 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomously Untangling Long Cables
Jul 16, 2022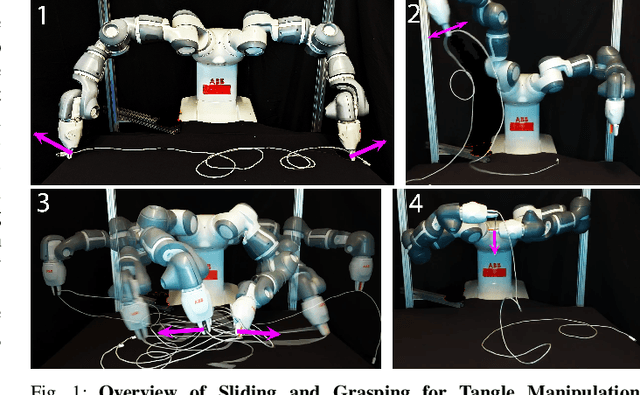


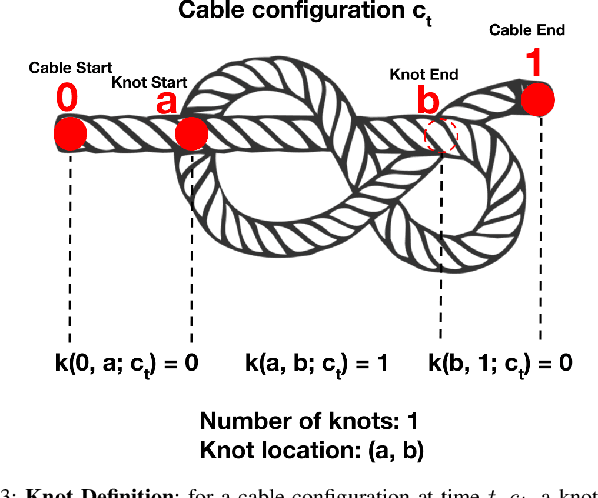
Cables are ubiquitous in many settings, but are prone to self-occlusions and knots, making them difficult to perceive and manipulate. The challenge often increases with cable length: long cables require more complex slack management and strategies to facilitate observability and reachability. In this paper, we focus on autonomously untangling cables up to 3 meters in length using a bilateral robot. We develop new motion primitives to efficiently untangle long cables and novel gripper jaws specialized for this task. We present Sliding and Grasping for Tangle Manipulation (SGTM), an algorithm that composes these primitives with RGBD vision to iteratively untangle. SGTM untangles cables with success rates of 67% on isolated overhand and figure eight knots and 50% on more complex configurations. Supplementary material, visualizations, and videos can be found at https://sites.google.com/view/rss-2022-untangling/home.
Efficiently Learning Single-Arm Fling Motions to Smooth Garments
Jun 17, 2022

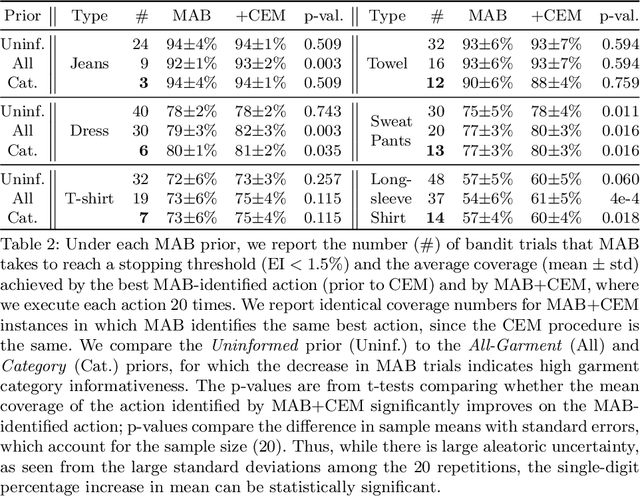
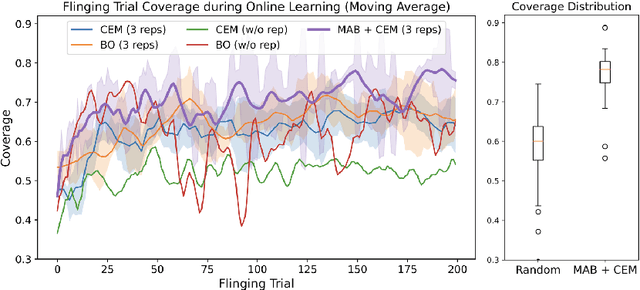
Recent work has shown that 2-arm "fling" motions can be effective for garment smoothing. We consider single-arm fling motions. Unlike 2-arm fling motions, which require little robot trajectory parameter tuning, single-arm fling motions are sensitive to trajectory parameters. We consider a single 6-DOF robot arm that learns fling trajectories to achieve high garment coverage. Given a garment grasp point, the robot explores different parameterized fling trajectories in physical experiments. To improve learning efficiency, we propose a coarse-to-fine learning method that first uses a multi-armed bandit (MAB) framework to efficiently find a candidate fling action, which it then refines via a continuous optimization method. Further, we propose novel training and execution-time stopping criteria based on fling outcome uncertainty. Compared to baselines, we show that the proposed method significantly accelerates learning. Moreover, with prior experience on similar garments collected through self-supervision, the MAB learning time for a new garment is reduced by up to 87%. We evaluate on 6 garment types: towels, T-shirts, long-sleeve shirts, dresses, sweat pants, and jeans. Results suggest that using prior experience, a robot requires under 30 minutes to learn a fling action for a novel garment that achieves 60-94% coverage.
CenterSnap: Single-Shot Multi-Object 3D Shape Reconstruction and Categorical 6D Pose and Size Estimation
Mar 03, 2022
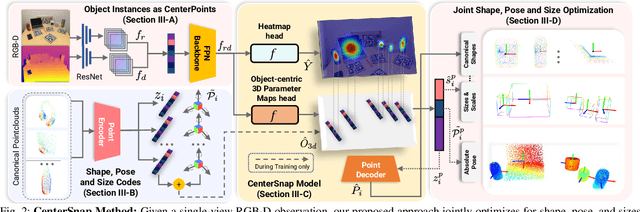
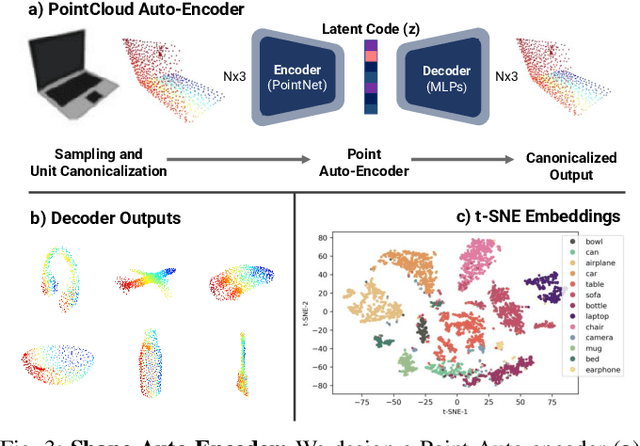
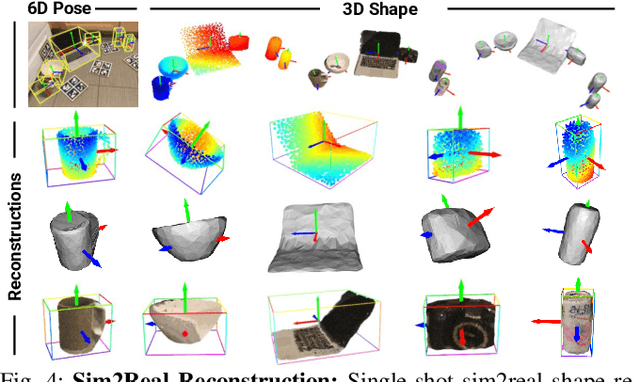
This paper studies the complex task of simultaneous multi-object 3D reconstruction, 6D pose and size estimation from a single-view RGB-D observation. In contrast to instance-level pose estimation, we focus on a more challenging problem where CAD models are not available at inference time. Existing approaches mainly follow a complex multi-stage pipeline which first localizes and detects each object instance in the image and then regresses to either their 3D meshes or 6D poses. These approaches suffer from high-computational cost and low performance in complex multi-object scenarios, where occlusions can be present. Hence, we present a simple one-stage approach to predict both the 3D shape and estimate the 6D pose and size jointly in a bounding-box free manner. In particular, our method treats object instances as spatial centers where each center denotes the complete shape of an object along with its 6D pose and size. Through this per-pixel representation, our approach can reconstruct in real-time (40 FPS) multiple novel object instances and predict their 6D pose and sizes in a single-forward pass. Through extensive experiments, we demonstrate that our approach significantly outperforms all shape completion and categorical 6D pose and size estimation baselines on multi-object ShapeNet and NOCS datasets respectively with a 12.6% absolute improvement in mAP for 6D pose for novel real-world object instances.
Planar Robot Casting with Real2Sim2Real Self-Supervised Learning
Nov 08, 2021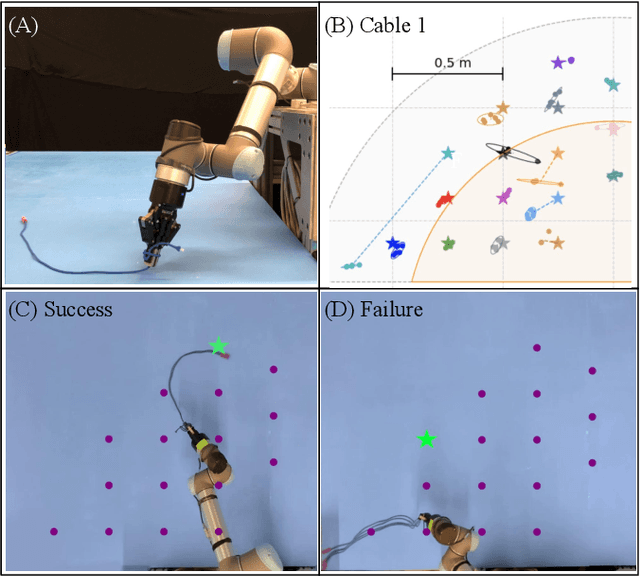
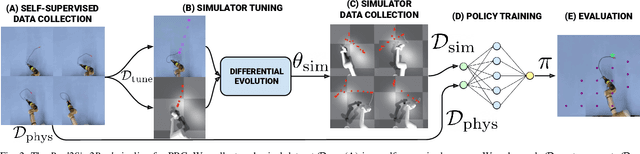
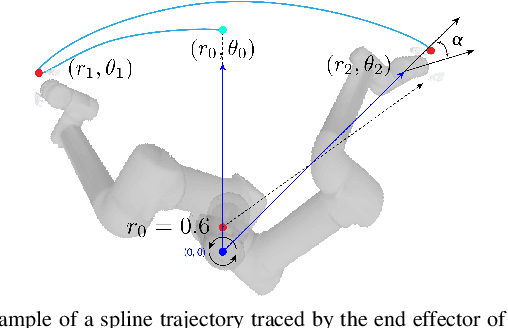

Manipulation of deformable objects using a single parameterized dynamic action can be useful for tasks such as fly fishing, lofting a blanket, and playing shuffleboard. Such tasks take as input a desired final state and output one parameterized open-loop dynamic robot action which produces a trajectory toward the final state. This is especially challenging for long-horizon trajectories with complex dynamics involving friction. This paper explores the task of Planar Robot Casting (PRC): where one planar motion of a robot wrist holding one end of a cable causes the other end to slide across the plane toward a desired target. PRC allows the cable to reach points beyond the robot's workspace and has applications for cable management in homes, warehouses, and factories. To efficiently learn a PRC policy for a given cable, we propose Real2Sim2Real, a self-supervised framework that automatically collects physical trajectory examples to tune parameters of a dynamics simulator using Differential Evolution, generates many simulated examples, and then learns a policy using a weighted combination of simulated and physical data. We evaluate Real2Sim2Real with three simulators, Isaac Gym-segmented, Isaac Gym-hybrid, and PyBullet, two function approximators, Gaussian Processes and Neural Networks (NNs), and three cables with differing stiffness, torsion, and friction. Results on 16 held-out test targets for each cable suggest that the NN PRC policies using Isaac Gym-segmented attain median error distance (as % of cable length) ranging from 8% to 14%, outperforming baselines and policies trained on only real or only simulated examples. Code, data, and videos are available at https://tinyurl.com/robotcast.
SimNet: Enabling Robust Unknown Object Manipulation from Pure Synthetic Data via Stereo
Jun 30, 2021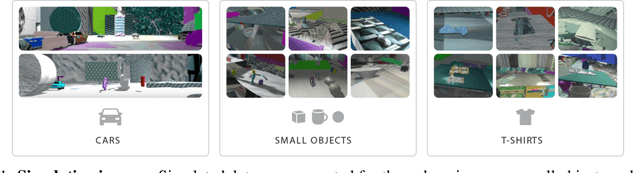
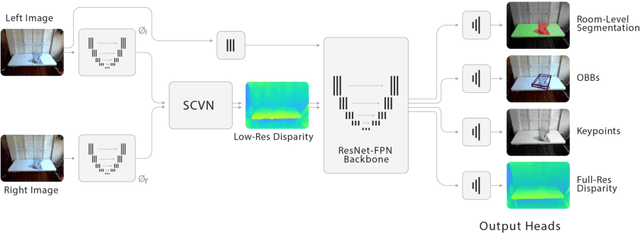

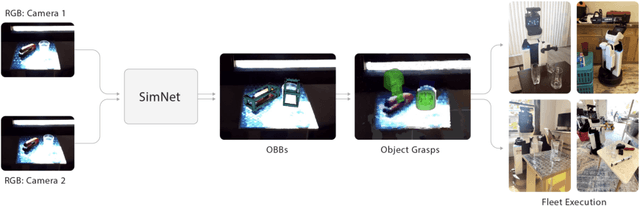
Robot manipulation of unknown objects in unstructured environments is a challenging problem due to the variety of shapes, materials, arrangements and lighting conditions. Even with large-scale real-world data collection, robust perception and manipulation of transparent and reflective objects across various lighting conditions remain challenging. To address these challenges we propose an approach to performing sim-to-real transfer of robotic perception. The underlying model, SimNet, is trained as a single multi-headed neural network using simulated stereo data as input and simulated object segmentation masks, 3D oriented bounding boxes (OBBs), object keypoints, and disparity as output. A key component of SimNet is the incorporation of a learned stereo sub-network that predicts disparity. SimNet is evaluated on 2D car detection, unknown object detection, and deformable object keypoint detection and significantly outperforms a baseline that uses a structured light RGB-D sensor. By inferring grasp positions using the OBB and keypoint predictions, SimNet can be used to perform end-to-end manipulation of unknown objects in both easy and hard scenarios using our fleet of Toyota HSR robots in four home environments. In unknown object grasping experiments, the predictions from the baseline RGB-D network and SimNet enable successful grasps of most of the easy objects. However, the RGB-D baseline only grasps 35% of the hard (e.g., transparent) objects, while SimNet grasps 95%, suggesting that SimNet can enable robust manipulation of unknown objects, including transparent objects, in unknown environments.
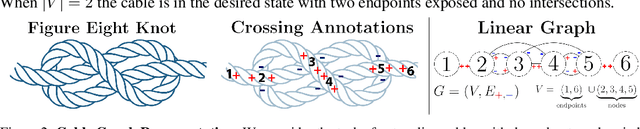
Untangling Dense Non-Planar Knots by Learning Manipulation Features and Recovery Policies
Jun 29, 2021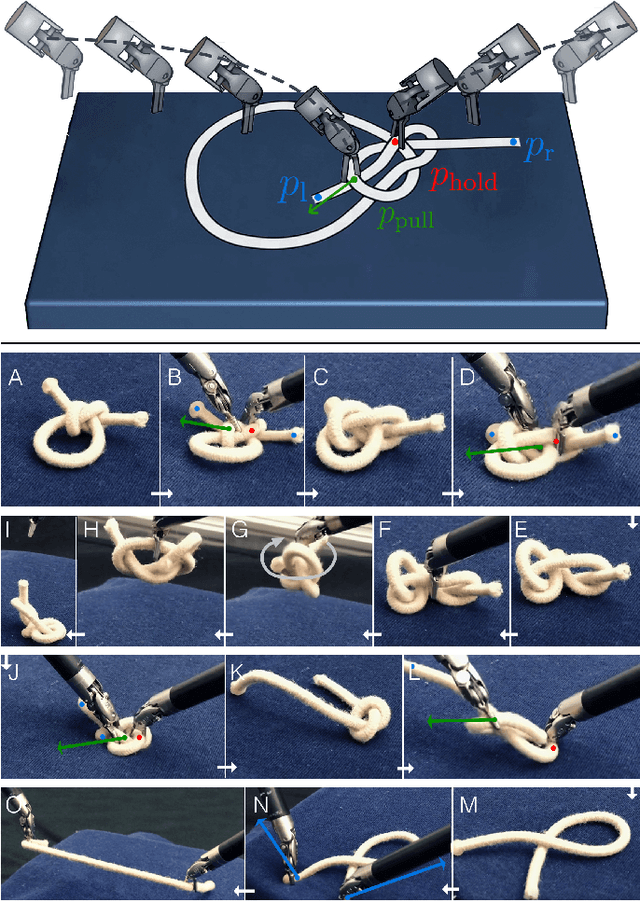
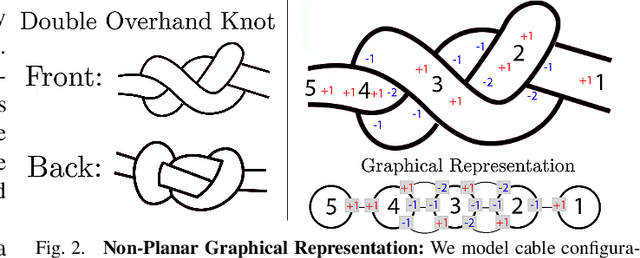
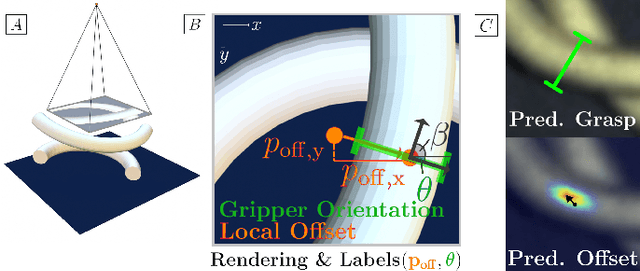
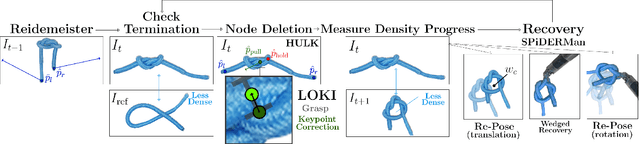
Robot manipulation for untangling 1D deformable structures such as ropes, cables, and wires is challenging due to their infinite dimensional configuration space, complex dynamics, and tendency to self-occlude. Analytical controllers often fail in the presence of dense configurations, due to the difficulty of grasping between adjacent cable segments. We present two algorithms that enhance robust cable untangling, LOKI and SPiDERMan, which operate alongside HULK, a high-level planner from prior work. LOKI uses a learned model of manipulation features to refine a coarse grasp keypoint prediction to a precise, optimized location and orientation, while SPiDERMan uses a learned model to sense task progress and apply recovery actions. We evaluate these algorithms in physical cable untangling experiments with 336 knots and over 1500 actions on real cables using the da Vinci surgical robot. We find that the combination of HULK, LOKI, and SPiDERMan is able to untangle dense overhand, figure-eight, double-overhand, square, bowline, granny, stevedore, and triple-overhand knots. The composition of these methods successfully untangles a cable from a dense initial configuration in 68.3% of 60 physical experiments and achieves 50% higher success rates than baselines from prior work. Supplementary material, code, and videos can be found at https://tinyurl.com/rssuntangling.
Disentangling Dense Multi-Cable Knots
Jun 04, 2021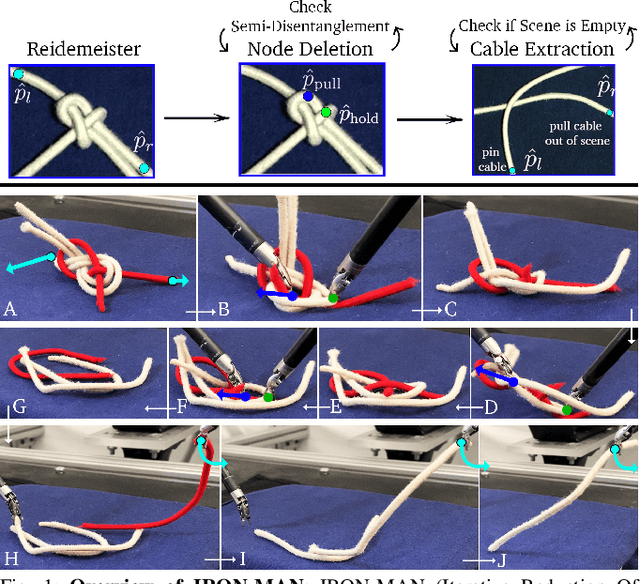
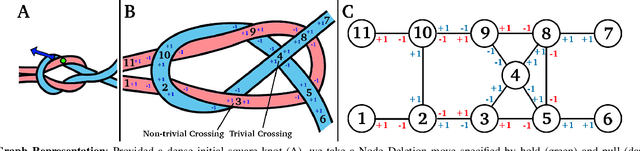
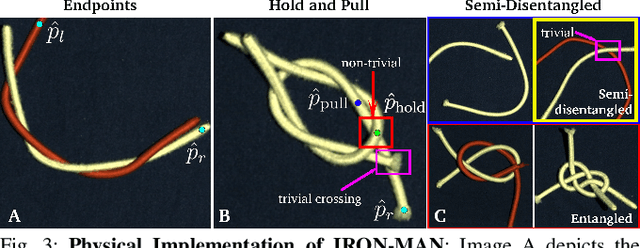

Disentangling two or more cables requires many steps to remove crossings between and within cables. We formalize the problem of disentangling multiple cables and present an algorithm, Iterative Reduction Of Non-planar Multiple cAble kNots (IRON-MAN), that outputs robot actions to remove crossings from multi-cable knotted structures. We instantiate this algorithm with a learned perception system, inspired by prior work in single-cable untying that given an image input, can disentangle two-cable twists, three-cable braids, and knots of two or three cables, such as overhand, square, carrick bend, sheet bend, crown, and fisherman's knots. IRON-MAN keeps track of task-relevant keypoints corresponding to target cable endpoints and crossings and iteratively disentangles the cables by identifying and undoing crossings that are critical to knot structure. Using a da Vinci surgical robot, we experimentally evaluate the effectiveness of IRON-MAN on untangling multi-cable knots of types that appear in the training data, as well as generalizing to novel classes of multi-cable knots. Results suggest that IRON-MAN is effective in disentangling knots involving up to three cables with 80.5% success and generalizing to knot types that are not present during training, with cables of both distinct or identical colors.
Untangling Dense Knots by Learning Task-Relevant Keypoints
Nov 10, 2020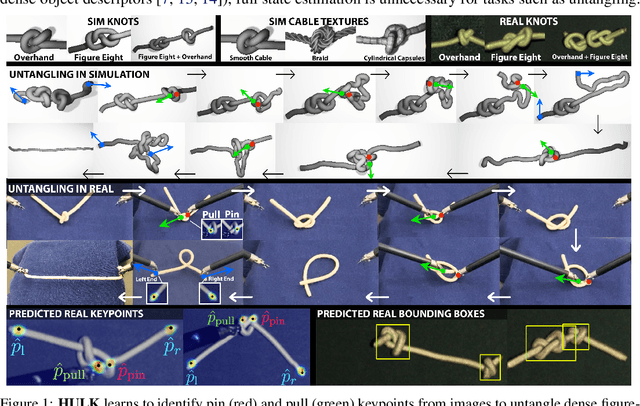
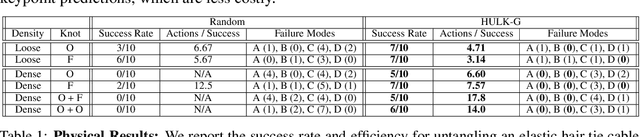

Untangling ropes, wires, and cables is a challenging task for robots due to the high-dimensional configuration space, visual homogeneity, self-occlusions, and complex dynamics. We consider dense (tight) knots that lack space between self-intersections and present an iterative approach that uses learned geometric structure in configurations. We instantiate this into an algorithm, HULK: Hierarchical Untangling from Learned Keypoints, which combines learning-based perception with a geometric planner into a policy that guides a bilateral robot to untangle knots. To evaluate the policy, we perform experiments both in a novel simulation environment modelling cables with varied knot types and textures and in a physical system using the da Vinci surgical robot. We find that HULK is able to untangle cables with dense figure-eight and overhand knots and generalize to varied textures and appearances. We compare two variants of HULK to three baselines and observe that HULK achieves 43.3% higher success rates on a physical system compared to the next best baseline. HULK successfully untangles a cable from a dense initial configuration containing up to two overhand and figure-eight knots in 97.9% of 378 simulation experiments with an average of 12.1 actions per trial. In physical experiments, HULK achieves 61.7% untangling success, averaging 8.48 actions per trial. Supplementary material, code, and videos can be found at https://tinyurl.com/y3a88ycu.
* Conference on Robot Learning (CoRL) 2020 Oral. First two authors contributed equally
Learning Rope Manipulation Policies Using Dense Object Descriptors Trained on Synthetic Depth Data
Mar 03, 2020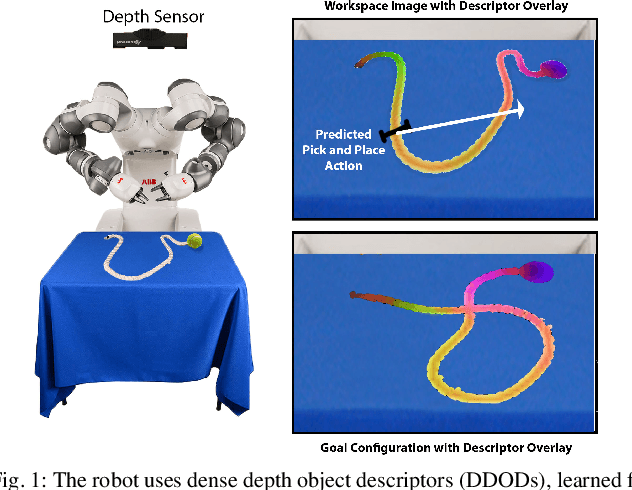
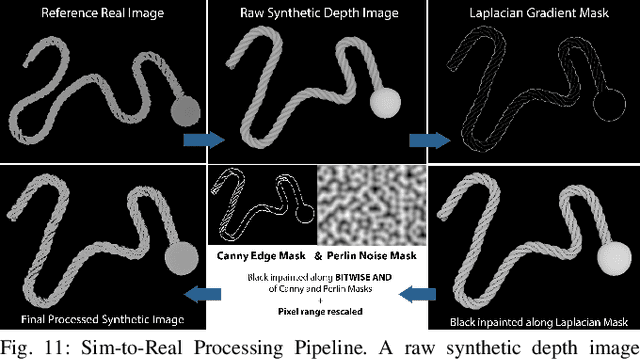
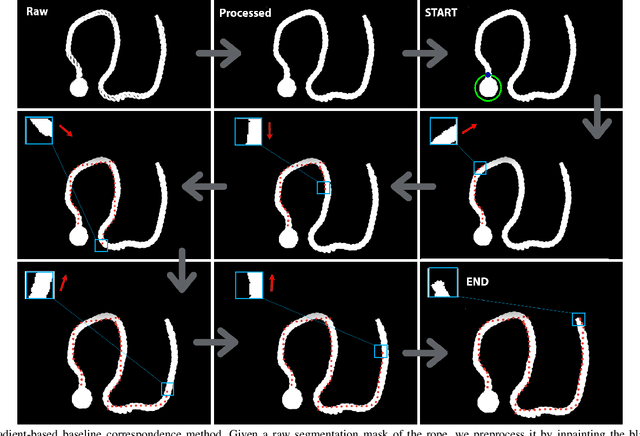
Robotic manipulation of deformable 1D objects such as ropes, cables, and hoses is challenging due to the lack of high-fidelity analytic models and large configuration spaces. Furthermore, learning end-to-end manipulation policies directly from images and physical interaction requires significant time on a robot and can fail to generalize across tasks. We address these challenges using interpretable deep visual representations for rope, extending recent work on dense object descriptors for robot manipulation. This facilitates the design of interpretable and transferable geometric policies built on top of the learned representations, decoupling visual reasoning and control. We present an approach that learns point-pair correspondences between initial and goal rope configurations, which implicitly encodes geometric structure, entirely in simulation from synthetic depth images. We demonstrate that the learned representation -- dense depth object descriptors (DDODs) -- can be used to manipulate a real rope into a variety of different arrangements either by learning from demonstrations or using interpretable geometric policies. In 50 trials of a knot-tying task with the ABB YuMi Robot, the system achieves a 66% knot-tying success rate from previously unseen configurations. See https://tinyurl.com/rope-learning for supplementary material and videos.
A Mobile Manipulation System for One-Shot Teaching of Complex Tasks in Homes
Oct 03, 2019
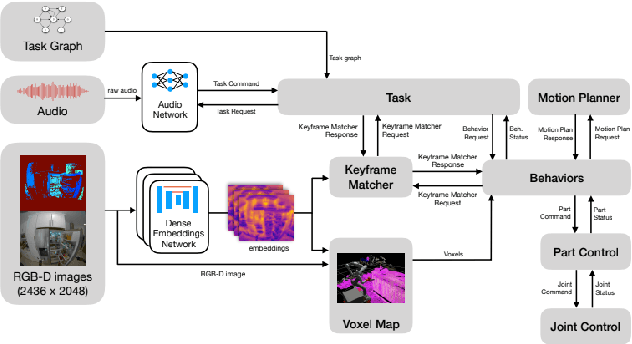
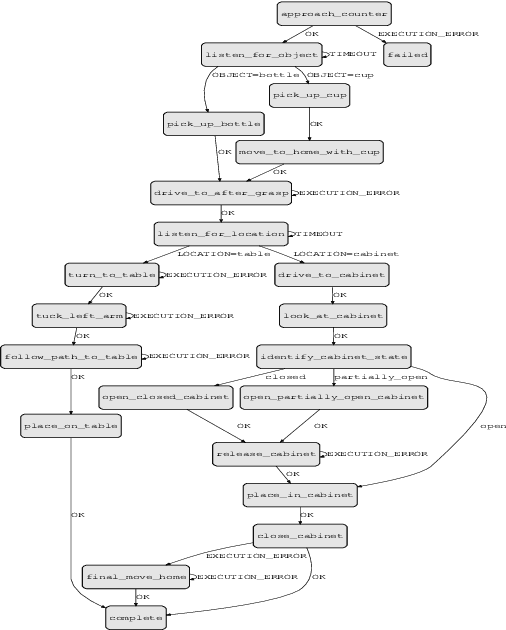

We describe a mobile manipulation hardware and software system capable of autonomously performing complex human-level tasks in real homes, after being taught the task with a single demonstration from a person in virtual reality. This is enabled by a highly capable mobile manipulation robot, whole-body task space hybrid position/force control, teaching of parameterized primitives linked to a robust learned dense visual embeddings representation of the scene, and a task graph of the taught behaviors. We demonstrate the robustness of the approach by presenting results for performing a variety of tasks, under different environmental conditions, in multiple real homes. Our approach achieves 85% overall success rate on three tasks that consist of an average of 45 behaviors each.