 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Hardware-Workload Co-Optimization for In-Memory Computing Accelerators
Mar 04, 2026Software-hardware co-design is essential for optimizing in-memory computing (IMC) hardware accelerators for neural networks. However, most existing optimization frameworks target a single workload, leading to highly specialized hardware designs that do not generalize well across models and applications. In contrast, practical deployment scenarios require a single IMC platform that can efficiently support multiple neural network workloads. This work presents a joint hardware-workload co-optimization framework based on an optimized evolutionary algorithm for designing generalized IMC accelerator architectures. By explicitly capturing cross-workload trade-offs rather than optimizing for a single model, the proposed approach significantly reduces the performance gap between workload-specific and generalized IMC designs. The framework is evaluated on both RRAM- and SRAM-based IMC architectures, demonstrating strong robustness and adaptability across diverse design scenarios. Compared to baseline methods, the optimized designs achieve energy-delay-area product (EDAP) reductions of up to 76.2% and 95.5% when optimizing across a small set (4 workloads) and a large set (9 workloads), respectively. The source code of the framework is available at https://github.com/OlgaKrestinskaya/JointHardwareWorkloadOptimizationIMC.
Towards Efficient IMC Accelerator Design Through Joint Hardware-Workload Co-optimization
Oct 22, 2024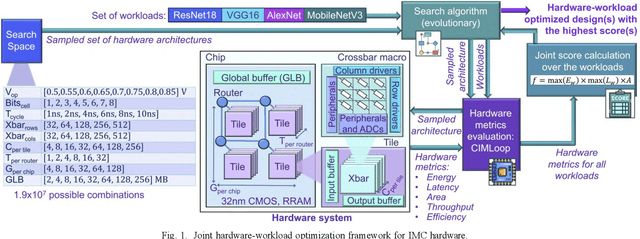
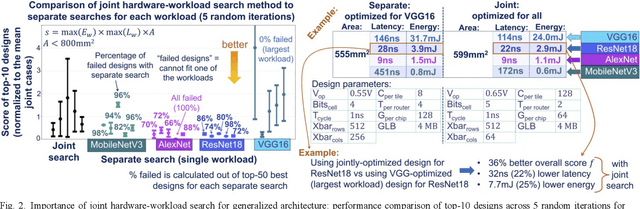
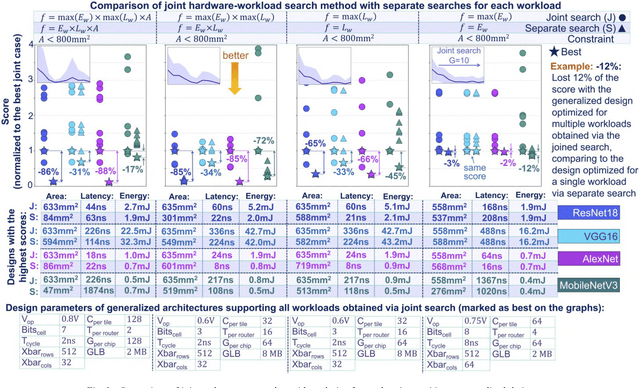
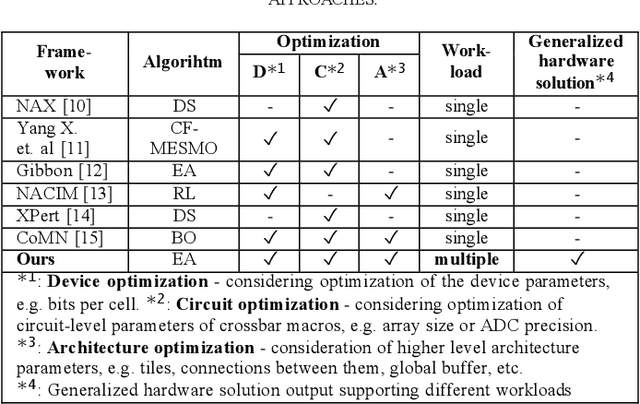
Designing generalized in-memory computing (IMC) hardware that efficiently supports a variety of workloads requires extensive design space exploration, which is infeasible to perform manually. Optimizing hardware individually for each workload or solely for the largest workload often fails to yield the most efficient generalized solutions. To address this, we propose a joint hardware-workload optimization framework that identifies optimised IMC chip architecture parameters, enabling more efficient, workload-flexible hardware. We show that joint optimization achieves 36%, 36%, 20%, and 69% better energy-latency-area scores for VGG16, ResNet18, AlexNet, and MobileNetV3, respectively, compared to the separate architecture parameters search optimizing for a single largest workload. Additionally, we quantify the performance trade-offs and losses of the resulting generalized IMC hardware compared to workload-specific IMC designs.
BackLink: Supervised Local Training with Backward Links
May 14, 2022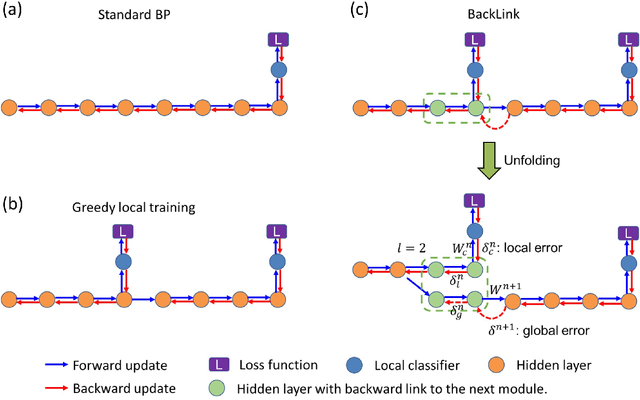
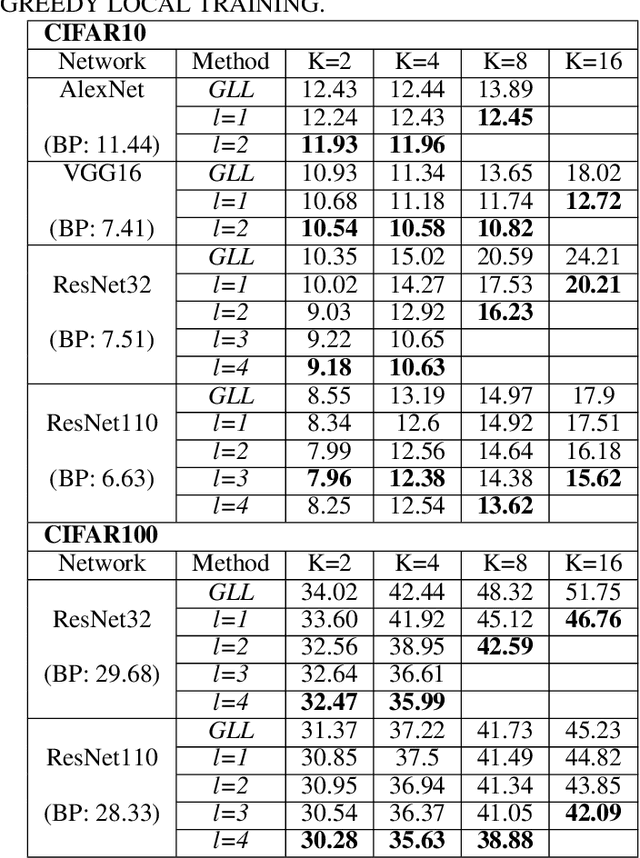
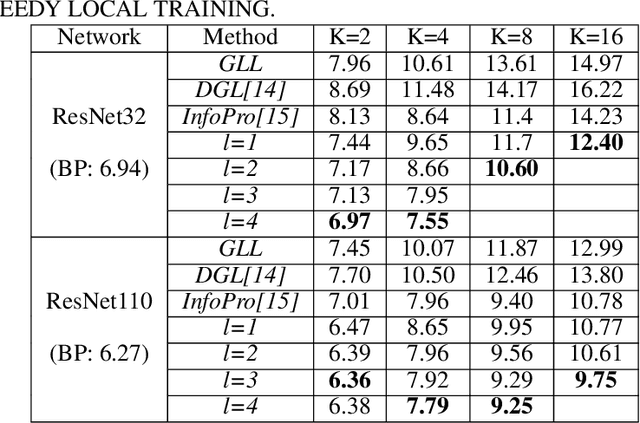
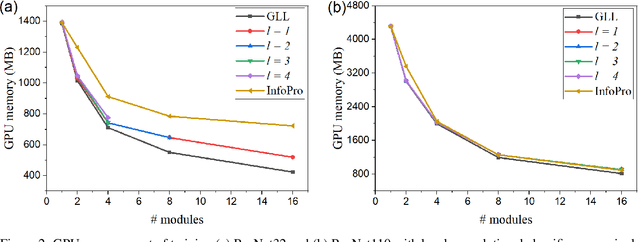
Empowered by the backpropagation (BP) algorithm, deep neural networks have dominated the race in solving various cognitive tasks. The restricted training pattern in the standard BP requires end-to-end error propagation, causing large memory cost and prohibiting model parallelization. Existing local training methods aim to resolve the training obstacle by completely cutting off the backward path between modules and isolating their gradients to reduce memory cost and accelerate the training process. These methods prevent errors from flowing between modules and hence information exchange, resulting in inferior performance. This work proposes a novel local training algorithm, BackLink, which introduces inter-module backward dependency and allows errors to flow between modules. The algorithm facilitates information to flow backward along with the network. To preserve the computational advantage of local training, BackLink restricts the error propagation length within the module. Extensive experiments performed in various deep convolutional neural networks demonstrate that our method consistently improves the classification performance of local training algorithms over other methods. For example, in ResNet32 with 16 local modules, our method surpasses the conventional greedy local training method by 4.00\% and a recent work by 1.83\% in accuracy on CIFAR10, respectively. Analysis of computational costs reveals that small overheads are incurred in GPU memory costs and runtime on multiple GPUs. Our method can lead up to a 79\% reduction in memory cost and 52\% in simulation runtime in ResNet110 compared to the standard BP. Therefore, our method could create new opportunities for improving training algorithms towards better efficiency and biological plausibility.