 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhance word representation for out-of-vocabulary on Ubuntu dialogue corpus
Paper and Code

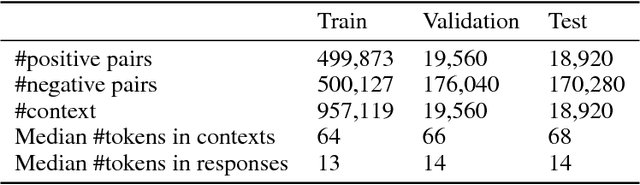
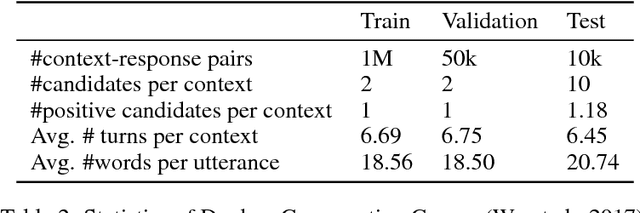
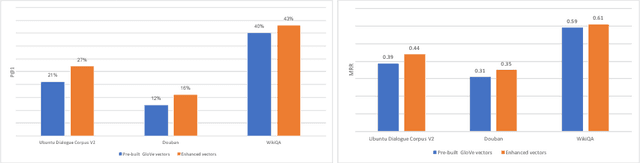
Ubuntu dialogue corpus is the largest public available dialogue corpus to make it feasible to build end-to-end deep neural network models directly from the conversation data. One challenge of Ubuntu dialogue corpus is the large number of out-of-vocabulary words. In this paper we proposed a method which combines the general pre-trained word embedding vectors with those generated on the task-specific training set to address this issue. We integrated character embedding into Chen et al's Enhanced LSTM method (ESIM) and used it to evaluate the effectiveness of our proposed method. For the task of next utterance selection, the proposed method has demonstrated a significant performance improvement against original ESIM and the new model has achieved state-of-the-art results on both Ubuntu dialogue corpus and Douban conversation corpus. In addition, we investigated the performance impact of end-of-utterance and end-of-turn token tags.