 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Image Representation Learning with Deep Latent Particles
Paper and Code
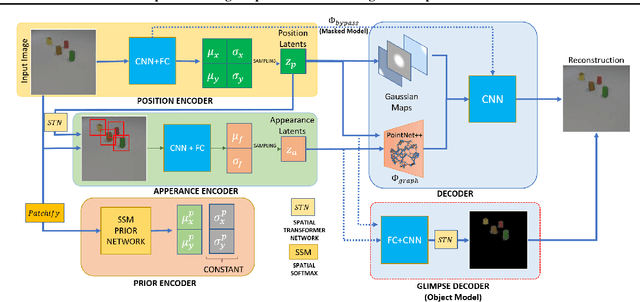
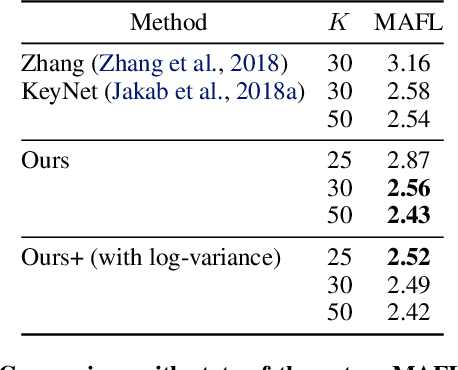


We propose a new representation of visual data that disentangles object position from appearance. Our method, termed Deep Latent Particles (DLP), decomposes the visual input into low-dimensional latent ``particles'', where each particle is described by its spatial location and features of its surrounding region. To drive learning of such representations, we follow a VAE-based approach and introduce a prior for particle positions based on a spatial-softmax architecture, and a modification of the evidence lower bound loss inspired by the Chamfer distance between particles. We demonstrate that our DLP representations are useful for downstream tasks such as unsupervised keypoint (KP) detection, image manipulation, and video prediction for scenes composed of multiple dynamic objects. In addition, we show that our probabilistic interpretation of the problem naturally provides uncertainty estimates for particle locations, which can be used for model selection, among other tasks. Videos and code are available: https://taldatech.github.io/deep-latent-particles-web/