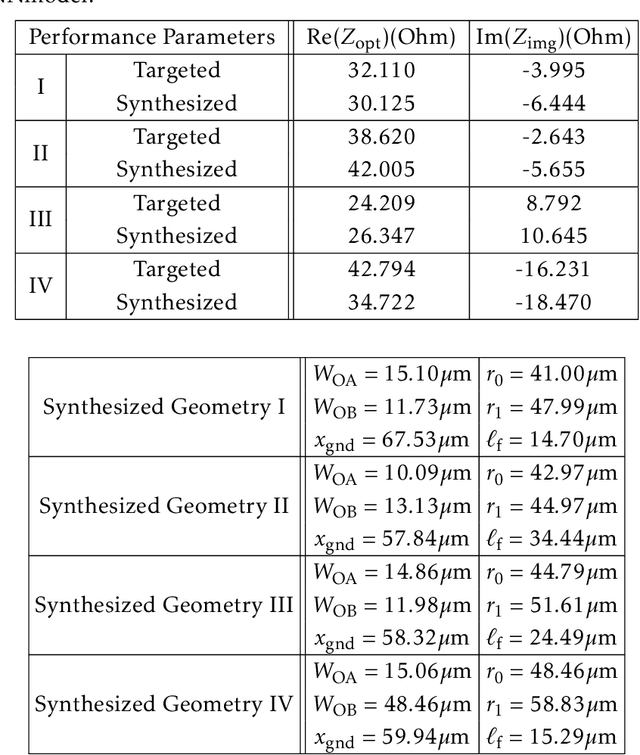
This paper presents a deep learning assisted synthesis approach for direct end-to-end generation of RF/mm-wave passive matching network with 3D EM structures. Different from prior approaches that synthesize EM structures from target circuit component values and target topologies, our proposed approach achieves the direct synthesis of the passive network given the network topology from desired performance values as input. We showcase the proposed synthesis Neural Network (NN) model on an on-chip 1:1 transformer-based impedance matching network. By leveraging parameter sharing, the synthesis NN model successfully extracts relevant features from the input impedance and load capacitors, and predict the transformer 3D EM geometry in a 45nm SOI process that will match the standard 50$\Omega$ load to the target input impedance while absorbing the two loading capacitors. As a proof-of-concept, several example transformer geometries were synthesized, and verified in Ansys HFSS to provide the desired input impedance.
Self-Training with Differentiable Teacher
Sep 15, 2021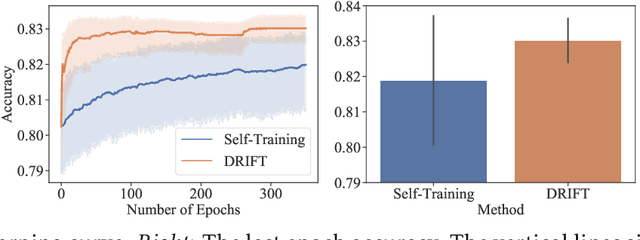


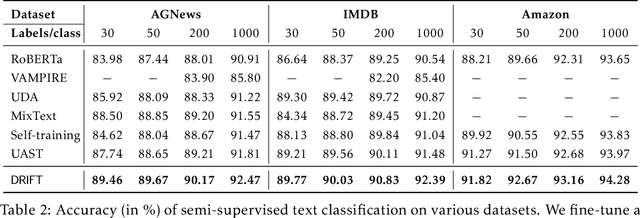
Self-training achieves enormous success in various semi-supervised and weakly-supervised learning tasks. The method can be interpreted as a teacher-student framework, where the teacher generates pseudo-labels, and the student makes predictions. The two models are updated alternatingly. However, such a straightforward alternating update rule leads to training instability. This is because a small change in the teacher may result in a significant change in the student. To address this issue, we propose {\ours}, short for differentiable self-training, that treats teacher-student as a Stackelberg game. In this game, a leader is always in a more advantageous position than a follower. In self-training, the student contributes to the prediction performance, and the teacher controls the training process by generating pseudo-labels. Therefore, we treat the student as the leader and the teacher as the follower. The leader procures its advantage by acknowledging the follower's strategy, which involves differentiable pseudo-labels and differentiable sample weights. Consequently, the leader-follower interaction can be effectively captured via Stackelberg gradient, obtained by differentiating the follower's strategy. Experimental results on semi- and weakly-supervised classification and named entity recognition tasks show that our model outperforms existing approaches by large margins.
COUnty aggRegation mixup AuGmEntation (COURAGE) COVID-19 Prediction
May 03, 2021
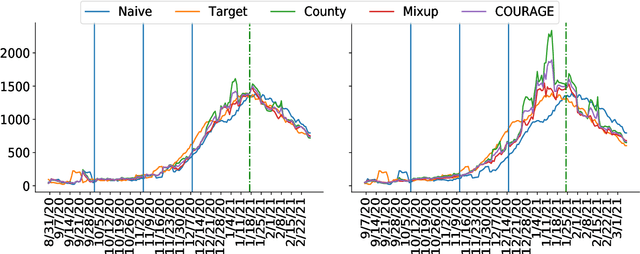


The global spread of COVID-19, the disease caused by the novel coronavirus SARS-CoV-2, has cast a significant threat to mankind. As the COVID-19 situation continues to evolve, predicting localized disease severity is crucial for advanced resource allocation. This paper proposes a method named COURAGE (COUnty aggRegation mixup AuGmEntation) to generate a short-term prediction of 2-week-ahead COVID-19 related deaths for each county in the United States, leveraging modern deep learning techniques. Specifically, our method adopts a self-attention model from Natural Language Processing, known as the transformer model, to capture both short-term and long-term dependencies within the time series while enjoying computational efficiency. Our model fully utilizes publicly available information of COVID-19 related confirmed cases, deaths, community mobility trends and demographic information, and can produce state-level prediction as an aggregation of the corresponding county-level predictions. Our numerical experiments demonstrate that our model achieves the state-of-the-art performance among the publicly available benchmark models.
Residual Network Based Direct Synthesis of EM Structures: A Study on One-to-One Transformers
Aug 25, 2020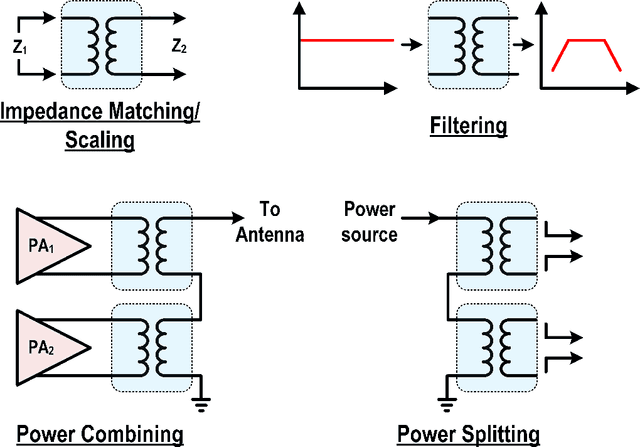
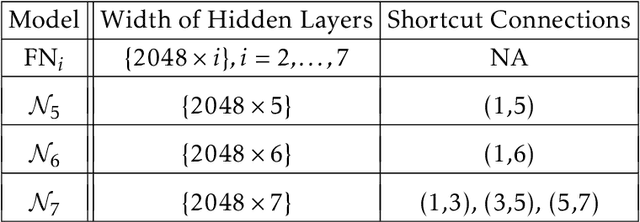
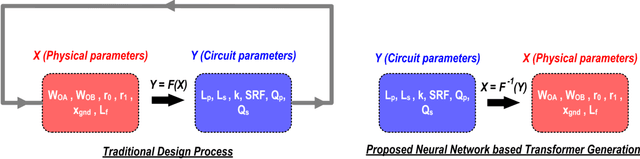
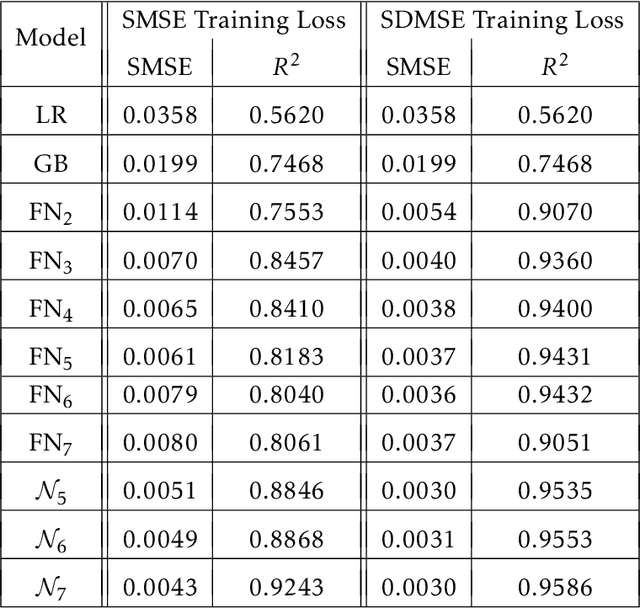
We propose using machine learning models for the direct synthesis of on-chip electromagnetic (EM) passive structures to enable rapid or even automated designs and optimizations of RF/mm-Wave circuits. As a proof of concept, we demonstrate the direct synthesis of a 1:1 transformer on a 45nm SOI process using our proposed neural network model. Using pre-existing transformer s-parameter files and their geometric design training samples, the model predicts target geometric designs.
BOND: BERT-Assisted Open-Domain Named Entity Recognition with Distant Supervision
Jun 28, 2020
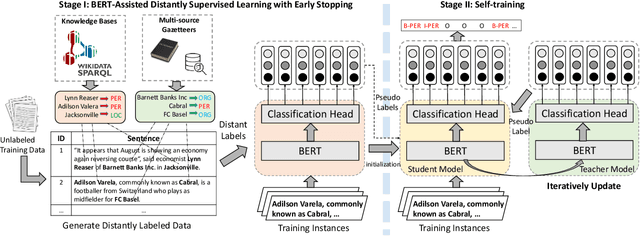
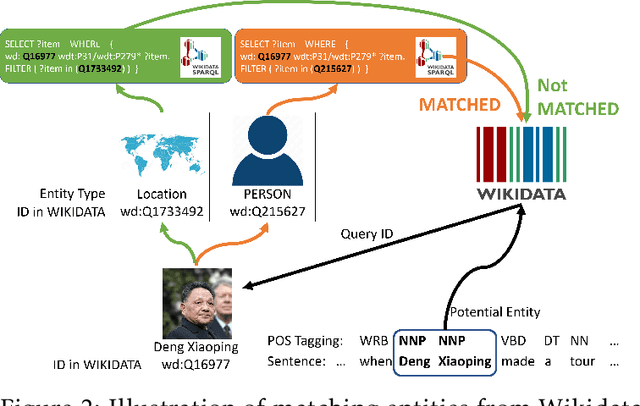

We study the open-domain named entity recognition (NER) problem under distant supervision. The distant supervision, though does not require large amounts of manual annotations, yields highly incomplete and noisy distant labels via external knowledge bases. To address this challenge, we propose a new computational framework -- BOND, which leverages the power of pre-trained language models (e.g., BERT and RoBERTa) to improve the prediction performance of NER models. Specifically, we propose a two-stage training algorithm: In the first stage, we adapt the pre-trained language model to the NER tasks using the distant labels, which can significantly improve the recall and precision; In the second stage, we drop the distant labels, and propose a self-training approach to further improve the model performance. Thorough experiments on 5 benchmark datasets demonstrate the superiority of BOND over existing distantly supervised NER methods. The code and distantly labeled data have been released in https://github.com/cliang1453/BOND.