 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Hardware-Workload Co-Optimization for In-Memory Computing Accelerators
Mar 04, 2026Software-hardware co-design is essential for optimizing in-memory computing (IMC) hardware accelerators for neural networks. However, most existing optimization frameworks target a single workload, leading to highly specialized hardware designs that do not generalize well across models and applications. In contrast, practical deployment scenarios require a single IMC platform that can efficiently support multiple neural network workloads. This work presents a joint hardware-workload co-optimization framework based on an optimized evolutionary algorithm for designing generalized IMC accelerator architectures. By explicitly capturing cross-workload trade-offs rather than optimizing for a single model, the proposed approach significantly reduces the performance gap between workload-specific and generalized IMC designs. The framework is evaluated on both RRAM- and SRAM-based IMC architectures, demonstrating strong robustness and adaptability across diverse design scenarios. Compared to baseline methods, the optimized designs achieve energy-delay-area product (EDAP) reductions of up to 76.2% and 95.5% when optimizing across a small set (4 workloads) and a large set (9 workloads), respectively. The source code of the framework is available at https://github.com/OlgaKrestinskaya/JointHardwareWorkloadOptimizationIMC.
SoftmAP: Software-Hardware Co-design for Integer-Only Softmax on Associative Processors
Nov 26, 2024



Recent research efforts focus on reducing the computational and memory overheads of Large Language Models (LLMs) to make them feasible on resource-constrained devices. Despite advancements in compression techniques, non-linear operators like Softmax and Layernorm remain bottlenecks due to their sensitivity to quantization. We propose SoftmAP, a software-hardware co-design methodology that implements an integer-only low-precision Softmax using In-Memory Compute (IMC) hardware. Our method achieves up to three orders of magnitude improvement in the energy-delay product compared to A100 and RTX3090 GPUs, making LLMs more deployable without compromising performance.
Towards Efficient IMC Accelerator Design Through Joint Hardware-Workload Co-optimization
Oct 22, 2024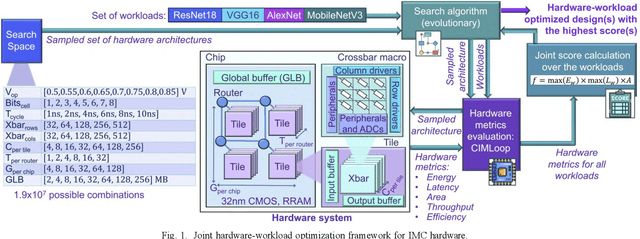
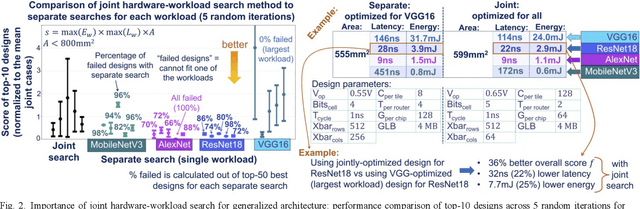
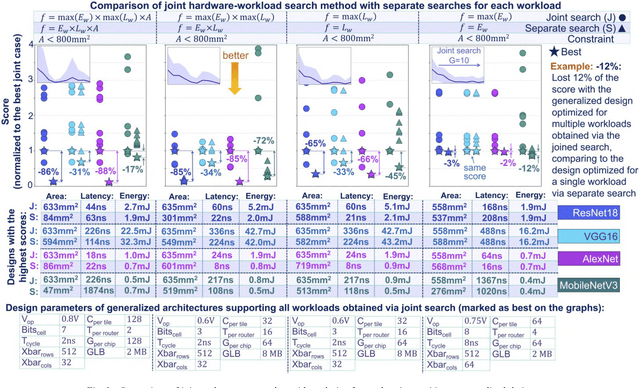
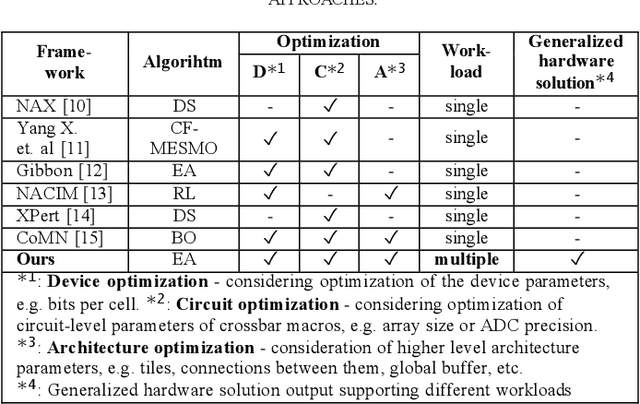
Designing generalized in-memory computing (IMC) hardware that efficiently supports a variety of workloads requires extensive design space exploration, which is infeasible to perform manually. Optimizing hardware individually for each workload or solely for the largest workload often fails to yield the most efficient generalized solutions. To address this, we propose a joint hardware-workload optimization framework that identifies optimised IMC chip architecture parameters, enabling more efficient, workload-flexible hardware. We show that joint optimization achieves 36%, 36%, 20%, and 69% better energy-latency-area scores for VGG16, ResNet18, AlexNet, and MobileNetV3, respectively, compared to the separate architecture parameters search optimizing for a single largest workload. Additionally, we quantify the performance trade-offs and losses of the resulting generalized IMC hardware compared to workload-specific IMC designs.
Low Precision Quantization-aware Training in Spiking Neural Networks with Differentiable Quantization Function
May 30, 2023Deep neural networks have been proven to be highly effective tools in various domains, yet their computational and memory costs restrict them from being widely deployed on portable devices. The recent rapid increase of edge computing devices has led to an active search for techniques to address the above-mentioned limitations of machine learning frameworks. The quantization of artificial neural networks (ANNs), which converts the full-precision synaptic weights into low-bit versions, emerged as one of the solutions. At the same time, spiking neural networks (SNNs) have become an attractive alternative to conventional ANNs due to their temporal information processing capability, energy efficiency, and high biological plausibility. Despite being driven by the same motivation, the simultaneous utilization of both concepts has yet to be thoroughly studied. Therefore, this work aims to bridge the gap between recent progress in quantized neural networks and SNNs. It presents an extensive study on the performance of the quantization function, represented as a linear combination of sigmoid functions, exploited in low-bit weight quantization in SNNs. The presented quantization function demonstrates the state-of-the-art performance on four popular benchmarks, CIFAR10-DVS, DVS128 Gesture, N-Caltech101, and N-MNIST, for binary networks (64.05\%, 95.45\%, 68.71\%, and 99.43\% respectively) with small accuracy drops and up to 31$\times$ memory savings, which outperforms existing methods.
Thermal Heating in ReRAM Crossbar Arrays: Challenges and Solutions
Dec 28, 2022Increasing popularity of deep-learning-powered applications raises the issue of vulnerability of neural networks to adversarial attacks. In other words, hardly perceptible changes in input data lead to the output error in neural network hindering their utilization in applications that involve decisions with security risks. A number of previous works have already thoroughly evaluated the most commonly used configuration - Convolutional Neural Networks (CNNs) against different types of adversarial attacks. Moreover, recent works demonstrated transferability of the some adversarial examples across different neural network models. This paper studied robustness of the new emerging models such as SpinalNet-based neural networks and Compact Convolutional Transformers (CCT) on image classification problem of CIFAR-10 dataset. Each architecture was tested against four White-box attacks and three Black-box attacks. Unlike VGG and SpinalNet models, attention-based CCT configuration demonstrated large span between strong robustness and vulnerability to adversarial examples. Eventually, the study of transferability between VGG, VGG-inspired SpinalNet and pretrained CCT 7/3x1 models was conducted. It was shown that despite high effectiveness of the attack on the certain individual model, this does not guarantee the transferability to other models.
Resistive Neural Hardware Accelerators
Sep 08, 2021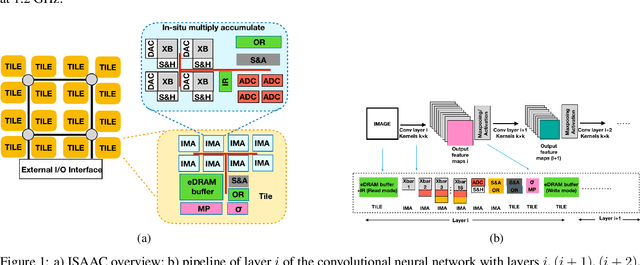
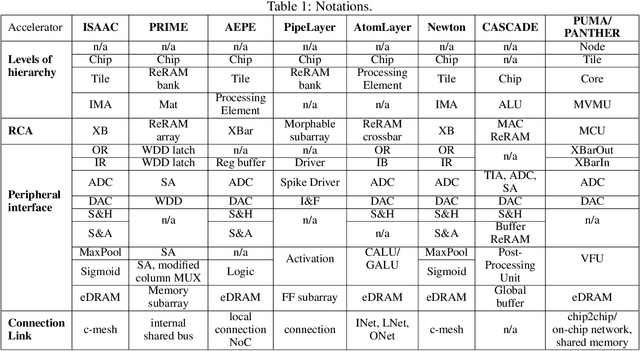
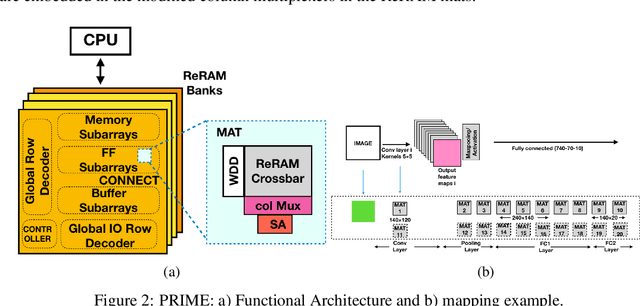
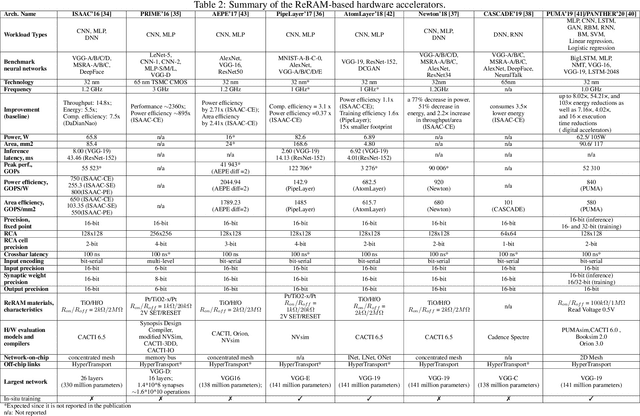
Deep Neural Networks (DNNs), as a subset of Machine Learning (ML) techniques, entail that real-world data can be learned and that decisions can be made in real-time. However, their wide adoption is hindered by a number of software and hardware limitations. The existing general-purpose hardware platforms used to accelerate DNNs are facing new challenges associated with the growing amount of data and are exponentially increasing the complexity of computations. An emerging non-volatile memory (NVM) devices and processing-in-memory (PIM) paradigm is creating a new hardware architecture generation with increased computing and storage capabilities. In particular, the shift towards ReRAM-based in-memory computing has great potential in the implementation of area and power efficient inference and in training large-scale neural network architectures. These can accelerate the process of the IoT-enabled AI technologies entering our daily life. In this survey, we review the state-of-the-art ReRAM-based DNN many-core accelerators, and their superiority compared to CMOS counterparts was shown. The review covers different aspects of hardware and software realization of DNN accelerators, their present limitations, and future prospectives. In particular, comparison of the accelerators shows the need for the introduction of new performance metrics and benchmarking standards. In addition, the major concerns regarding the efficient design of accelerators include a lack of accuracy in simulation tools for software and hardware co-design.