 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing State Space Model (SSM) and SSM-Transformer Hybrid Language Model Performance with Long Context Length
Jul 16, 2025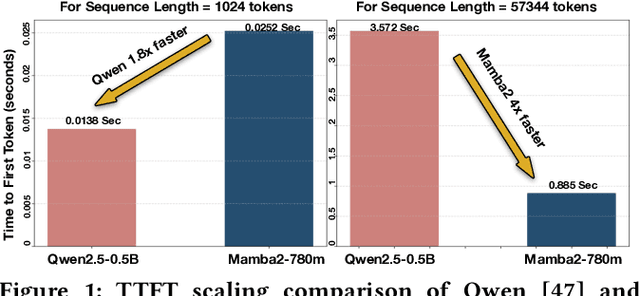

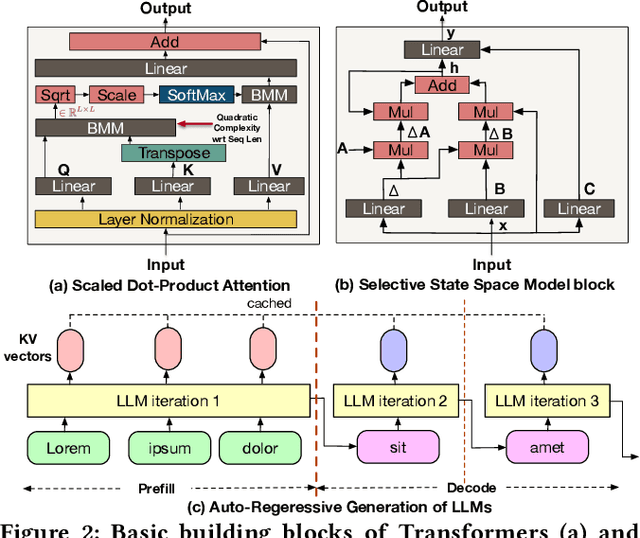
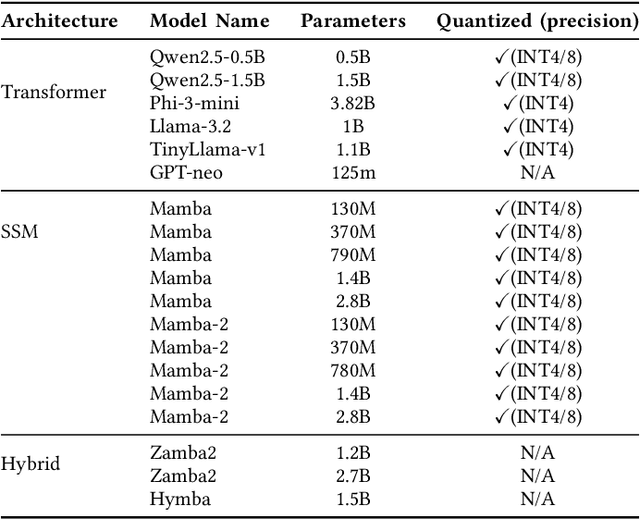
The demand for machine intelligence capable of processing continuous, long-context inputs on local devices is growing rapidly. However, the quadratic complexity and memory requirements of traditional Transformer architectures make them inefficient and often unusable for these tasks. This has spurred a paradigm shift towards new architectures like State Space Models (SSMs) and hybrids, which promise near-linear scaling. While most current research focuses on the accuracy and theoretical throughput of these models, a systematic performance characterization on practical consumer hardware is critically needed to guide system-level optimization and unlock new applications. To address this gap, we present a comprehensive, comparative benchmarking of carefully selected Transformer, SSM, and hybrid models specifically for long-context inference on consumer and embedded GPUs. Our analysis reveals that SSMs are not only viable but superior for this domain, capable of processing sequences up to 220K tokens on a 24GB consumer GPU-approximately 4x longer than comparable Transformers. While Transformers may be up to 1.8x faster at short sequences, SSMs demonstrate a dramatic performance inversion, becoming up to 4x faster at very long contexts (~57K tokens). Our operator-level analysis reveals that custom, hardware-aware SSM kernels dominate the inference runtime, accounting for over 55% of latency on edge platforms, identifying them as a primary target for future hardware acceleration. We also provide detailed, device-specific characterization results to guide system co-design for the edge. To foster further research, we will open-source our characterization framework.
BF-IMNA: A Bit Fluid In-Memory Neural Architecture for Neural Network Acceleration
Nov 03, 2024



Mixed-precision quantization works Neural Networks (NNs) are gaining traction for their efficient realization on the hardware leading to higher throughput and lower energy. In-Memory Computing (IMC) accelerator architectures are offered as alternatives to traditional architectures relying on a data-centric computational paradigm, diminishing the memory wall problem, and scoring high throughput and energy efficiency. These accelerators can support static fixed-precision but are not flexible to support mixed-precision NNs. In this paper, we present BF-IMNA, a bit fluid IMC accelerator for end-to-end Convolutional NN (CNN) inference that is capable of static and dynamic mixed-precision without any hardware reconfiguration overhead at run-time. At the heart of BF-IMNA are Associative Processors (APs), which are bit-serial word-parallel Single Instruction, Multiple Data (SIMD)-like engines. We report the performance of end-to-end inference of ImageNet on AlexNet, VGG16, and ResNet50 on BF-IMNA for different technologies (eNVM and NVM), mixed-precision configurations, and supply voltages. To demonstrate bit fluidity, we implement HAWQ-V3's per-layer mixed-precision configurations for ResNet18 on BF-IMNA using different latency budgets, and results reveal a trade-off between accuracy and Energy-Delay Product (EDP): On one hand, mixed-precision with a high latency constraint achieves the closest accuracy to fixed-precision INT8 and reports a high (worse) EDP compared to fixed-precision INT4. On the other hand, with a low latency constraint, BF-IMNA reports the closest EDP to fixed-precision INT4, with a higher degradation in accuracy compared to fixed-precision INT8. We also show that BF-IMNA with fixed-precision configuration still delivers performance that is comparable to current state-of-the-art accelerators: BF-IMNA achieves $20\%$ higher energy efficiency and $2\%$ higher throughput.
NonGEMM Bench: Understanding the Performance Horizon of the Latest ML Workloads with NonGEMM Workloads
Apr 17, 2024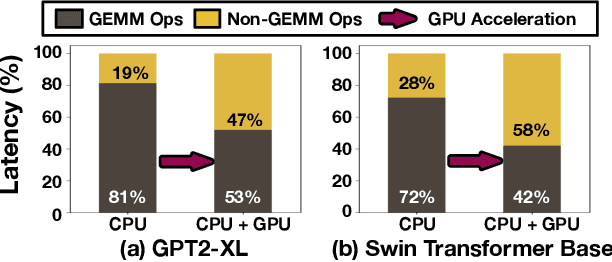
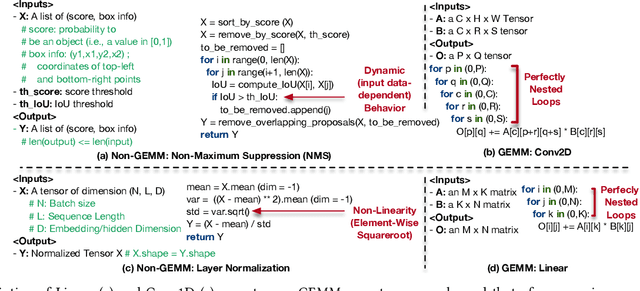
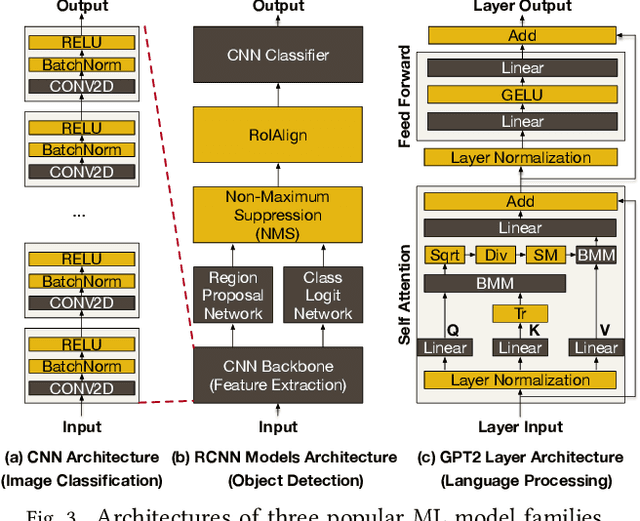
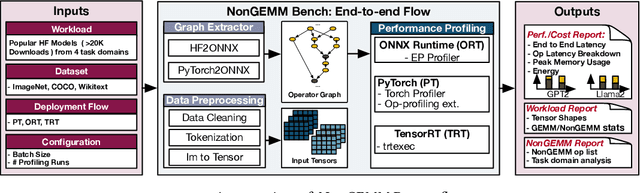
Machine Learning (ML) operators are the building blocks to design ML models with various target applications. GEneral Matrix Multiplication (GEMM) operators are the backbone of ML models. They are notorious for being computationally expensive requiring billions of multiply-and-accumulate. Therefore, significant effort has been put to study and optimize the GEMM operators in order to speed up the execution of ML models. GPUs and accelerators are widely deployed to accelerate ML workloads by optimizing the execution of GEMM operators. Nonetheless, the performance of NonGEMM operators have not been studied as thoroughly as GEMMs. Therefore, this paper describes \bench, a benchmark to study NonGEMM operators. We first construct \bench using popular ML workloads from different domains, then perform case studies on various grade GPU platforms to analyze the behavior of NonGEMM operators in GPU accelerated systems. Finally, we present some key takeaways to bridge the gap between GEMM and NonGEMM operators and to offer the community with potential new optimization directions.