 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Moving-average Attention Mechanism for Time Series Forecasting
Paper and Code

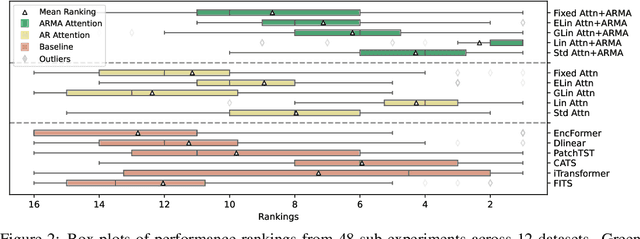
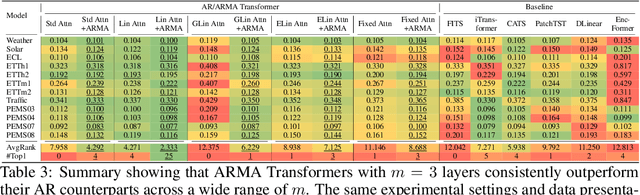
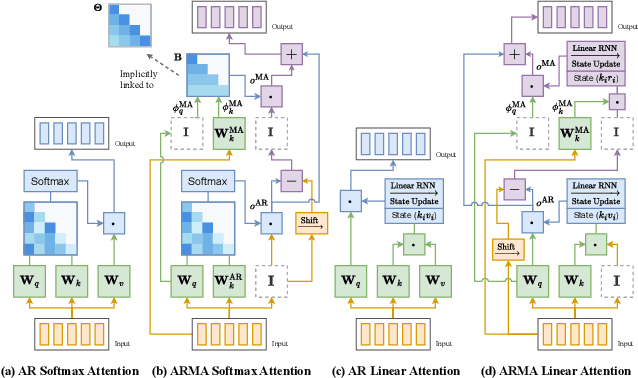
We propose an Autoregressive (AR) Moving-average (MA) attention structure that can adapt to various linear attention mechanisms, enhancing their ability to capture long-range and local temporal patterns in time series. In this paper, we first demonstrate that, for the time series forecasting (TSF) task, the previously overlooked decoder-only autoregressive Transformer model can achieve results comparable to the best baselines when appropriate tokenization and training methods are applied. Moreover, inspired by the ARMA model from statistics and recent advances in linear attention, we introduce the full ARMA structure into existing autoregressive attention mechanisms. By using an indirect MA weight generation method, we incorporate the MA term while maintaining the time complexity and parameter size of the underlying efficient attention models. We further explore how indirect parameter generation can produce implicit MA weights that align with the modeling requirements for local temporal impacts. Experimental results show that incorporating the ARMA structure consistently improves the performance of various AR attentions on TSF tasks, achieving state-of-the-art results.