 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Parameter and Compute Efficient Diffusion Transformers using Distillation
Feb 20, 2025Diffusion Transformers (DiTs) with billions of model parameters form the backbone of popular image and video generation models like DALL.E, Stable-Diffusion and SORA. Though these models are necessary in many low-latency applications like Augmented/Virtual Reality, they cannot be deployed on resource-constrained Edge devices (like Apple Vision Pro or Meta Ray-Ban glasses) due to their huge computational complexity. To overcome this, we turn to knowledge distillation and perform a thorough design-space exploration to achieve the best DiT for a given parameter size. In particular, we provide principles for how to choose design knobs such as depth, width, attention heads and distillation setup for a DiT. During the process, a three-way trade-off emerges between model performance, size and speed that is crucial for Edge implementation of diffusion. We also propose two distillation approaches - Teaching Assistant (TA) method and Multi-In-One (MI1) method - to perform feature distillation in the DiT context. Unlike existing solutions, we demonstrate and benchmark the efficacy of our approaches on practical Edge devices such as NVIDIA Jetson Orin Nano.
Growing Efficient Accurate and Robust Neural Networks on the Edge
Oct 10, 2024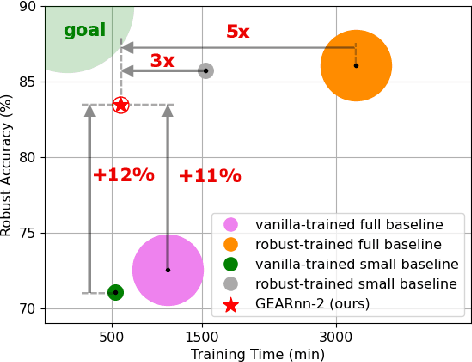
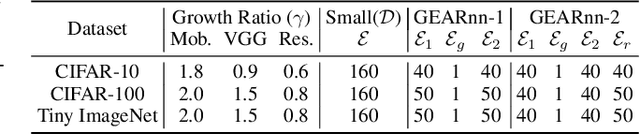
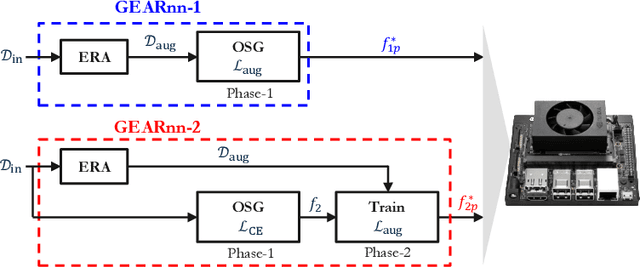
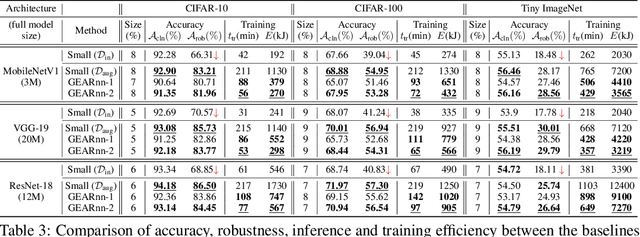
The ubiquitous deployment of deep learning systems on resource-constrained Edge devices is hindered by their high computational complexity coupled with their fragility to out-of-distribution (OOD) data, especially to naturally occurring common corruptions. Current solutions rely on the Cloud to train and compress models before deploying to the Edge. This incurs high energy and latency costs in transmitting locally acquired field data to the Cloud while also raising privacy concerns. We propose GEARnn (Growing Efficient, Accurate, and Robust neural networks) to grow and train robust networks in-situ, i.e., completely on the Edge device. Starting with a low-complexity initial backbone network, GEARnn employs One-Shot Growth (OSG) to grow a network satisfying the memory constraints of the Edge device using clean data, and robustifies the network using Efficient Robust Augmentation (ERA) to obtain the final network. We demonstrate results on a NVIDIA Jetson Xavier NX, and analyze the trade-offs between accuracy, robustness, model size, energy consumption, and training time. Our results demonstrate the construction of efficient, accurate, and robust networks entirely on an Edge device.