 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdgeCIM: A Hardware-Software Co-Design for CIM-Based Acceleration of Small Language Models
Apr 13, 2026The growing demand for deploying Small Language Models (SLMs) on edge devices, including laptops, smartphones, and embedded platforms, has exposed fundamental inefficiencies in existing accelerators. While GPUs handle prefill workloads efficiently, the autoregressive decoding phase is dominated by GEMV operations that are inherently memory-bound, resulting in poor utilization and prohibitive energy costs at the edge. In this work, we present EdgeCIM, a hardware-software co-design framework that rethinks accelerator design for end-to-end decoder-only inference. At its core is a CIM macro, implemented in 65nm, coupled with a tile-based mapping strategy that balances pipeline stages, maximizing parallelism while alleviating DRAM bandwidth bottlenecks. Our simulator enables design space exploration of SLMs up to 4B parameters, identifying Pareto-optimal configurations in terms of latency and energy. Compared to an NVIDIA Orin Nano, EdgeCIM achieves up to 7.3x higher throughput and 49.59x better energy efficiency on LLaMA3.2-1B, and delivers 9.95x higher throughput than Qualcomm SA8255P on LLaMA3.2-3B. Extensive benchmarks on TinyLLaMA-1.1B, LLaMA3.2 (1B, 3B), Phi-3.5-mini-3.8B, Qwen2.5 (0.5B, 1.5B, 3B), SmolLM2-1.7B, SmolLM3-3B, and Qwen3 (0.6B, 1.7B, 4B) reveal that our accelerator, under INT4 precision, achieves on average 336.42 tokens/s and 173.02 tokens/J. These results establish EdgeCIM as a compelling solution towards real-time, energy-efficient edge-scale SLM inference.
SoftmAP: Software-Hardware Co-design for Integer-Only Softmax on Associative Processors
Nov 26, 2024



Recent research efforts focus on reducing the computational and memory overheads of Large Language Models (LLMs) to make them feasible on resource-constrained devices. Despite advancements in compression techniques, non-linear operators like Softmax and Layernorm remain bottlenecks due to their sensitivity to quantization. We propose SoftmAP, a software-hardware co-design methodology that implements an integer-only low-precision Softmax using In-Memory Compute (IMC) hardware. Our method achieves up to three orders of magnitude improvement in the energy-delay product compared to A100 and RTX3090 GPUs, making LLMs more deployable without compromising performance.
BF-IMNA: A Bit Fluid In-Memory Neural Architecture for Neural Network Acceleration
Nov 03, 2024



Mixed-precision quantization works Neural Networks (NNs) are gaining traction for their efficient realization on the hardware leading to higher throughput and lower energy. In-Memory Computing (IMC) accelerator architectures are offered as alternatives to traditional architectures relying on a data-centric computational paradigm, diminishing the memory wall problem, and scoring high throughput and energy efficiency. These accelerators can support static fixed-precision but are not flexible to support mixed-precision NNs. In this paper, we present BF-IMNA, a bit fluid IMC accelerator for end-to-end Convolutional NN (CNN) inference that is capable of static and dynamic mixed-precision without any hardware reconfiguration overhead at run-time. At the heart of BF-IMNA are Associative Processors (APs), which are bit-serial word-parallel Single Instruction, Multiple Data (SIMD)-like engines. We report the performance of end-to-end inference of ImageNet on AlexNet, VGG16, and ResNet50 on BF-IMNA for different technologies (eNVM and NVM), mixed-precision configurations, and supply voltages. To demonstrate bit fluidity, we implement HAWQ-V3's per-layer mixed-precision configurations for ResNet18 on BF-IMNA using different latency budgets, and results reveal a trade-off between accuracy and Energy-Delay Product (EDP): On one hand, mixed-precision with a high latency constraint achieves the closest accuracy to fixed-precision INT8 and reports a high (worse) EDP compared to fixed-precision INT4. On the other hand, with a low latency constraint, BF-IMNA reports the closest EDP to fixed-precision INT4, with a higher degradation in accuracy compared to fixed-precision INT8. We also show that BF-IMNA with fixed-precision configuration still delivers performance that is comparable to current state-of-the-art accelerators: BF-IMNA achieves $20\%$ higher energy efficiency and $2\%$ higher throughput.
Mixed-Precision Neural Networks: A Survey
Aug 11, 2022
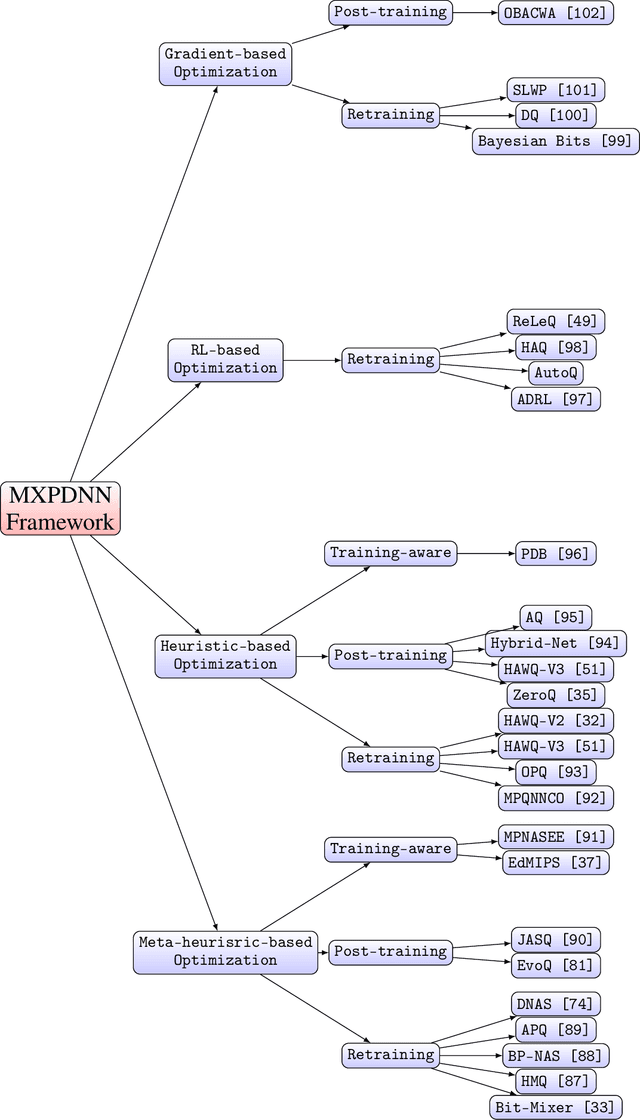

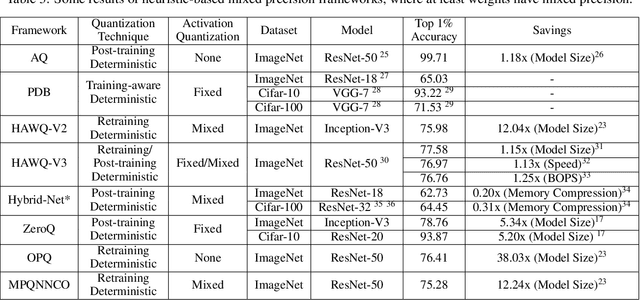
Mixed-precision Deep Neural Networks achieve the energy efficiency and throughput needed for hardware deployment, particularly when the resources are limited, without sacrificing accuracy. However, the optimal per-layer bit precision that preserves accuracy is not easily found, especially with the abundance of models, datasets, and quantization techniques that creates an enormous search space. In order to tackle this difficulty, a body of literature has emerged recently, and several frameworks that achieved promising accuracy results have been proposed. In this paper, we start by summarizing the quantization techniques used generally in literature. Then, we present a thorough survey of the mixed-precision frameworks, categorized according to their optimization techniques such as reinforcement learning and quantization techniques like deterministic rounding. Furthermore, the advantages and shortcomings of each framework are discussed, where we present a juxtaposition. We finally give guidelines for future mixed-precision frameworks.
DT2CAM: A Decision Tree to Content Addressable Memory Framework
Apr 12, 2022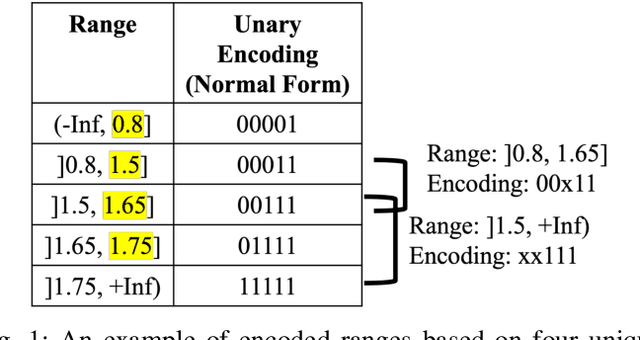
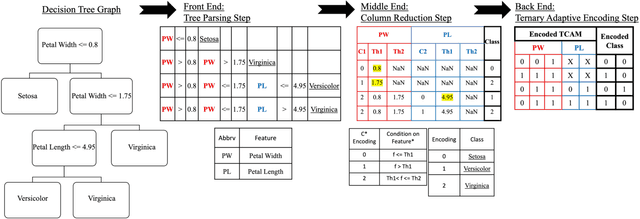
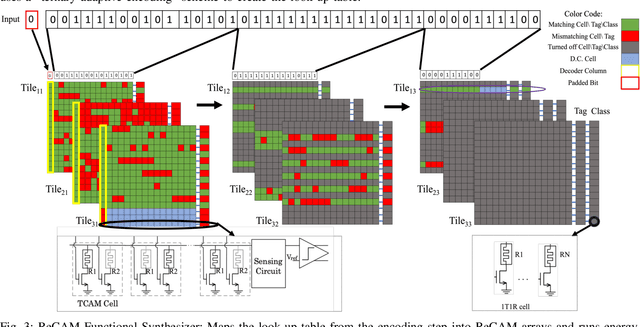
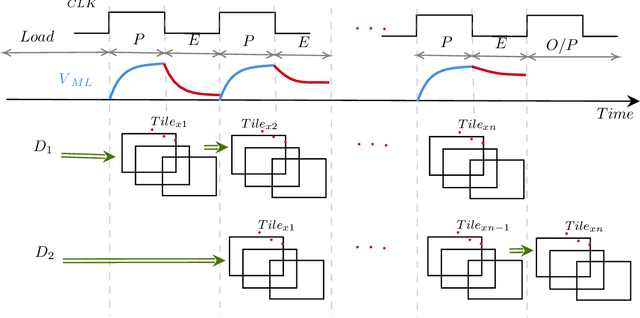
Decision trees are considered one of the most powerful tools for data classification. Accelerating the decision tree search is crucial for on-the-edge applications that have limited power and latency budget. In this paper, we propose a Content Addressable Memory (CAM) Compiler for Decision Tree (DT) inference acceleration. We propose a novel "adaptive-precision" scheme that results in a compact implementation and enables an efficient bijective mapping to Ternary Content Addressable Memories while maintaining high inference accuracies. In addition, a Resistive-CAM (ReCAM) functional synthesizer is developed for mapping the decision tree to the ReCAM and performing functional simulations for energy, latency, and accuracy evaluations. We study the decision tree accuracy under hardware non-idealities including device defects, manufacturing variability, and input encoding noise. We test our framework on various DT datasets including \textit{Give Me Some Credit}, \textit{Titanic}, and \textit{COVID-19}. Our results reveal up to {42.4\%} energy savings and up to 17.8x better energy-delay-area product compared to the state-of-art hardware accelerators, and up to 333 million decisions per sec for the pipelined implementation.