 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHYPE-EDIT-1: Benchmark for Measuring Reliability in Frontier Image Editing Models
Jan 25, 2026Public demos of image editing models are typically best-case samples; real workflows pay for retries and review time. We introduce HYPE-EDIT-1, a 100-task benchmark of reference-based marketing/design edits with binary pass/fail judging. For each task we generate 10 independent outputs to estimate per-attempt pass rate, pass@10, expected attempts under a retry cap, and an effective cost per successful edit that combines model price with human review time. We release 50 public tasks and maintain a 50-task held-out private split for server-side evaluation, plus a standardized JSON schema and tooling for VLM and human-based judging. Across the evaluated models, per-attempt pass rates span 34-83 percent and effective cost per success spans USD 0.66-1.42. Models that have low per-image pricing are more expensive when you consider the total effective cost of retries and human reviews.
Detecting Damage Building Using Real-time Crowdsourced Images and Transfer Learning
Oct 12, 2021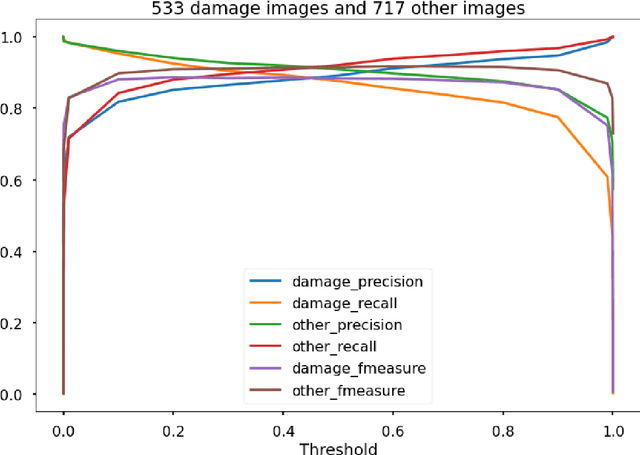


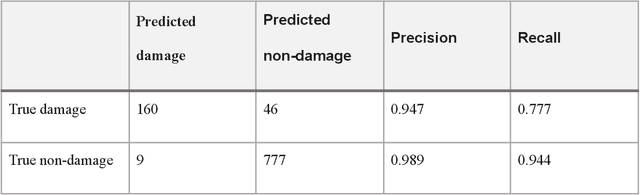
After significant earthquakes, we can see images posted on social media platforms by individuals and media agencies owing to the mass usage of smartphones these days. These images can be utilized to provide information about the shaking damage in the earthquake region both to the public and research community, and potentially to guide rescue work. This paper presents an automated way to extract the damaged building images after earthquakes from social media platforms such as Twitter and thus identify the particular user posts containing such images. Using transfer learning and ~6500 manually labelled images, we trained a deep learning model to recognize images with damaged buildings in the scene. The trained model achieved good performance when tested on newly acquired images of earthquakes at different locations and ran in near real-time on Twitter feed after the 2020 M7.0 earthquake in Turkey. Furthermore, to better understand how the model makes decisions, we also implemented the Grad-CAM method to visualize the important locations on the images that facilitate the decision.