 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA System Level Performance Evaluation for Superconducting Digital Systems
Nov 13, 2024



Superconducting Digital (SCD) technology offers significant potential for enhancing the performance of next generation large scale compute workloads. By leveraging advanced lithography and a 300 mm platform, SCD devices can reduce energy consumption and boost computational power. This paper presents a cross-layer modeling approach to evaluate the system-level performance benefits of SCD architectures for Large Language Model (LLM) training and inference. Our findings, based on experimental data and Pulse Conserving Logic (PCL) design principles, demonstrate substantial performance gain in both training and inference. We are, thus, able to convincingly show that the SCD technology can address memory and interconnect limitations of present day solutions for next-generation compute systems.
* 8 figures
Performance Modeling and Workload Analysis of Distributed Large Language Model Training and Inference
Jul 19, 2024



Aligning future system design with the ever-increasing compute needs of large language models (LLMs) is undoubtedly an important problem in today's world. Here, we propose a general performance modeling methodology and workload analysis of distributed LLM training and inference through an analytical framework that accurately considers compute, memory sub-system, network, and various parallelization strategies (model parallel, data parallel, pipeline parallel, and sequence parallel). We validate our performance predictions with published data from literature and relevant industry vendors (e.g., NVIDIA). For distributed training, we investigate the memory footprint of LLMs for different activation re-computation methods, dissect the key factors behind the massive performance gain from A100 to B200 ($\sim$ 35x speed-up closely following NVIDIA's scaling trend), and further run a design space exploration at different technology nodes (12 nm to 1 nm) to study the impact of logic, memory, and network scaling on the performance. For inference, we analyze the compute versus memory boundedness of different operations at a matrix-multiply level for different GPU systems and further explore the impact of DRAM memory technology scaling on inference latency. Utilizing our modeling framework, we reveal the evolution of performance bottlenecks for both LLM training and inference with technology scaling, thus, providing insights to design future systems for LLM training and inference.
BackLink: Supervised Local Training with Backward Links
May 14, 2022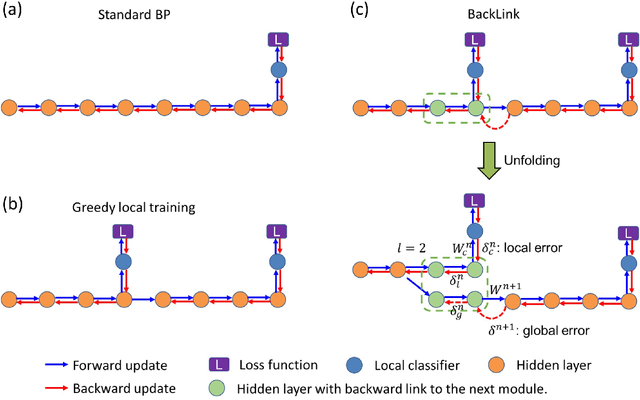
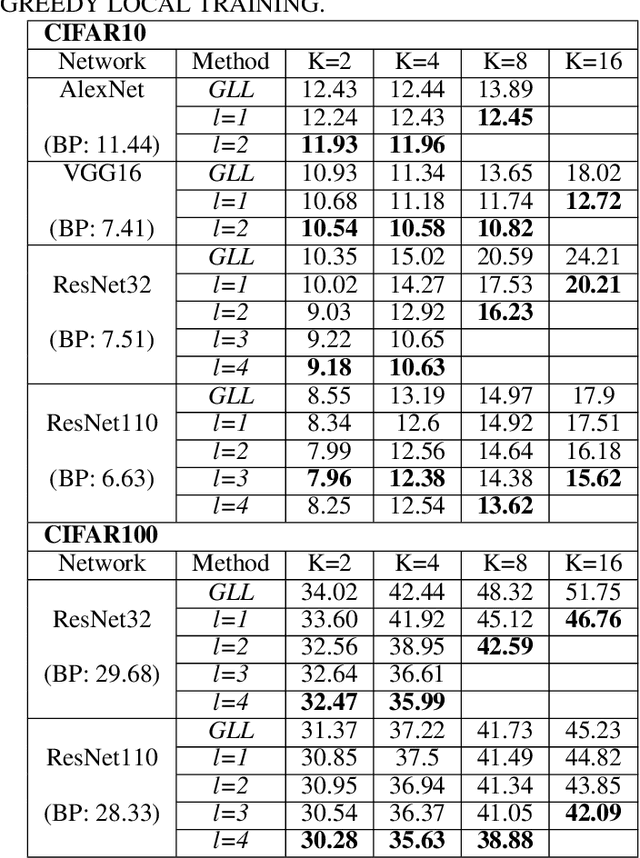
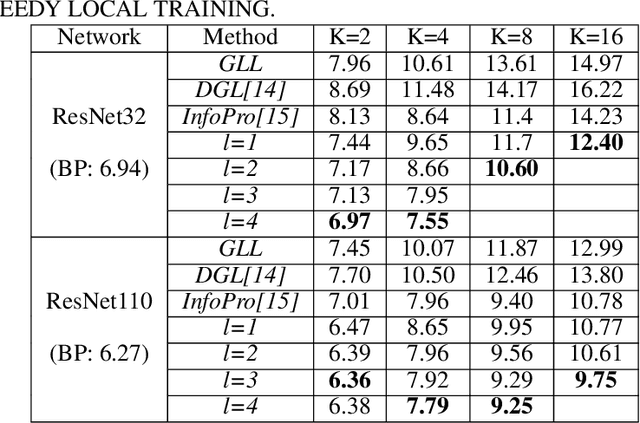
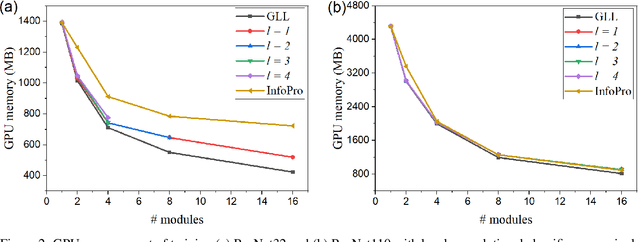
Empowered by the backpropagation (BP) algorithm, deep neural networks have dominated the race in solving various cognitive tasks. The restricted training pattern in the standard BP requires end-to-end error propagation, causing large memory cost and prohibiting model parallelization. Existing local training methods aim to resolve the training obstacle by completely cutting off the backward path between modules and isolating their gradients to reduce memory cost and accelerate the training process. These methods prevent errors from flowing between modules and hence information exchange, resulting in inferior performance. This work proposes a novel local training algorithm, BackLink, which introduces inter-module backward dependency and allows errors to flow between modules. The algorithm facilitates information to flow backward along with the network. To preserve the computational advantage of local training, BackLink restricts the error propagation length within the module. Extensive experiments performed in various deep convolutional neural networks demonstrate that our method consistently improves the classification performance of local training algorithms over other methods. For example, in ResNet32 with 16 local modules, our method surpasses the conventional greedy local training method by 4.00\% and a recent work by 1.83\% in accuracy on CIFAR10, respectively. Analysis of computational costs reveals that small overheads are incurred in GPU memory costs and runtime on multiple GPUs. Our method can lead up to a 79\% reduction in memory cost and 52\% in simulation runtime in ResNet110 compared to the standard BP. Therefore, our method could create new opportunities for improving training algorithms towards better efficiency and biological plausibility.