 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Evaluation of LLM Performance with Statistical Guarantees
Jan 29, 2026Exhaustively evaluating many large language models (LLMs) on a large suite of benchmarks is expensive. We cast benchmarking as finite-population inference and, under a fixed query budget, seek tight confidence intervals (CIs) for model accuracy with valid frequentist coverage. We propose Factorized Active Querying (FAQ), which (a) leverages historical information through a Bayesian factor model; (b) adaptively selects questions using a hybrid variance-reduction/active-learning sampling policy; and (c) maintains validity through Proactive Active Inference -- a finite-population extension of active inference (Zrnic & Candès, 2024) that enables direct question selection while preserving coverage. With negligible overhead cost, FAQ delivers up to $5\times$ effective sample size gains over strong baselines on two benchmark suites, across varying historical-data missingness levels: this means that it matches the CI width of uniform sampling while using up to $5\times$ fewer queries. We release our source code and our curated datasets to support reproducible evaluation and future research.
Intelligently Weighting Multiple Reference Models for Direct Preference Optimization of LLMs
Dec 10, 2025Fine-tuning is integral for aligning large language models (LLMs) with human preferences. Multiple-Reference Preference Optimization (MRPO) builds on Direct Preference Optimization (DPO) by fine-tuning LLMs on preference datasets while regularizing the policy towards a mixture of reference models to leverage their collective desirable properties. However, current methods for setting the reference weights are ad-hoc and statistically unsound, leading to unreliable performance. To address this, we introduce four new weighting strategies: two offline methods that leverage held-out validation signal; one online method that uses a sliding-window estimator to reduce overfitting; and an online method that treats reference weighting as a $K$-armed bandit via Thompson Sampling. Experiments using Qwen2.5-0.5B as the policy model and seven reference models from the Llama, Mistral, Qwen, Yi, and Phi families (0.5B-14B each) show that all 4 of our strategies outperform the current MRPO weighting methods on UltraFeedback and SafeRLHF in preference accuracy. More thought-provokingly, however, we find that single-reference DPO, using any of 6 out of 7 references, consistently outperforms all tested multiple-reference approaches -- calling into question the practical appeal of multiple-reference approaches.
Are Statistical Methods Obsolete in the Era of Deep Learning?
May 27, 2025In the era of AI, neural networks have become increasingly popular for modeling, inference, and prediction, largely due to their potential for universal approximation. With the proliferation of such deep learning models, a question arises: are leaner statistical methods still relevant? To shed insight on this question, we employ the mechanistic nonlinear ordinary differential equation (ODE) inverse problem as a testbed, using physics-informed neural network (PINN) as a representative of the deep learning paradigm and manifold-constrained Gaussian process inference (MAGI) as a representative of statistically principled methods. Through case studies involving the SEIR model from epidemiology and the Lorenz model from chaotic dynamics, we demonstrate that statistical methods are far from obsolete, especially when working with sparse and noisy observations. On tasks such as parameter inference and trajectory reconstruction, statistically principled methods consistently achieve lower bias and variance, while using far fewer parameters and requiring less hyperparameter tuning. Statistical methods can also decisively outperform deep learning models on out-of-sample future prediction, where the absence of relevant data often leads overparameterized models astray. Additionally, we find that statistically principled approaches are more robust to accumulation of numerical imprecision and can represent the underlying system more faithful to the true governing ODEs.
Stabilizing Linear Passive-Aggressive Online Learning with Weighted Reservoir Sampling
Oct 31, 2024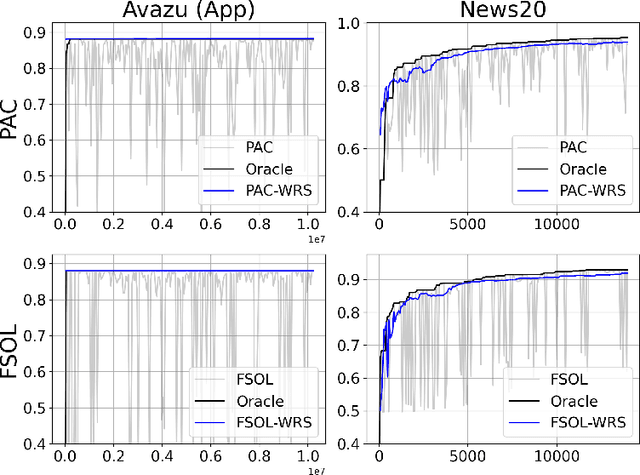
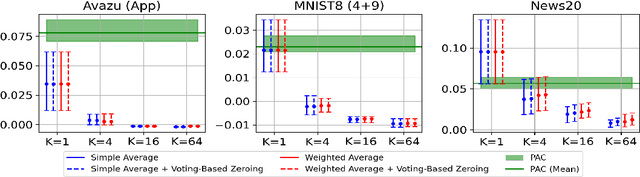
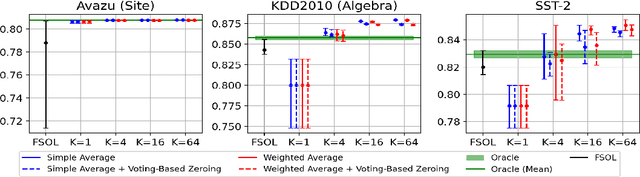
Online learning methods, like the seminal Passive-Aggressive (PA) classifier, are still highly effective for high-dimensional streaming data, out-of-core processing, and other throughput-sensitive applications. Many such algorithms rely on fast adaptation to individual errors as a key to their convergence. While such algorithms enjoy low theoretical regret, in real-world deployment they can be sensitive to individual outliers that cause the algorithm to over-correct. When such outliers occur at the end of the data stream, this can cause the final solution to have unexpectedly low accuracy. We design a weighted reservoir sampling (WRS) approach to obtain a stable ensemble model from the sequence of solutions without requiring additional passes over the data, hold-out sets, or a growing amount of memory. Our key insight is that good solutions tend to be error-free for more iterations than bad solutions, and thus, the number of passive rounds provides an estimate of a solution's relative quality. Our reservoir thus contains $K$ previous intermediate weight vectors with high survival times. We demonstrate our WRS approach on the Passive-Aggressive Classifier (PAC) and First-Order Sparse Online Learning (FSOL), where our method consistently and significantly outperforms the unmodified approach. We show that the risk of the ensemble classifier is bounded with respect to the regret of the underlying online learning method.
Analyzing Chain-of-Thought Prompting in Large Language Models via Gradient-based Feature Attributions
Jul 25, 2023



Chain-of-thought (CoT) prompting has been shown to empirically improve the accuracy of large language models (LLMs) on various question answering tasks. While understanding why CoT prompting is effective is crucial to ensuring that this phenomenon is a consequence of desired model behavior, little work has addressed this; nonetheless, such an understanding is a critical prerequisite for responsible model deployment. We address this question by leveraging gradient-based feature attribution methods which produce saliency scores that capture the influence of input tokens on model output. Specifically, we probe several open-source LLMs to investigate whether CoT prompting affects the relative importances they assign to particular input tokens. Our results indicate that while CoT prompting does not increase the magnitude of saliency scores attributed to semantically relevant tokens in the prompt compared to standard few-shot prompting, it increases the robustness of saliency scores to question perturbations and variations in model output.
Exploring the Sharpened Cosine Similarity
Jul 25, 2023



Convolutional layers have long served as the primary workhorse for image classification. Recently, an alternative to convolution was proposed using the Sharpened Cosine Similarity (SCS), which in theory may serve as a better feature detector. While multiple sources report promising results, there has not been to date a full-scale empirical analysis of neural network performance using these new layers. In our work, we explore SCS's parameter behavior and potential as a drop-in replacement for convolutions in multiple CNN architectures benchmarked on CIFAR-10. We find that while SCS may not yield significant increases in accuracy, it may learn more interpretable representations. We also find that, in some circumstances, SCS may confer a slight increase in adversarial robustness.