 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDDLP: Unsupervised Object-Centric Video Prediction with Deep Dynamic Latent Particles
Paper and Code


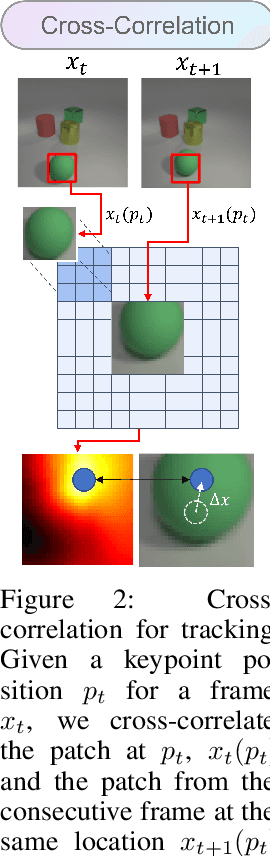

We propose a new object-centric video prediction algorithm based on the deep latent particle (DLP) representation. In comparison to existing slot- or patch-based representations, DLPs model the scene using a set of keypoints with learned parameters for properties such as position and size, and are both efficient and interpretable. Our method, deep dynamic latent particles (DDLP), yields state-of-the-art object-centric video prediction results on several challenging datasets. The interpretable nature of DDLP allows us to perform ``what-if'' generation -- predict the consequence of changing properties of objects in the initial frames, and DLP's compact structure enables efficient diffusion-based unconditional video generation. Videos, code and pre-trained models are available: https://taldatech.github.io/ddlp-web