 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow-based Conformal Prediction for Multi-dimensional Time Series
Feb 08, 2025



Conformal prediction for time series presents two key challenges: (1) leveraging sequential correlations in features and non-conformity scores and (2) handling multi-dimensional outcomes. We propose a novel conformal prediction method to address these two key challenges by integrating Transformer and Normalizing Flow. Specifically, the Transformer encodes the historical context of time series, and normalizing flow learns the transformation from the base distribution to the distribution of non-conformity scores conditioned on the encoded historical context. This enables the construction of prediction regions by transforming samples from the base distribution using the learned conditional flow. We ensure the marginal coverage by defining the prediction regions as sets in the transformed space that correspond to a predefined probability mass in the base distribution. The model is trained end-to-end by Flow Matching, avoiding the need for computationally intensive numerical solutions of ordinary differential equations. We demonstrate that our proposed method achieves smaller prediction regions compared to the baselines while satisfying the desired coverage through comprehensive experiments using simulated and real-world time series datasets.
Inverse Probability of Treatment Weighting with Deep Sequence Models Enables Accurate treatment effect Estimation from Electronic Health Records
Jun 13, 2024



Observational data have been actively used to estimate treatment effect, driven by the growing availability of electronic health records (EHRs). However, EHRs typically consist of longitudinal records, often introducing time-dependent confoundings that hinder the unbiased estimation of treatment effect. Inverse probability of treatment weighting (IPTW) is a widely used propensity score method since it provides unbiased treatment effect estimation and its derivation is straightforward. In this study, we aim to utilize IPTW to estimate treatment effect in the presence of time-dependent confounding using claims records. Previous studies have utilized propensity score methods with features derived from claims records through feature processing, which generally requires domain knowledge and additional resources to extract information to accurately estimate propensity scores. Deep sequence models, particularly recurrent neural networks and self-attention-based architectures, have demonstrated good performance in modeling EHRs for various downstream tasks. We propose that these deep sequence models can provide accurate IPTW estimation of treatment effect by directly estimating the propensity scores from claims records without the need for feature processing. We empirically demonstrate this by conducting comprehensive evaluations using synthetic and semi-synthetic datasets.
Transformer Conformal Prediction for Time Series
Jun 08, 2024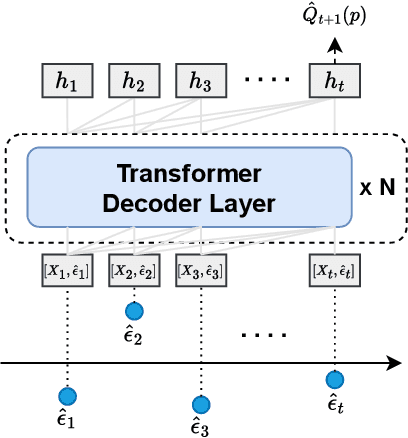
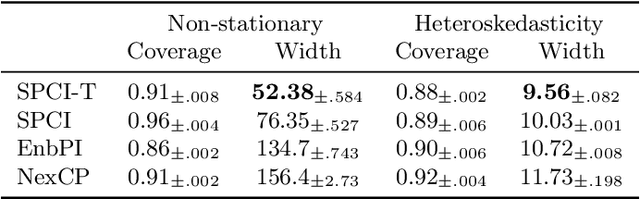
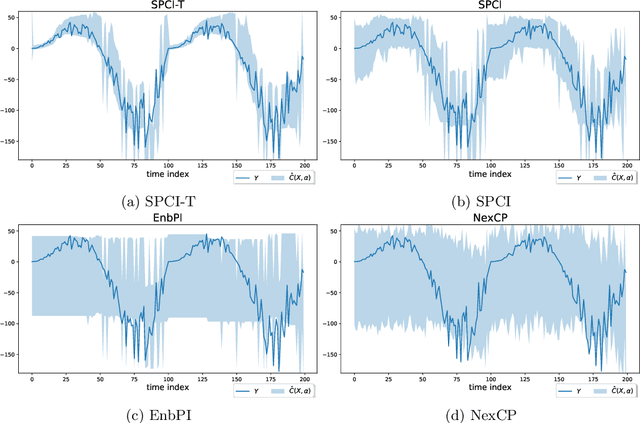
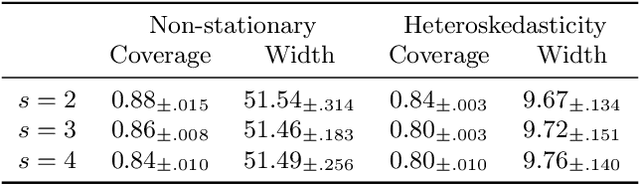
We present a conformal prediction method for time series using the Transformer architecture to capture long-memory and long-range dependencies. Specifically, we use the Transformer decoder as a conditional quantile estimator to predict the quantiles of prediction residuals, which are used to estimate the prediction interval. We hypothesize that the Transformer decoder benefits the estimation of the prediction interval by learning temporal dependencies across past prediction residuals. Our comprehensive experiments using simulated and real data empirically demonstrate the superiority of the proposed method compared to the existing state-of-the-art conformal prediction methods.
Federated Learning in Temporal Heterogeneity
Sep 17, 2023In this work, we explored federated learning in temporal heterogeneity across clients. We observed that global model obtained by \texttt{FedAvg} trained with fixed-length sequences shows faster convergence than varying-length sequences. We proposed methods to mitigate temporal heterogeneity for efficient federated learning based on the empirical observation.
Deep Attention Q-Network for Personalized Treatment Recommendation
Jul 04, 2023



Tailoring treatment for individual patients is crucial yet challenging in order to achieve optimal healthcare outcomes. Recent advances in reinforcement learning offer promising personalized treatment recommendations; however, they rely solely on current patient observations (vital signs, demographics) as the patient's state, which may not accurately represent the true health status of the patient. This limitation hampers policy learning and evaluation, ultimately limiting treatment effectiveness. In this study, we propose the Deep Attention Q-Network for personalized treatment recommendations, utilizing the Transformer architecture within a deep reinforcement learning framework to efficiently incorporate all past patient observations. We evaluated the model on real-world sepsis and acute hypotension cohorts, demonstrating its superiority to state-of-the-art models. The source code for our model is available at https://github.com/stevenmsm/RL-ICU-DAQN.
Training Neural Networks for Sequential Change-point Detection
Oct 31, 2022Detecting an abrupt distributional shift of the data stream, known as change-point detection, is a fundamental problem in statistics and signal processing. We present a new approach for online change-point detection by training neural networks (NN), and sequentially cumulating the detection statistics by evaluating the trained discriminating function on test samples by a CUSUM recursion. The idea is based on the observation that training neural networks through logistic loss may lead to the log-likelihood function. We demonstrated the good performance of NN-CUSUM on detecting change-point in high-dimensional data using both synthetic and real-world data.
Epistasis-based Basis Estimation Method for Simplifying the Problem Space of an Evolutionary Search in Binary Representation
Apr 19, 2019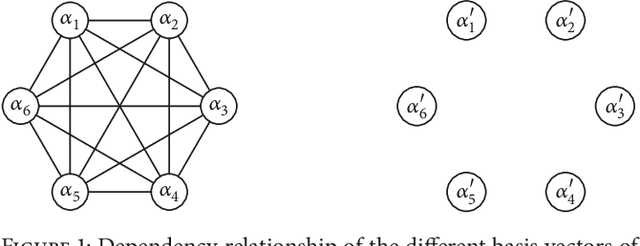
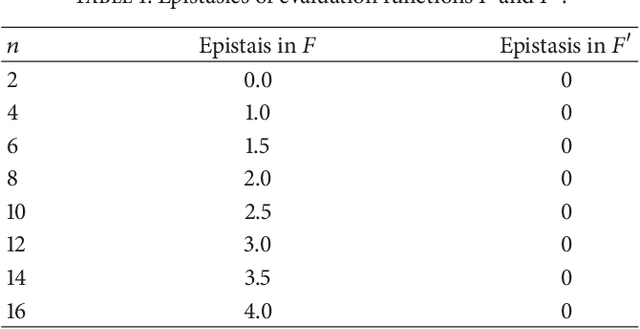

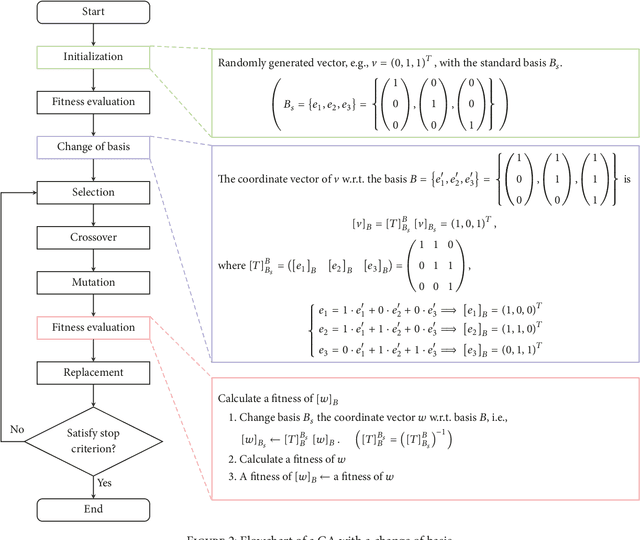
An evolutionary search space can be smoothly transformed via a suitable change of basis; however, it can be difficult to determine an appropriate basis. In this paper, a method is proposed to select an optimum basis can be used to simplify an evolutionary search space in a binary encoding scheme. The basis search method is based on a genetic algorithm and the fitness evaluation is based on the epistasis, which is an indicator of the complexity of a genetic algorithm. Two tests were conducted to validate the proposed method when applied to two different evolutionary search problems. The first searched for an appropriate basis to apply, while the second searched for a solution to the test problem. The results obtained after the identified basis had been applied were compared to those with the original basis, and it was found that the proposed method provided superior results.