 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperMLP: An Integrated Perspective for Sequence Modeling
Feb 13, 2026Self-attention is often viewed as probabilistic query-key lookup, motivating designs that preserve normalized attention scores and fixed positional semantics. We advocate a simpler and more unified perspective: an autoregressive attention head can be viewed as a dynamic two-layer MLP whose weights are instantiated from the context history. From this view, attention scores form an ever-growing hidden representation, and standard MLP activations such as ReLU or GLU naturally implement input-conditioned selection over a context-dependent memory pool rather than a probability distribution. Based on this formulation, we introduce HyperMLP and HyperGLU, which learn dynamic mixing in both feature space and sequence space, using a reverse-offset (lag) layout to align temporal mixing with autoregressive semantics. We provide theoretical characterizations of the expressivity and implications of this structure, and empirically show that HyperMLP/HyperGLU consistently outperform strong softmax-attention baselines under matched parameter budgets.
NeuroWeaver: An Autonomous Evolutionary Agent for Exploring the Programmatic Space of EEG Analysis Pipelines
Feb 13, 2026Although foundation models have demonstrated remarkable success in general domains, the application of these models to electroencephalography (EEG) analysis is constrained by substantial data requirements and high parameterization. These factors incur prohibitive computational costs, thereby impeding deployment in resource-constrained clinical environments. Conversely, general-purpose automated machine learning frameworks are often ill-suited for this domain, as exploration within an unbounded programmatic space fails to incorporate essential neurophysiological priors and frequently yields solutions that lack scientific plausibility. To address these limitations, we propose NeuroWeaver, a unified autonomous evolutionary agent designed to generalize across diverse EEG datasets and tasks by reformulating pipeline engineering as a discrete constrained optimization problem. Specifically, we employ a Domain-Informed Subspace Initialization to confine the search to neuroscientifically plausible manifolds, coupled with a Multi-Objective Evolutionary Optimization that dynamically balances performance, novelty, and efficiency via self-reflective refinement. Empirical evaluations across five heterogeneous benchmarks demonstrate that NeuroWeaver synthesizes lightweight solutions that consistently outperform state-of-the-art task-specific methods and achieve performance comparable to large-scale foundation models, despite utilizing significantly fewer parameters.
StretchTime: Adaptive Time Series Forecasting via Symplectic Attention
Feb 09, 2026Transformer architectures have established strong baselines in time series forecasting, yet they typically rely on positional encodings that assume uniform, index-based temporal progression. However, real-world systems, from shifting financial cycles to elastic biological rhythms, frequently exhibit "time-warped" dynamics where the effective flow of time decouples from the sampling index. In this work, we first formalize this misalignment and prove that rotary position embedding (RoPE) is mathematically incapable of representing non-affine temporal warping. To address this, we propose Symplectic Positional Embeddings (SyPE), a learnable encoding framework derived from Hamiltonian mechanics. SyPE strictly generalizes RoPE by extending the rotation group $\mathrm{SO}(2)$ to the symplectic group $\mathrm{Sp}(2,\mathbb{R})$, modulated by a novel input-dependent adaptive warp module. By allowing the attention mechanism to adaptively dilate or contract temporal coordinates end-to-end, our approach captures locally varying periodicities without requiring pre-defined warping functions. We implement this mechanism in StretchTime, a multivariate forecasting architecture that achieves state-of-the-art performance on standard benchmarks, demonstrating superior robustness on datasets exhibiting non-stationary temporal dynamics.
Free Energy Mixer
Feb 06, 2026Standard attention stores keys/values losslessly but reads them via a per-head convex average, blocking channel-wise selection. We propose the Free Energy Mixer (FEM): a free-energy (log-sum-exp) read that applies a value-driven, per-channel log-linear tilt to a fast prior (e.g., from queries/keys in standard attention) over indices. Unlike methods that attempt to improve and enrich the $(q,k)$ scoring distribution, FEM treats it as a prior and yields a value-aware posterior read at unchanged complexity, smoothly moving from averaging to per-channel selection as the learnable inverse temperature increases, while still preserving parallelism and the original asymptotic complexity ($O(T^2)$ for softmax; $O(T)$ for linearizable variants). We instantiate a two-level gated FEM that is plug-and-play with standard and linear attention, linear RNNs and SSMs. It consistently outperforms strong baselines on NLP, vision, and time-series at matched parameter budgets.
* Camera-ready version. Accepted at ICLR 2026
ZeroS: Zero-Sum Linear Attention for Efficient Transformers
Feb 05, 2026Linear attention methods offer Transformers $O(N)$ complexity but typically underperform standard softmax attention. We identify two fundamental limitations affecting these approaches: the restriction to convex combinations that only permits additive information blending, and uniform accumulated weight bias that dilutes attention in long contexts. We propose Zero-Sum Linear Attention (ZeroS), which addresses these limitations by removing the constant zero-order term $1/t$ and reweighting the remaining zero-sum softmax residuals. This modification creates mathematically stable weights, enabling both positive and negative values and allowing a single attention layer to perform contrastive operations. While maintaining $O(N)$ complexity, ZeroS theoretically expands the set of representable functions compared to convex combinations. Empirically, it matches or exceeds standard softmax attention across various sequence modeling benchmarks.
* Camera-ready version. Accepted at NeurIPS 2025
CAPS: Unifying Attention, Recurrence, and Alignment in Transformer-based Time Series Forecasting
Feb 02, 2026This paper presents $\textbf{CAPS}$ (Clock-weighted Aggregation with Prefix-products and Softmax), a structured attention mechanism for time series forecasting that decouples three distinct temporal structures: global trends, local shocks, and seasonal patterns. Standard softmax attention entangles these through global normalization, while recent recurrent models sacrifice long-term, order-independent selection for order-dependent causal structure. CAPS combines SO(2) rotations for phase alignment with three additive gating paths -- Riemann softmax, prefix-product gates, and a Clock baseline -- within a single attention layer. We introduce the Clock mechanism, a learned temporal weighting that modulates these paths through a shared notion of temporal importance. Experiments on long- and short-term forecasting benchmarks surpass vanilla softmax and linear attention mechanisms and demonstrate competitive performance against seven strong baselines with linear complexity. Our code implementation is available at https://github.com/vireshpati/CAPS-Attention.
HyCoRA: Hyper-Contrastive Role-Adaptive Learning for Role-Playing
Nov 11, 2025Multi-character role-playing aims to equip models with the capability to simulate diverse roles. Existing methods either use one shared parameterized module across all roles or assign a separate parameterized module to each role. However, the role-shared module may ignore distinct traits of each role, weakening personality learning, while the role-specific module may overlook shared traits across multiple roles, hindering commonality modeling. In this paper, we propose a novel HyCoRA: Hyper-Contrastive Role-Adaptive learning framework, which efficiently improves multi-character role-playing ability by balancing the learning of distinct and shared traits. Specifically, we propose a Hyper-Half Low-Rank Adaptation structure, where one half is a role-specific module generated by a lightweight hyper-network, and the other half is a trainable role-shared module. The role-specific module is devised to represent distinct persona signatures, while the role-shared module serves to capture common traits. Moreover, to better reflect distinct personalities across different roles, we design a hyper-contrastive learning mechanism to help the hyper-network distinguish their unique characteristics. Extensive experimental results on both English and Chinese available benchmarks demonstrate the superiority of our framework. Further GPT-4 evaluations and visual analyses also verify the capability of HyCoRA to capture role characteristics.
Are Statistical Methods Obsolete in the Era of Deep Learning?
May 27, 2025In the era of AI, neural networks have become increasingly popular for modeling, inference, and prediction, largely due to their potential for universal approximation. With the proliferation of such deep learning models, a question arises: are leaner statistical methods still relevant? To shed insight on this question, we employ the mechanistic nonlinear ordinary differential equation (ODE) inverse problem as a testbed, using physics-informed neural network (PINN) as a representative of the deep learning paradigm and manifold-constrained Gaussian process inference (MAGI) as a representative of statistically principled methods. Through case studies involving the SEIR model from epidemiology and the Lorenz model from chaotic dynamics, we demonstrate that statistical methods are far from obsolete, especially when working with sparse and noisy observations. On tasks such as parameter inference and trajectory reconstruction, statistically principled methods consistently achieve lower bias and variance, while using far fewer parameters and requiring less hyperparameter tuning. Statistical methods can also decisively outperform deep learning models on out-of-sample future prediction, where the absence of relevant data often leads overparameterized models astray. Additionally, we find that statistically principled approaches are more robust to accumulation of numerical imprecision and can represent the underlying system more faithful to the true governing ODEs.
Physics-Informed Inference Time Scaling via Simulation-Calibrated Scientific Machine Learning
Apr 22, 2025High-dimensional partial differential equations (PDEs) pose significant computational challenges across fields ranging from quantum chemistry to economics and finance. Although scientific machine learning (SciML) techniques offer approximate solutions, they often suffer from bias and neglect crucial physical insights. Inspired by inference-time scaling strategies in language models, we propose Simulation-Calibrated Scientific Machine Learning (SCaSML), a physics-informed framework that dynamically refines and debiases the SCiML predictions during inference by enforcing the physical laws. SCaSML leverages derived new physical laws that quantifies systematic errors and employs Monte Carlo solvers based on the Feynman-Kac and Elworthy-Bismut-Li formulas to dynamically correct the prediction. Both numerical and theoretical analysis confirms enhanced convergence rates via compute-optimal inference methods. Our numerical experiments demonstrate that SCaSML reduces errors by 20-50% compared to the base surrogate model, establishing it as the first algorithm to refine approximated solutions to high-dimensional PDE during inference. Code of SCaSML is available at https://github.com/Francis-Fan-create/SCaSML.
Linear Transformers as VAR Models: Aligning Autoregressive Attention Mechanisms with Autoregressive Forecasting
Feb 11, 2025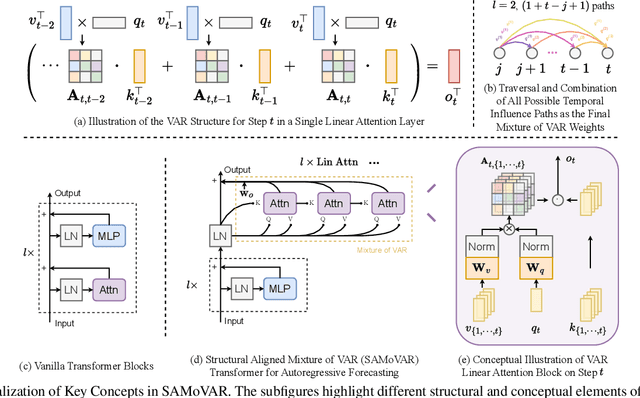
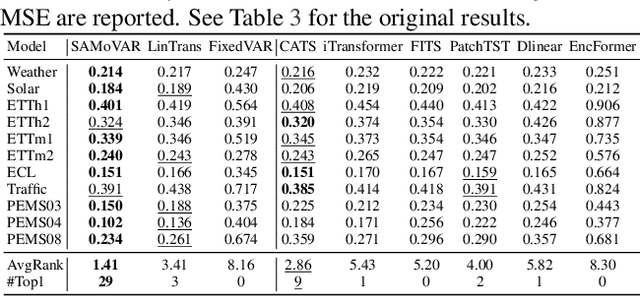
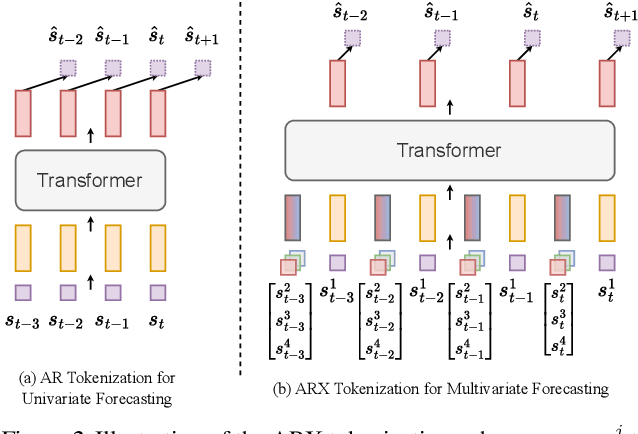
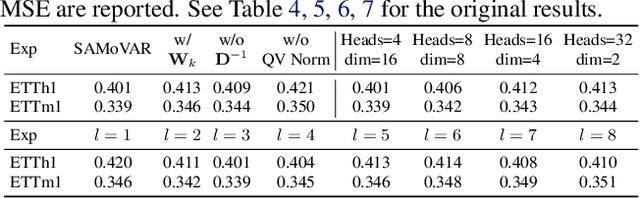
Autoregressive attention-based time series forecasting (TSF) has drawn increasing interest, with mechanisms like linear attention sometimes outperforming vanilla attention. However, deeper Transformer architectures frequently misalign with autoregressive objectives, obscuring the underlying VAR structure embedded within linear attention and hindering their ability to capture the data generative processes in TSF. In this work, we first show that a single linear attention layer can be interpreted as a dynamic vector autoregressive (VAR) structure. We then explain that existing multi-layer Transformers have structural mismatches with the autoregressive forecasting objective, which impair interpretability and generalization ability. To address this, we show that by rearranging the MLP, attention, and input-output flow, multi-layer linear attention can also be aligned as a VAR model. Then, we propose Structural Aligned Mixture of VAR (SAMoVAR), a linear Transformer variant that integrates interpretable dynamic VAR weights for multivariate TSF. By aligning the Transformer architecture with autoregressive objectives, SAMoVAR delivers improved performance, interpretability, and computational efficiency, comparing to SOTA TSF models.