 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonGEMM Bench: Understanding the Performance Horizon of the Latest ML Workloads with NonGEMM Workloads
Paper and Code
Apr 17, 2024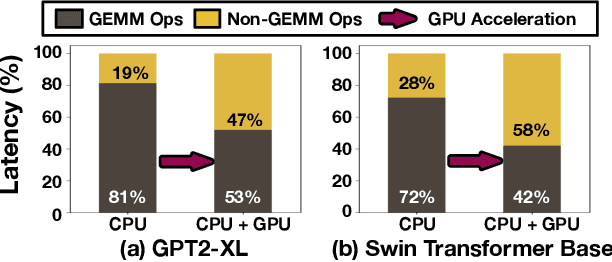
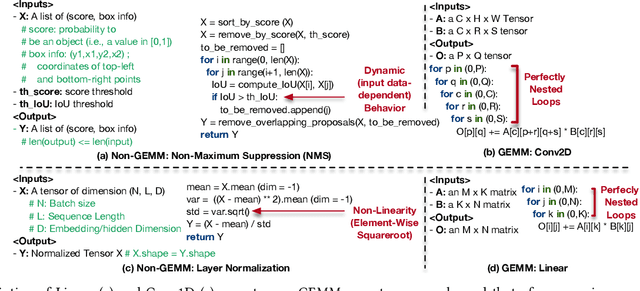
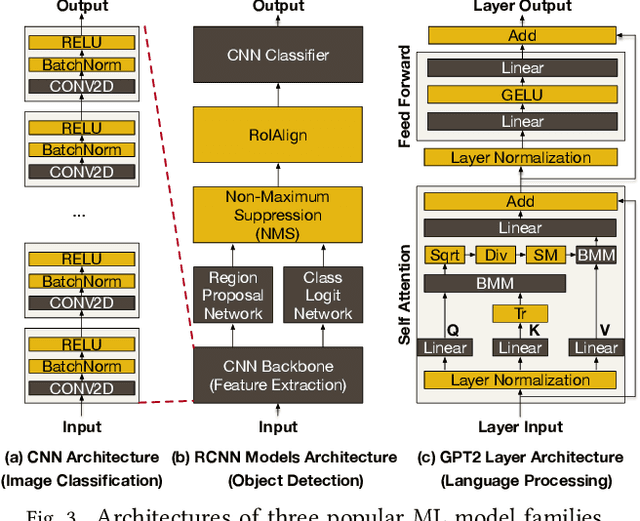
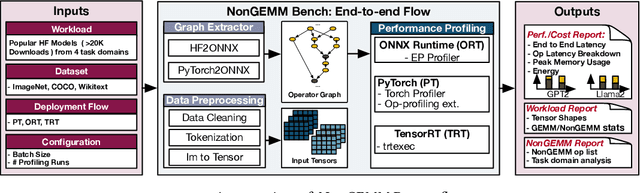
Machine Learning (ML) operators are the building blocks to design ML models with various target applications. GEneral Matrix Multiplication (GEMM) operators are the backbone of ML models. They are notorious for being computationally expensive requiring billions of multiply-and-accumulate. Therefore, significant effort has been put to study and optimize the GEMM operators in order to speed up the execution of ML models. GPUs and accelerators are widely deployed to accelerate ML workloads by optimizing the execution of GEMM operators. Nonetheless, the performance of NonGEMM operators have not been studied as thoroughly as GEMMs. Therefore, this paper describes \bench, a benchmark to study NonGEMM operators. We first construct \bench using popular ML workloads from different domains, then perform case studies on various grade GPU platforms to analyze the behavior of NonGEMM operators in GPU accelerated systems. Finally, we present some key takeaways to bridge the gap between GEMM and NonGEMM operators and to offer the community with potential new optimization directions.