 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfScene-SR: Spatially Continuous Inference for Arbitrary-Size Image Super-Resolution
Feb 23, 2026Image Super-Resolution (SR) aims to recover high-resolution (HR) details from low-resolution (LR) inputs, a task where Denoising Diffusion Probabilistic Models (DDPMs) have recently shown superior performance compared to Generative Adversarial Networks (GANs) based approaches. However, standard diffusion-based SR models, such as SR3, are typically trained on fixed-size patches and struggle to scale to arbitrary-sized images due to memory constraints. Applying these models via independent patch processing leads to visible seams and inconsistent textures across boundaries. In this paper, we propose InfScene-SR, a framework enabling spatially continuous super-resolution for large, arbitrary scenes. We adapt the iterative refinement process of diffusion models with a novel guided and variance-corrected fusion mechanism, allowing for the seamless generation of large-scale high-resolution imagery without retraining. We validate our approach on remote sensing datasets, demonstrating that InfScene-SR not only reconstructs fine details with high perceptual quality but also eliminates boundary artifacts, benefiting downstream tasks such as semantic segmentation.
Guided and Variance-Corrected Fusion with One-shot Style Alignment for Large-Content Image Generation
Dec 17, 2024



Producing large images using small diffusion models is gaining increasing popularity, as the cost of training large models could be prohibitive. A common approach involves jointly generating a series of overlapped image patches and obtaining large images by merging adjacent patches. However, results from existing methods often exhibit obvious artifacts, e.g., seams and inconsistent objects and styles. To address the issues, we proposed Guided Fusion (GF), which mitigates the negative impact from distant image regions by applying a weighted average to the overlapping regions. Moreover, we proposed Variance-Corrected Fusion (VCF), which corrects data variance at post-averaging, generating more accurate fusion for the Denoising Diffusion Probabilistic Model. Furthermore, we proposed a one-shot Style Alignment (SA), which generates a coherent style for large images by adjusting the initial input noise without adding extra computational burden. Extensive experiments demonstrated that the proposed fusion methods improved the quality of the generated image significantly. As a plug-and-play module, the proposed method can be widely applied to enhance other fusion-based methods for large image generation.
Causality Extraction from Nuclear Licensee Event Reports Using a Hybrid Framework
Apr 08, 2024Industry-wide nuclear power plant operating experience is a critical source of raw data for performing parameter estimations in reliability and risk models. Much operating experience information pertains to failure events and is stored as reports containing unstructured data, such as narratives. Event reports are essential for understanding how failures are initiated and propagated, including the numerous causal relations involved. Causal relation extraction using deep learning represents a significant frontier in the field of natural language processing (NLP), and is crucial since it enables the interpretation of intricate narratives and connections contained within vast amounts of written information. This paper proposed a hybrid framework for causality detection and extraction from nuclear licensee event reports. The main contributions include: (1) we compiled an LER corpus with 20,129 text samples for causality analysis, (2) developed an interactive tool for labeling cause effect pairs, (3) built a deep-learning-based approach for causal relation detection, and (4) developed a knowledge based cause-effect extraction approach.
Interactive segmentation in aerial images: a new benchmark and an open access web-based tool
Aug 25, 2023
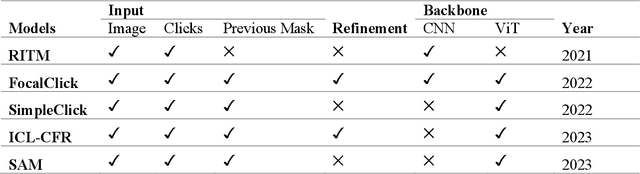

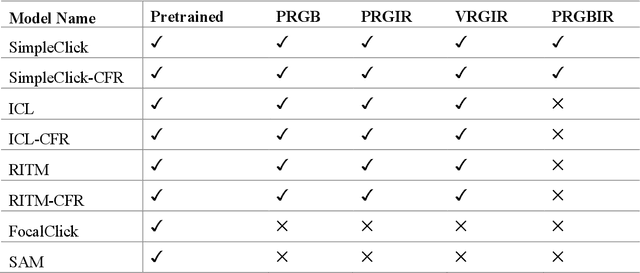
In recent years, deep learning has emerged as a powerful approach in remote sensing applications, particularly in segmentation and classification techniques that play a crucial role in extracting significant land features from satellite and aerial imagery. However, only a limited number of papers have discussed the use of deep learning for interactive segmentation in land cover classification tasks. In this study, we aim to bridge the gap between interactive segmentation and remote sensing image analysis by conducting a benchmark study on various deep learning-based interactive segmentation models. We assessed the performance of five state-of-the-art interactive segmentation methods (SimpleClick, FocalClick, Iterative Click Loss (ICL), Reviving Iterative Training with Mask Guidance for Interactive Segmentation (RITM), and Segment Anything (SAM)) on two high-resolution aerial imagery datasets. To enhance the segmentation results without requiring multiple models, we introduced the Cascade-Forward Refinement (CFR) approach, an innovative inference strategy for interactive segmentation. We evaluated these interactive segmentation methods on various land cover types, object sizes, and band combinations in remote sensing. Surprisingly, the popularly discussed method, SAM, proved to be ineffective for remote sensing images. Conversely, the point-based approach used in the SimpleClick models consistently outperformed the other methods in all experiments. Building upon these findings, we developed a dedicated online tool called RSISeg for interactive segmentation of remote sensing data. RSISeg incorporates a well-performing interactive model, fine-tuned with remote sensing data. Additionally, we integrated the SAM model into this tool. Compared to existing interactive segmentation tools, RSISeg offers strong interactivity, modifiability, and adaptability to remote sensing data.
CFR-ICL: Cascade-Forward Refinement with Iterative Click Loss for Interactive Image Segmentation
Mar 09, 2023



The click-based interactive segmentation aims to extract the object of interest from an image with the guidance of user clicks. Recent work has achieved great overall performance by employing the segmentation from the previous output. However, in most state-of-the-art approaches, 1) the inference stage involves inflexible heuristic rules and a separate refinement model; and 2) the training cannot balance the number of user clicks and model performance. To address the challenges, we propose a click-based and mask-guided interactive image segmentation framework containing three novel components: Cascade-Forward Refinement (CFR), Iterative Click Loss (ICL), and SUEM image augmentation. The proposed ICL allows model training to improve segmentation and reduce user interactions simultaneously. The CFR offers a unified inference framework to generate segmentation results in a coarse-to-fine manner. The proposed SUEM augmentation is a comprehensive way to create large and diverse training sets for interactive image segmentation. Extensive experiments demonstrate the state-of-the-art performance of the proposed approach on five public datasets. Remarkably, our model achieves an average of 2.9 and 7.5 clicks of NoC@95 on the Berkeley and DAVIS sets, respectively, improving by 33.2% and 15.5% over the previous state-of-the-art results. The code and trained model are available at https://github.com/TitorX/CFR-ICL-Interactive-Segmentation.
An Efficient Instance Segmentation Approach for Extracting Fission Gas Bubbles on U-10Zr Annular Fuel
Feb 08, 2023
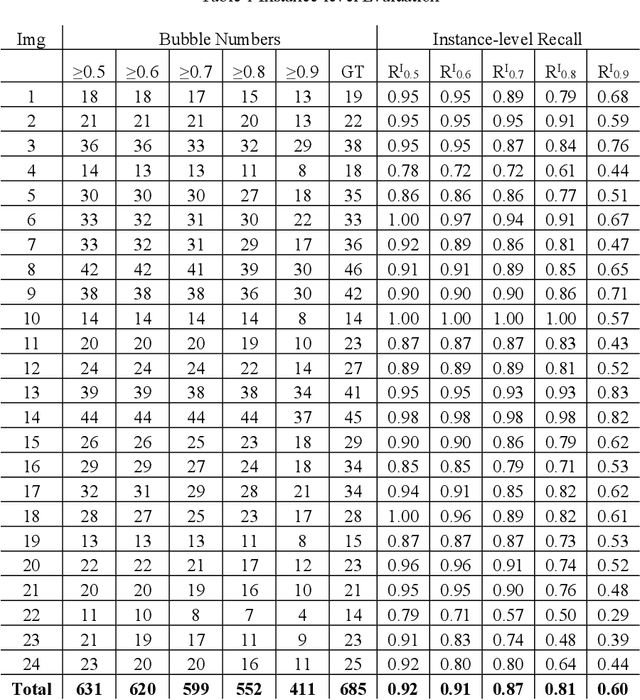
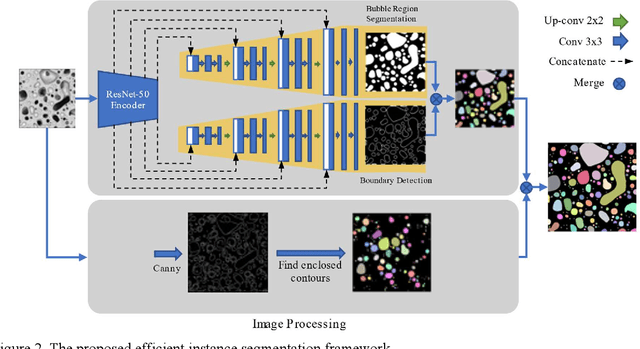
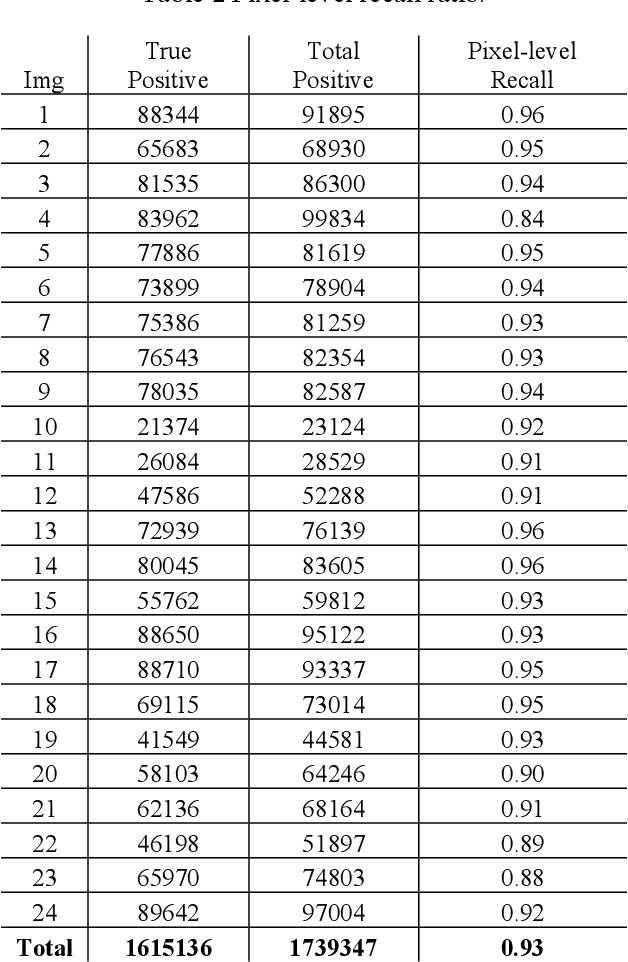
U-10Zr-based nuclear fuel is pursued as a primary candidate for next-generation sodium-cooled fast reactors. However, more advanced characterization and analysis are needed to form a fundamental understating of the fuel performance, and make U-10Zr fuel qualify for commercial use. The movement of lanthanides across the fuel section from the hot fuel center to the cool cladding surface is one of the key factors to affect fuel performance. In the advanced annular U-10Zr fuel, the lanthanides present as fission gas bubbles. Due to a lack of annotated data, existing literature utilized a multiple-threshold method to separate the bubbles and calculate bubble statistics on an annular fuel. However, the multiple-threshold method cannot achieve robust performance on images with different qualities and contrasts, and cannot distinguish different bubbles. This paper proposes a hybrid framework for efficient bubble segmentation. We develop a bubble annotation tool and generate the first fission gas bubble dataset with more than 3000 bubbles from 24 images. A multi-task deep learning network integrating U-Net and ResNet is designed to accomplish instance-level bubble segmentation. Combining the segmentation results and image processing step achieves the best recall ratio of more than 90% with very limited annotated data. Our model shows outstanding improvement by comparing the previously proposed thresholding method. The proposed method has promising to generate a more accurate quantitative analysis of fission gas bubbles on U-10Zr annular fuels. The results will contribute to identifying the bubbles with lanthanides and finally build the relationship between the thermal gradation and lanthanides movements of U-10Zr annular fuels. Mover, the deep learning model is applicable to other similar material micro-structure segmentation tasks.
MIRST-DM: Multi-Instance RST with Drop-Max Layer for Robust Classification of Breast Cancer
May 02, 2022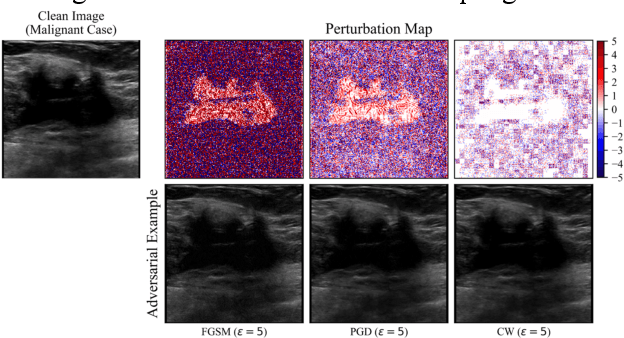
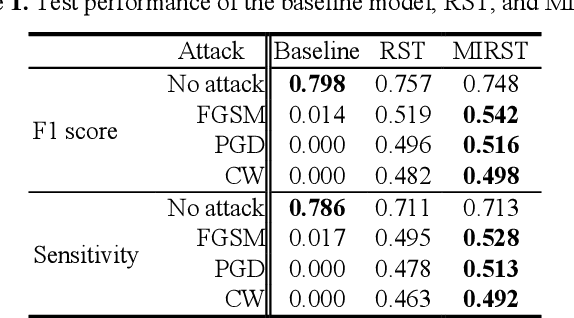
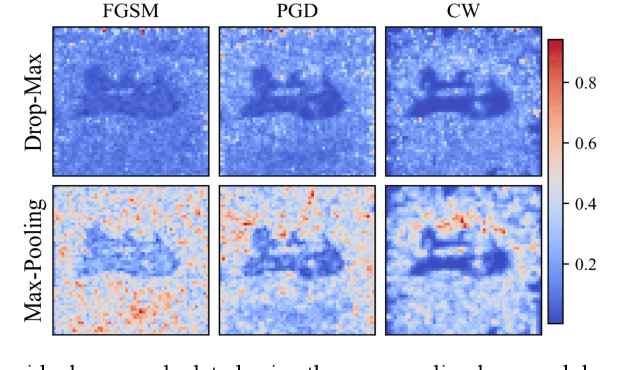

Robust self-training (RST) can augment the adversarial robustness of image classification models without significantly sacrificing models' generalizability. However, RST and other state-of-the-art defense approaches failed to preserve the generalizability and reproduce their good adversarial robustness on small medical image sets. In this work, we propose the Multi-instance RST with a drop-max layer, namely MIRST-DM, which involves a sequence of iteratively generated adversarial instances during training to learn smoother decision boundaries on small datasets. The proposed drop-max layer eliminates unstable features and helps learn representations that are robust to image perturbations. The proposed approach was validated using a small breast ultrasound dataset with 1,190 images. The results demonstrate that the proposed approach achieves state-of-the-art adversarial robustness against three prevalent attacks.