 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Rope Manipulation Policies Using Dense Object Descriptors Trained on Synthetic Depth Data
Paper and Code
Mar 03, 2020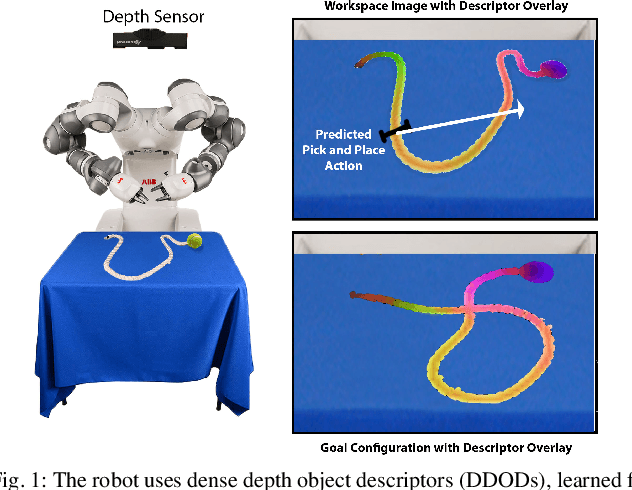
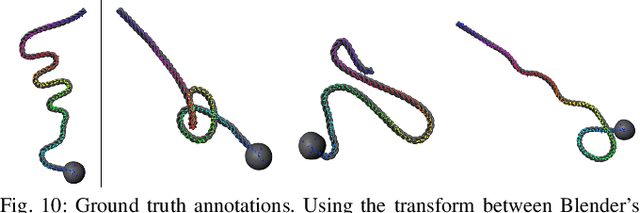
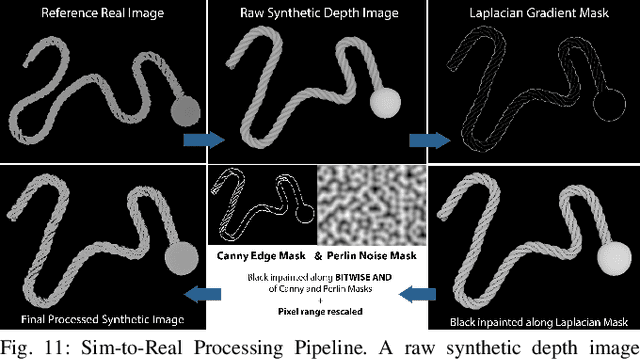
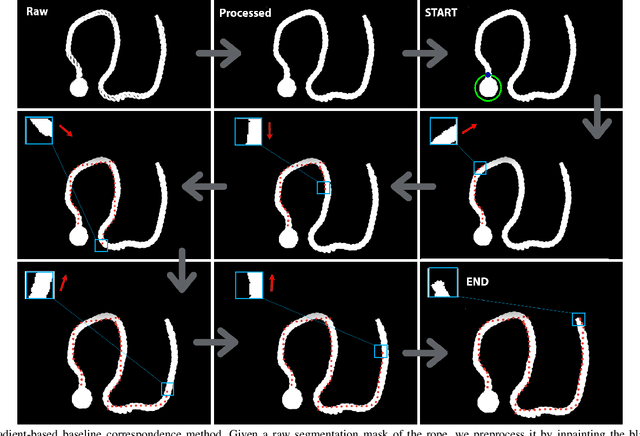
Robotic manipulation of deformable 1D objects such as ropes, cables, and hoses is challenging due to the lack of high-fidelity analytic models and large configuration spaces. Furthermore, learning end-to-end manipulation policies directly from images and physical interaction requires significant time on a robot and can fail to generalize across tasks. We address these challenges using interpretable deep visual representations for rope, extending recent work on dense object descriptors for robot manipulation. This facilitates the design of interpretable and transferable geometric policies built on top of the learned representations, decoupling visual reasoning and control. We present an approach that learns point-pair correspondences between initial and goal rope configurations, which implicitly encodes geometric structure, entirely in simulation from synthetic depth images. We demonstrate that the learned representation -- dense depth object descriptors (DDODs) -- can be used to manipulate a real rope into a variety of different arrangements either by learning from demonstrations or using interpretable geometric policies. In 50 trials of a knot-tying task with the ABB YuMi Robot, the system achieves a 66% knot-tying success rate from previously unseen configurations. See https://tinyurl.com/rope-learning for supplementary material and videos.